







本文介绍和结构体结合的指针的用法。结尾有一道比较绕的题目,看看读者是否能理解消化。
结构声明
最容易理解的结构体声明方法;
struct
{
int a;
char b;
float c;
} x;
struct
{
int a;
char b;
float c;
} y[20],*p;
这段代码,声明了一个结构体变量 x;
一个结构体数组y,这个结构体数组的元素有20个,可以通过下标访问,每个元素都是同类型的结构体;
一个指向结构体的指针,但是该指针没有初始化。
结构体也是变量,所以声明的时候也需要指明 变量类型 变量名称,以及必要的初始化。
注意
p= &x;
上述变量声明被编译器当作两种截然不同的类型,即使它们的成员列表完全相同。因此,变量y 和p的类型和x的类型不同,所以下面这条语句 是非法的。
但是,这是不是意味着某种特定类型的所有结构都必须使用一个单独的声明来 创建呢? 幸运的是,事实并非如此。标签(tag)字段允许为成员列表提供一个名字,这样 它就可以在后续的声明中使用。标签允许多个声明使用同一个成员列表,并且创建 同一种类型的结构。
struct SIMPLE
{
int a;
char b;
float c;
};
这个声明把标签SIMPLE和这个成员列表联系在一起。该声明并没有提供变量列 表,所以它并未创建任何变量这个声明类似于制造一个模具。模具定制造出来的甜饼的形 状,但模具本身却不是甜饼。标签标识了一种模式,用于声明未来的变量, 但无论是标签还是模式本身都不是变量。
struct SIMPLE x;
struct SIMPLE y[20],*p;
这些声明使用标签来创建变量。它们创建和最初两个例子一样的变量,但存在 一个重要的区别——现在x、y和z都是同一种类型的结构变量。因为他们具有同种标签
声明结构时可以使用的另一种良好技巧是用typedef创建一种新的类型,如下 面的例子所示。
typedef struct {
int a;
float b;
char c;
} simple;这个技巧和声明一个结构标签的效果几乎相同。区别在于Simple现在是个类型 名而不是个结构标签,所以后续的声明可能像下面这个样子:
Simple x;
Simple y[20], *z;如果你想在多个源文件中使用同一种类型的结构,你应该把标签声明或typedef形式的声明 放在一个头文件中。当源文件需要这个声明时可以使用#include指令把那个头文件包含进来。
结构的自引用
在一个结构内部包含一个类型为该结构本身的成员是否合法呢?这里有一个例 子,可以说明这个想法。
struct SEF_REF1 {
int a;
struct SEF_REF1 b;
int c;
};这种类型的自引用是非法的,因为成员b是另一个完整的结构,其内部还将包含 它自己的成员b。这第2个成员又是另一个完整的结构,它还将包括它自己的成员b。 这样重复下去永无止境。这有点像永远不会终止的递归程序。
