







前几天有人问千哥,汇编语言(王爽第四版)实验七,实在是太难了,应该怎么才能完成这个实验。千哥虽然一直在做产业投资,但对于汇编语言还是非常熟的。

我看了一下,其实这个实验要说难也难,说不难也不难,关键是怎么捋清解题的思路。
先看看这个实验,王爽老师给出的基本的代码:
=========这是代码与内容的分割线==========
assume cs:codesg
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21年字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
=========这是代码与内容的分割线==========
这个实验,说的是有一家叫Power idea的美国公司,从1975年到1995年的收入情况和雇员情况。
在data这个数据段中,用db(字节型)定义了21个字符串,分别代表1975年至1995年;用dd(双字型)定义了21个dword型数据,从16到5937000,代表这家公司21年的收入;用dw(字型)定义了21个word型数据,代表这家公司21年的雇员人数。
现在要求,将data段中的数据按如下格式写入到table段中,并计算21年中的人均收入(取整),结果也要按照下面的格式保存在table段中。

像这类涉及数据存储的问题,用一些高级语言+关系数据库是很容易解决的,都有现成的语法和接口作为支撑。
但在汇编语言下,特别是像这个实验的要求,相关数据是临时存储在内存单元里的,难度就相对大一些。在解题之前,首先要思考的是以下几个问题:
1、在data段中,涉及到的三组数据(年份、收入、雇员人数),一旦经过程序的运行,是存放在哪些内存单元中的。
2、在table段中,使用db 21 dup ('year summ ne ?? ')这个语句,会开辟21个连续的数据空间,每个数据空间在内存中以字符串“year summ ne ??”表示;在data段中的三组数据要存入到table段中,在程序运行过程中,data段一般可以用ds这个寄存器+偏移地址来寻址,那么table段,又应该用什么寄存器来寻址?
3、根据题设,“年份”这组数据,定义的是db类型(字节型),每一个年份,比如“1975”占了4个字节;“收入”这组数据,定义的是dd(双字型),每一个数字,比如“16”占了4个字节;“雇员人数”,定义的是dw(字型),每一个数据,比如“3”占了2个字节。
在设计循环体的时候,如果用同一个寄存器来作为偏移量进行寻址,比如bx,必然会因为字节数的不一样(这里指“雇员人数”和“年份”“收入”占的字节数不一样),导致寻址偏差。这个问题该怎么解决?
4、汇编语言中,很多时候用于计算和存储会涉及栈的使用,这个实验,会不会涉及这方面的问题?
既然是实验,那么我们可以先一步一步探索这些问题,然后再来设计解题思路,最后完成程序设计。
首先,根据这本教程提供的基本的代码,来探索第一个问题。
千哥先在程序中补充cs(代码段):
=========这是代码与内容的分割线==========
assume cs:codesg,ds:data
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21年字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
codesg segment
start:mov ax,data
mov ds,ax
mov ax,4c00h
int 21h
codesg ends
end start
=========这是代码与内容的分割线==========
在codesg中,将data段的首地址赋值给寄存器ax,然后通过ax将这个地址传送给ds寄存器,至于tables段的数据,暂时不加进来。
将程序编译成p897.exe可执行文件,在debug下调试和观察:

首先,用R指令,我们可以看到第一条程序指令:MOV AX,076A
因为在codesg段中,我们的程序指令是:mov ax,data,所以data段的段地址就是076A。然后用d 076A:0000,来查看这个数据段的内容。
在显示的内容最右边打红框的部分,我们可以清楚地看到从1975到其他年份的字符串内容。以字符串“1975”为例,左边打红框的部分,从左到右,16进制“31”,代表1的ASCII码,“39”代表9的ASCII码,以此类推。符串“1975”这个字符串就是16进制 31 39 37 35,一共占了四个字节。
也就是说,代表“年份”的21组数据,存放在以076A:0000开始的连续空间里,一共占了21 X 4 = 84个内存单元(一个内存单元一个字节)
那么,代表“收入”的21组数据,又存在哪里的呢?
