







自旋锁直接调用了boost库的#include <boost/smart_ptr/detail/spinlock.hpp>
测试线程并发的情况下耗时,不太明白为什么boost的spinlock效率这么低,还是说boost的spinlock是有其它专业用途...
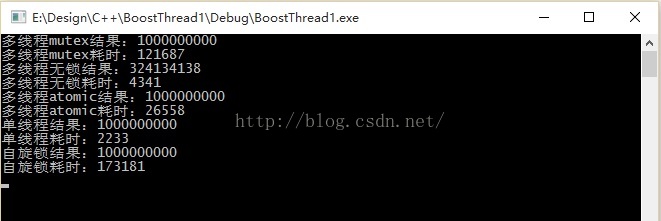
在一个共有资源的情况下,
由于任务的简单性,只是++,单线程最快
多线程无锁次之,但是结果错误
atomic原子操作耗时稍长,但由于原子操作的关系,结果正确
mutex 性能损失比较大,为atomic的4倍左右,虽然保证了结果的正确性,但是耗时却是原来的10多倍
boost spinlock效率垫底了,不太明白细节,等下研究一下
是锁竞争的关系?还是内核态和用户态切换的关系?
请明白的大神指点
不过有一点给自己提了个醒,在不了解锁机制的情况下还是得慎用
下面是代码:
// BoostThread1.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <boost/lambda/lambda.hpp>
#include <iostream>
#include <iterator>
#include <algorithm>
#include <boost/thread/thread.hpp>
#include <boost/atomic.hpp>
#include <boost/smart_ptr/detail/spinlock.hpp>
#include "time.h"
//在一个共有资源的情况下,
//由于任务的简单性,只是++,单线程最快
//多线程无锁次之,但是结果错误
//atomic原子操作耗时稍长,但由于原子操作的关系,结果正确
//mutex 性能损失比较大,为atomic的4倍左右,虽然保证了结果的正确性,但是耗时却是原来的10多倍
//boost spinlock效率垫底了,不太明白细节,等下研究一下
//是锁竞争的关系?还是内核态和用户态切换的关系?
//请明白的大神指点
//不过有一点给自己提了个醒,在不了解锁机制的情况下还是得慎用
long total = 0;
boost::atomic_long total2(0);
boost::mutex m;
boost::detail::spinlock sp;
void thread_click()
{
for (int i = 0; i < 10000000; ++i)
{
++total;
}
}
void mutex_click()
{
for (int i = 0; i < 10000000 ; ++i)
{
m.lock();
++total;
m.unlock();
}
}
void atomic_click()
{
for (int i = 0; i < 10000000; ++i)
{
++total2;
}
}
void spinlock_click()
{
for (int i = 0; i < 10000000; ++i)
{
boost::lock_guard<boost::detail::spinlock> lock(sp);
++total;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int thnum = 100;
clock_t start = clock();
boost::thread_group threads;
for (int i = 0; i < thnum;++i)
{
threads.create_thread(mutex_click);
}
threads.join_all();
//计时结束
clock_t end = clock();
std::cout << "多线程mutex结果:" << total << std::endl;
std::cout << "多线程mutex耗时:" << end - start << std::endl;
total = 0;
start = clock();
for (int i = 0; i < thnum; ++i)
{
threads.create_thread(thread_click);
}
threads.join_all();
end = clock();
std::cout << "多线程无锁结果:" << total << std::endl;
std::cout << "多线程无锁耗时:" << end - start << std::endl;
total = 0;
start = clock();
for (int i = 0; i < thnum; ++i)
{
threads.create_thread(atomic_click);
}
threads.join_all();
end = clock();
std::cout << "多线程atomic结果:" << total2 << std::endl;
std::cout << "多线程atomic耗时:" << end - start << std::endl;
total = 0;
start = clock();
for (int i = 0; i < 10000000*thnum;i++)
{
++total;
}
end = clock();
std::cout << "单线程结果:" << total << std::endl;
std::cout << "单线程耗时:" << end - start << std::endl;
total = 0;
start = clock();
for (int i = 0; i < thnum; ++i)
{
threads.create_thread(spinlock_click);
}
threads.join_all();
end = clock();
std::cout << "自旋锁结果:" << total << std::endl;
std::cout << "自旋锁耗时:" << end - start << std::endl;
getchar();
return 0;
}
上图















 4015
4015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