但下面这个声明却是 合法的,你能看出其中的区别吗
struct SEF_REF2 {
int a;
struct SEF_REF2* b;
int c;
};这个声明和前面那个声明的区别在于b现在是一个指针而不是结构。编译器在结 构的长度确定之前就已经知道指针的长度,所以这种类型的自引用是合法的。 如果你觉得一个结构内部包含一个指向该结构本身的指针有些奇怪,请记住它 事实上所指向的是同一种类型的不同结构。更加高级的数据结构,如链表和树,都 是用这种技巧实现的。每个结构指向链表的下一个元素或树的下一个分枝。
警惕下面这个陷阱:
typedef struct {
int a;
REFENCE* b;
int c;
}REFENCE;这个声明的目的是为这个结构创建类型名SELF_REF3。但是,它失败了。类型名直到声明的末尾才定义, 所以在结构声明的内部它尚未定义。
解决方案是定义一个结构标签来声明b,如下所示:
typedef struct REFENCE_TAG {
int a;
struct REFENCE_TAG* b;
int c;
}REFENCE;结构的存储分配
结构在内存中是如何实际存储的呢?编译器按照成员列表的顺序一个接 一个地给每个成员分配内存。只有当存储成员时需要满足正确的边界对齐要求时, 成员之间才可能出现用于填充的额外内存空间。 为了说明这一点,考虑下面这个结构体:
struct ALIGN {
char a;
int b;
char c;
};
如果某个机器的整型值长度为4个字节,并且它的起始存储位置必须能够被4整 除,那么这一个结构在内存中的存储将如下所示:

系统禁止编译器在一个结构的起始位置跳过几个字节来满足边界对齐要求,因 此所有结构的起始存储位置必须是结构中边界要求最严格的数据类型所要求的位 置。
因此,成员a(最左边的那个方框)必须存储于一个能够被4整除的地址。结构 的下一个成员是一个整型值,所以它必须跳过3个字节(用灰色显示)到达合适的边 界才能存储。在整型值之后是最后一个字符。 如果声明了相同类型的第2个变量,它的起始存储位置也必须满足4这个边界, 所以第1个结构的后面还要再跳过3个字节才能存储第2个结构。
因此,每个结构将占 据12个字节的内存空间但实际只使用其中的6个,这个利用率可不是很出色。 你可以在声明中对结构的成员列表重新排列,让那些对边界要求最严格的成员 首先出现,对边界要求最弱的成员最后出现。这种做法可以最大限度地减少因边界 对齐而带来的空间损失。
例如,下面这个结构体
struct ALIGN2 {
int b;
char a;
char c;
};所包含的成员和前面那个结构一样,但它只占用8个字节的空间,节省了33%。 两个字符可以紧挨着存储,所以只有结构最后面需要跳过的两个字节才被浪费。
结构和指针和成员