因为debug显示的内存单元,一行是16个,通过计算不难知道,84 / 16 = 5,所以代表“年份”的21组数据的最后字符串1995应该在第五行,也就是076A:0050的位置,而且占了四个字节,在debug里显示的就是:31 39 39 35。
而上面这些数据中的“35”,后面的10 00 00 00 16 00 00 00 7E 01 00 00 这些数据,又代表什么呢?
我们对照一下定义的“收入”数据:16,22,382…… 16的16进制就是10,22的十六进制就是16,382的16进制就是17E。
由于“收入”这组数据也占4个字节,以16为例 ,低字节的部分是10 00,高字节的部分是00 00 ,按照人的书写习惯就是 00000010(16进制),而在dubeg中 ,从左到右是低字节到高字节,所以呈现出来的数据就是:10 00 00 00(16进制)。
而对于22来说,低字节的部分是16 00,高字节的部分是00 00 ,按照人的书写习惯就是 00000016(16进制),而在dubeg中 ,从左到右是低字节到高字节,所以呈现出来的数据就是:16 00 00 00(16进制)……以此类推。搞清楚这一点,对于我们后面做除法运算非常重要。
也就是说,代表“收入”的21组数据,是存放在代表“年份”的21组数据后面的连续空间的,一共也占21 X 4 = 84个内存单元
接下来我们要问,那么,代表“雇员人数”的21组数据,又存放在哪里的呢?
在数据段的前面,21组代表“年份”的数据和21组代表“收入”的数据,一共是84+84 = 168个字节(占了168个内存单元),通过计算不难知道,168 / 16 = 10,代表“雇员人数”的21组数据,应该在debug显示内容的第10行,也就是:076A:00A0的位置。
在debug下用指令 d 076A:00A0观察:
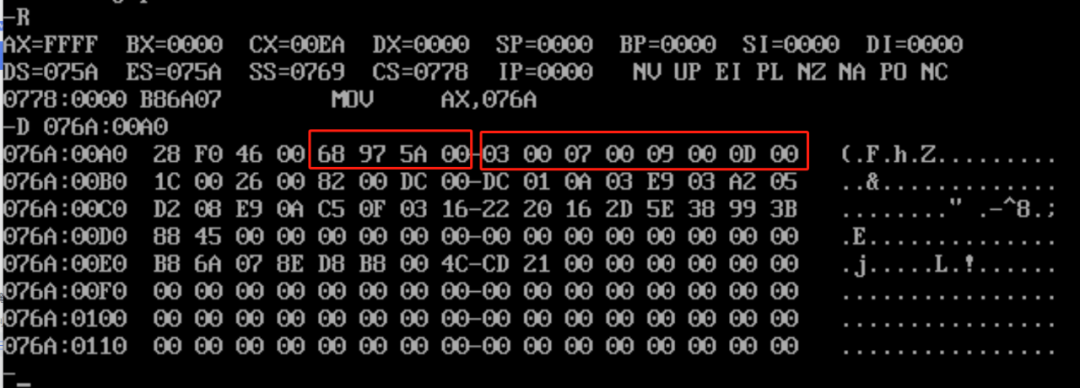
可以看出,从左开始第一个打红框的部分:68 97 5A 00 ,正好对应“入收”数据的最后一个数:5937000(人的书写方式,16进制:00 5A 97 68),而第二个打红框的部分:03 00 07 00 09 00 0D 00,正好就是“雇员人数”的前四个数:3、7、9、13的16进制。
由于“雇员人数”定义的是word型数据,每个数要占2个字节,以3为例,16进制高位是00 ,低位的是03,所以按人的书写方式就是:0003,按照debug的显示模式就是 03 00。
以7为例,16进制高位是00 ,低位的是07,所以按人的书写方式就是:0007,按照debug的显示模式就是 07 00。以此类推。
搞清楚了data段的存储方式之后,接下来我们探索第二个问题:如何将table段中的数据进行存储和呈现?
