







说明:个人学习笔记,学习内容主要来自廖雪峰Python2.7教程:http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/
输入输出问题
输入输出当然是任何一个变成语言最基本的语句,任何编程都是要与用户交互的。
- print输出
>>> print 'Hello World'
Hello World- 输出格式化字符串
>>> 'Hello, %s' %'world'
'Hello,world'
>>> 'Hi, %s, you have $%d.' %('Michael',1000000)
'Hi,Michael,you have $1000000'- raw_input
>>> name = raw_input('please enter your name:')
>>> print 'Hello,',name
% execute result
C:\Workspace > python hello.py
please enter your name: Michael
hello,Michael 注意:raw_input返回类型总为字符串,如果想要输入’123’,结果也为整数123,则需要int(raw_input())
字符编码问题
计算机能够处理的都是0,1串,所以如果要处理文本,需要将文本转换为数字,这是任何一种编程语言中都是要用到的,只是学习语言之初忽略了这个问题,在此补充学习。
由于计算机是美国人发明的,因此最早只有127个字母被编码到计算机中,也就是大小写英文字母、数字和一些符号,这个编码就是我们熟悉的ASCII编码。
之后,中国制定了GB2312编码,把中文进行编码,同时也不与ASCII码冲突;同样的其他国家也这么做了,日本制定了shift_JIS对日文进行编码,韩国制定了Euc-kr对韩文进行编码,各国有各国的标准,就不可避免地会出现冲突,因此在多语言混合的文本中,显示会有乱码现象。
Unicode应运而生,Unicode将所有语言都统一到一套编码中,最常用的是用两个字节表示一个字符,现代操作系统和大多数编程语言都直接支持Unicode。
如果统一成Unicode编码,乱码问题从此消失了,但是,如果你写的文本基本全部是英文的,用Unicode编码比用ASCII编码需要多一倍的存储空间,在存储和运输上变得十分不划算。
因此又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。
UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码为1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 0000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上表可以看出,ASCII编码实际上可以看作UTF-8编码的一部分,所以大量支持ASCII编码的历史遗留软件,可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8编码的关系,下面总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码
记事本的编码工作方式
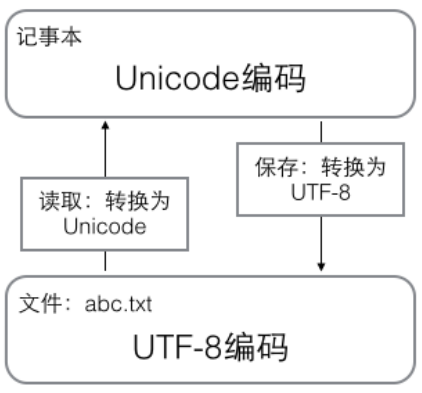
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符放到内存中;编辑完成后,将Unicode编码转换为UTF-8编码保存到文件中。
浏览网页时的编码工作方式
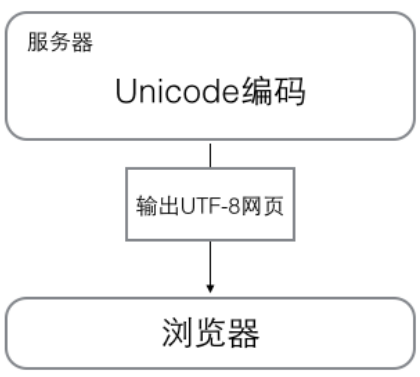
浏览网页的之后,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器,查看浏览器源码时,看到类似<meta charset = "UTF-8" />的信息,则表示该网页正是用UTF-8进行编码的。
Python对编码方式的支持
Python的诞生比Unicode标准发布的还要早,所以最早的Python只支持ASCII编码。
只有添加了对Unicode的支持,用u'...'表示用Unicode编码的字符串。
将Unicode编码字符转换为UTF-8类型,用encode('utf-8'):
>>> u'ABC'.encode('utf-8')
'ABC'将UTF-8类型编码转为Unicode编码,用decode('utf-8'):
>>> 'abc'.decode('utf-8')
u'abc'用于Python源代码也是一个文本文件,所以,在保存源代码的时候,如果你的源码中包含中文,就务必指定保存为UTF-8编码。
当Python解释器读取源代码时,为了让它按照UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python
# -*- coding: utf-8 -*-- 第一行注释:告诉Linux/OS X 系统,这是一个python可执行程序,Windows系统会忽略这个注释
- 第二行注释:告诉Python解释器,按照UTF-8编码读取源码(否则,你在源码中写的中文输出可能会有乱码)
Python解释器
了解语言的运行机制,对于理解语言的工作方式还是挺重要的。
当我们编写Python代码时,得到的是一个以.py为扩展名的文本文件,要运行代码,就需要Python解释器去执行.py文件。
CPython
当我们从Python官方网站下载并安装好Python2.7后,就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动 CPython解释器。IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意,不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行, 但是PyPy和CPython有一些是不同的, 这就导致相同的Python代码在两
种解释器下执行可能会有不同的结果。 如果你的代码要放到PyPy下执行, 就需要了解PyPy和CPython的不同点。Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