直接或通过指针访问结构和它们的成员的操作符是相当简单的,但是当它们应 用于复杂的情形时就有可能引起混淆。这里有几个例子,能帮助你更好地理解这两 个操作符的工作过程。这些例子使用了下面的声明。
typedef struct {
int a;
short b[2];
}Ex2;
typedef struct EX {
int a;
char b[3];
Ex2 c;
struct EX* d;
}Ex;
Ex x = { 10, "Hi", { 5, { -1, 25 } }, 0 };
Ex* px = &x;Ex这个结构体类型,包括了四个变量,其中有一个是Ex2类型的结构体,一个是指向Ex结构体类型的结构体指针。
用图的形式来表示结构,使这些例子看上去更清楚一些。
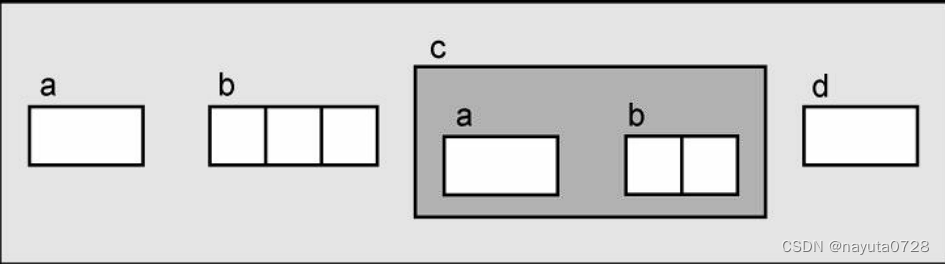
px是一个指向Ex 类型的结构体指针,此时它指向了x结构体。
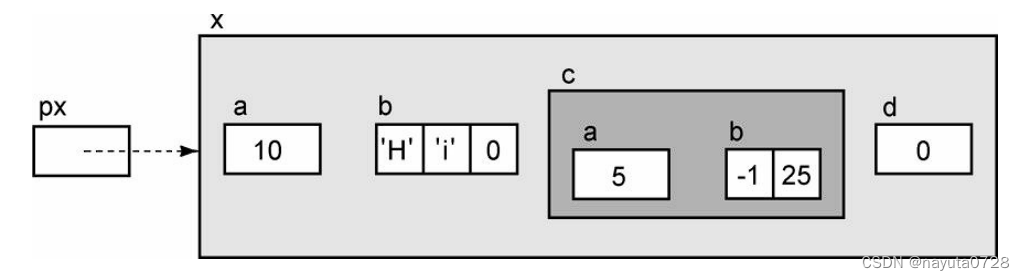
我们可以使用*操作符对指针执行间接访问。表达式*px的右值是px所指向的整 个结构。 间接访问操作随箭头访问结构,其结果就是整个结构。你 可以把这个表达式赋值给另一个类型相同的结构,你也可以把它作为点操作符的左 操作数,访问一个指定的成员。你也可以把它作为参数传递给函数,也可以把它作 为函数的返回值返回
例如:
Ex z = *px;
int p = px->a;
char text[2];
char text[2] = (*px).b[1];
struct EX* p = px->d;
在此,相互比较一下表达式*px和px->a。在这两个表达式中, px所保存的地址都用于寻找这个结构。
但结构的第1个成员是a,所以a的地址和结构体的地址是一样的。
这样px看上去是指向整个结构,同时指向结构的第1个成员:毕 竟,它们具有相同的地址。但是,这个分析只有一半是正确的。
尽管两个地址的值 是相等的,但它们的类型不同。变量px被声明为一个指向结构的指针,所以表达式 *px的结果是整个结构,而不是它的第1个成员。
为了访问本身也是结构的成员c,我们可以使用表达式px->c。它的左值是整个 结构。 这个表达式可以使用点操作符访问c的特定成员。例如,表达式px->c.这个表达式既包含了点操作符,也包含了箭头操作符。
之所以使用箭头操作 符,是因为px并不是一个结构,而是一个指向结构的指针。
接下来之所以要使用点 操作符是因为px->c的结果并不是一个指针,而是一个结构。
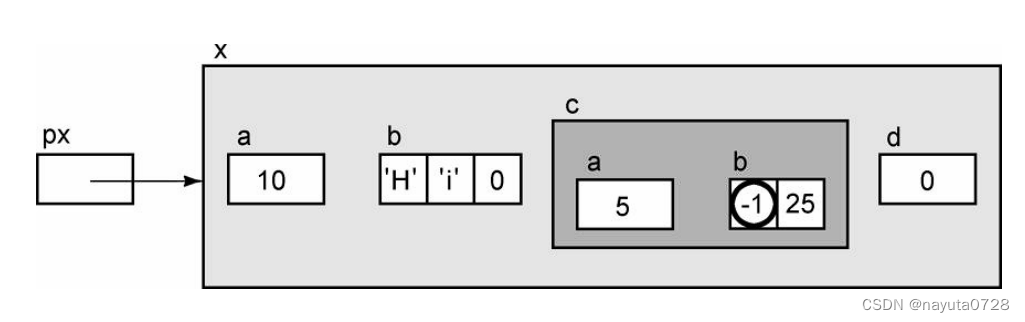
这里有一个更为复杂的表达式: *px->c.b 如果你逐步对它进行分析,这个表达式还是比较容易弄懂的。
它有三个操作 符,首先执行的是箭头操作符。
px->c的结果是结构c。在表达式中增加.b访问结构 c的成员b。b是一个数组,所以px->b.c的结果是一个(常量)指针,它指向数组的 第1个元素。
最后对这个指针执行间接访问,所以表达式的最终结果是数组的第1个 元素。这个表达式可以图解如下
结构体中的指针成员:
表达式px->d的结果正如你所料——它的右值是0,它的左值是它本身的内存位 置。表达式*px->d更为有趣。这里间接访问操作符作用于成员d所存储的指针值。 但d包含了一个NULL指针,所以它不指向任何东西。对一个NULL指针进行解引用操 作是个错误
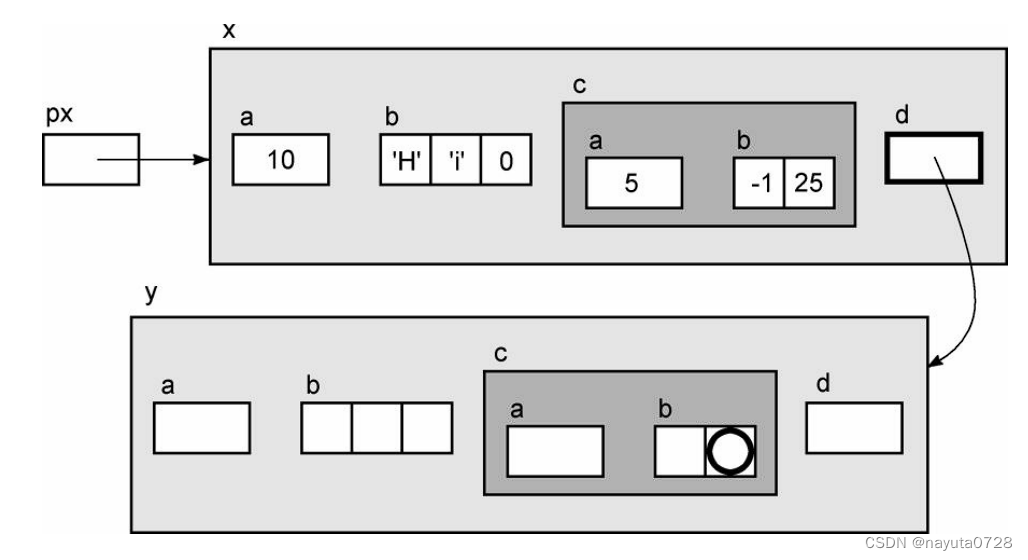
进一步,让我们创建另一个结构,并把x.d设置为指向它。
Ex y;
x.d = &y;现在我们可以对表达式*px->d求值。
成员d指向一个结构,所以对它执行间接访问操作的结果是整个结构。
但是这个新的 结构并没有显式地初始化, 正如你可能预料的那样,这个新结构的成员可以通过在表达式中增加更多的操作符进行访问。我们使用箭头操作符,因为d是一个指向结构的指针。
比如:
px->d->a
px->d->b
px->d->c
px->d->c.a
px->d->c.b[1]
最后一个表达式的值可用图表示。
总结:
在结构中,不同类型的值可以存储在一起。结构中的值称为成员,它们是通过 名字访问的。
结构变量是一个标量,可以出现在普通标量变量可以出现的任何场 合。 结构的声明列出了结构包含的成员列表。
不同的结构声明即使它们的成员列表 相同也被认为是不同的类型。
结构标签是一个名字,它与一个成员列表相关联。你 可以使用结构标签在不同的声明中创建相同类型的结构变量,这样就不用每次在声 明中重复成员列表。typedef也可以用于实现这个目标。
结构的成员可以是标量、数组或指针。结构也可以包含本身也是结构的成员。
在不同的结构中出现同样的成员名是不会引起冲突的。你使用点操作符访问结构变 量的成员。如果你拥有一个指向结构的指针,你可以使用箭头操作符访问这个结构 的成员。
结构不能包含类型也是这个结构的成员,但它的成员可以是一个指向这个结构 的指针。这个技巧常常用于链式数据结构中。
为了声明两个结构,每个结构都包含 一个指向对方的指针的成员,我们需要使用不完整的声明来定义一个结构标签名。 结构变量可以用一个由花括号包围的值列表进行初始化。这些值的类型必须适合它 所初始化的那些成员。
编译器为一个结构变量的成员分配内存时要满足它们的边界对齐要求。在实现 结构存储的边界对齐时,可能会浪费一部分内存空间。根据边界对齐要求降序排列 结构成员可以最大限度地减少结构存储中浪费的内存空间。sizeof返回的值包含了 结构中浪费的内存空间。
结构可以作为参数传递给函数,也可以作为返回值从函数返回。但是,向函数 传递一个指向结构的指针往往效率更高。在结构指针参数的声明中可以加上const关 键字防止函数修改指针所指向的结构。
思考题:
考虑下面这些声明和数据
考虑下面这些声明和数据
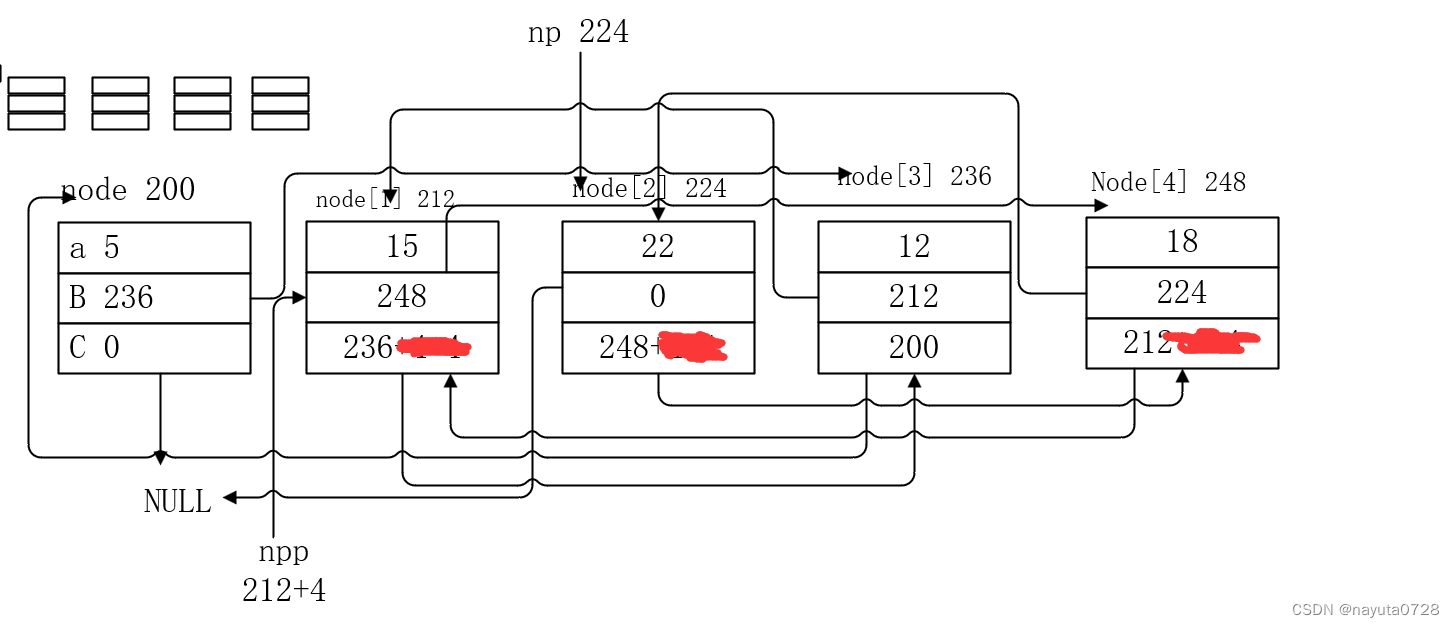
struct NODE {
int a;
struct NODE* b;
struct NODE* c;
};
struct NODE nodes[5] =
{
{5, nodes + 3, NULL},
{15,nodes + 4,nodes + 3},
{22,NULL,nodes + 4},
{12,nodes + 1,nodes},
{18,nodes + 2,nodes + 1}
};
struct NODE* np = nodes + 2;
struct NODE** npp = &nodes[1].b;对下面每个表达式求值,并写出它的值。同时,写明任何表达式求值过程中可 能出现的副作用。你应该用最初显示的值对每个表达式求值(也就是说,不要使用 某个表达式的结果来对下一个表达式求值)。假定nodes数组在内存中的起始位置为 200,并且在这台机器上整数和指针的长度都是4个字节。
例如:
表达式:nodes 的值是数组的起始地址,即 200
为了便于理解,我画出了结构图:
对下面每个表达式求值:
nodes
&nodes[3].c-a
nodes.a
&nodes-a
nodes[3].a
np
nodes[3].c
np->a
nodes[3].c->a
np->c->c->a
*nodes
npp
*nodes.a
npp->a
(*nodes).a
*npp
nodes->a
**npp
nodes[3].b->b
*npp->a
*nodes[3].b->b
(*npp)->a
&nodes
&np
&nodes[3].a
&np->a
&nodes[3].c
&np->c->c->a
解答:
nodes的值是数组的起始地址,即200。&nodes[3].c - a&nodes[3].c的地址减去a的值。&nodes[3].c的地址是200 + 3 * 12 + 8 = 236,因为每个NODE结构体占用12字节(int占4字节,两个指针各占4字节),所以第三个NODE的起始地址是200 + 3 * 12,c成员是在8字节偏移处。但是 并没有单独的变量a ,变量a存在于结构体中,使用需用点操作符或者-> 因此这个表达式非法,无意义。nodes.a是非法的,因为nodes是一个结构体数组的首地址,我们不能直接访问a。我们需要指定数组的索引,例如nodes[0].a。&nodes - a也是非法的,因为&nodes是一个指向结构体数组的指针,但是并没有单独的变量a ,变量a存在于结构体中,使用需用点操作符或者->操作符nodes[3].a的值是12,因为它是node[3]结构体中a成员的值。np的值是node + 2的地址,即200 + 2 * 12 = 224。nodes[3].c的值是node的地址,因为node[3].c指向node。np->a的值是22,因为np指向node[2],而node[2].a的值是22。
nodes[3].c->a的值是node[0].a,即5。np->c->c->a的值是node[1].a,即15。*nodes是node[0]的另一种表示方法,其值是{5, node + 3, NULL}。npp的值是&node[1].b的地址,即200 + 1 * 12 + 4 = 216。*nodes.a是非法的,因为nodes是一个数组,我们不能直接访问a。我们需要指定数组的索引,例如(*nodes).a。npp->a是非法的,因为npp是一个指向struct NODE*的指针的指针。我们需要解引用一次才能访问a,例如(*npp)->a。(*nodes).a的值是node[0].a,即5。*npp的值是node[1].b的地址,即node + 4,也就是200 + 4 * 12 = 248。nodes->a是node[0].a的另一种表示方法,其值是5。**npp的值是node[4],即18,224,212。nodes[3].b->b的值是node[1].b,即node + 4 ,248。*npp->a是非法的,->的优先级更高,npp是一个指向struct NODE*的指针的指针。我们需要解引用一次才能访问a,例如(*npp)->a。*nodes[3].b->b:nodes[3].b是node[3].b的值,即node + 1。所以nodes[3].b->b是node[1].b的值,即node + 4。因此,*nodes[3].b->b是node[4].a的值,即18。(*npp)->a的值是node[4].a,即18。&nodes的值是数组的地址,即200。&np的值是np变量的地址,这个地址是编译时分配的,我们无法确定具体的数值。&nodes[3].a的值是200 + 3 * 12 = 236。&np->a的值是224,因为np指向node[2],而node[2].a的地址是224。&nodes[3].c的值是236 + 8 = 244。。-
首先,
np是指向node[2]的指针,所以np->c是node[2].c,即node + 4。然后,(np->c)->c是node[4].c,即node + 1。最后,&(np->c->c->a)是node[1].a的地址。由于
node数组的起始地址是200,并且每个NODE结构体占用12字节(int占4字节,两个指针各占4字节),node[1].a的地址可以这样计算:node[1].a 的地址 = 起始地址 + (结构体索引 * 结构体大小) + a 成员的偏移量 = 200 + (1 * 12) + 0 = 212所以,表达式
&np->c->c->a的值是212。















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