我们知道,在8086汇编体系下,可用的寄存器一共14个,分别是:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。
其中AX一般用于存返回值(或者用于除法、乘法计算),BX用于寄存器间接寻址(段前缀默认为DS),CX用于循环体的计数,DX作为子程序的第一个参数(或者用于除法、乘法计算),CS用于代码段,IP用于指令指针,DS用于存储数据段所在段的值,SS用于存储栈段的值,SP用于指向栈顶,SI和DI用于寄存器间接寻址(段前缀默认为DS),BP用于寄存器间接寻址(段前缀默认为SS),PSW用于标志位。
剩下的只有一个ES,有着与DS相同的作用。因此,可以用ES来存储table段的数据所在的段的值。
接下来,对刚才的程序进行修改,加入ES寄存器,并且把table段加进去:
=========这是代码与内容的分割线==========
assume cs:codesg,ds:data,es:table
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21年字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
codesg segment
start:mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov ax,4c00h
int 21h
codesg ends
end start
=========这是代码与内容的分割线==========
将程序编译成p897.exe可执行文件,在debug下调试和观察:
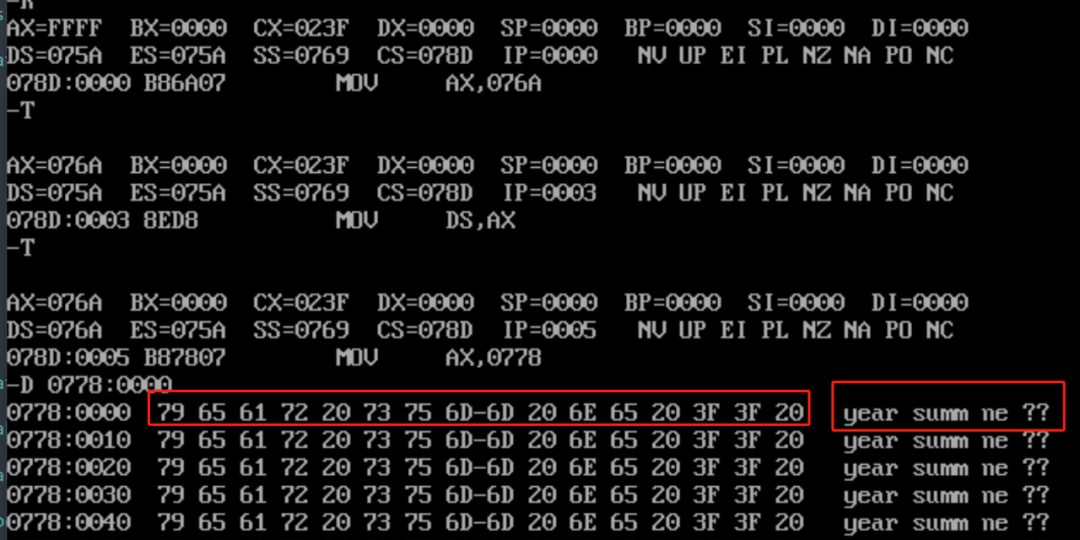
在用T指令执行了MOV DS,AX之后,显示下一条指令是MOV AX,0778,显然,table在内存中的段地址是0778,我们输入D 0778:0000,可以看到,
程序中的代码:db 21 dup ('year summ ne ?? '),从0778:0000开始,开辟了21组连续的内存空间。在debug显示中,每一行(16个内存单元)的最右边的红框部分,以字符串“year summ ne ?? ”来呈现。
在debug显示的内存单元里,也就是左边的红框部分,则代表这些字符串所对应的16进制的ASCII码。
我们先来看“year”这个字符串,一共是四个字节,分别以 79 65 61 72 来表示,79对应的就是字符“y”,65对应的就是字符“e”,以此类推。
根据教程上的题设不难理解,就是要把代表“年份”的数据,比如1975填充到“year”所在的内存单元,把“year”覆盖;把代表“收入”的数据,比如16填充在“summ” “summ”所在的内存单元,把“summ”覆盖;
把代表“雇员人数”的数据,比如3,填充到 “ne”所在的内存单元;并且计算出“收入”与“雇员”的商,比如 16 / 3 = 5(取整),填充到“??”所在的单元,把“??”覆盖。
有了这样的思路,我们就可以进一步思考第三个问题:
由于“年”这组数据,定义的是db类型(字节型),每一个年份,比如“1975”,占了4个字节;“收入”这组数据,定义的是dd(双字型),每一个数字,比如“16”,占了4个字节;“雇员人数”,定义的是dw(字型),每一个数据,比如“3”,占了2个字节。
那么在设计循环体的时候,用同一个寄存器来作为偏移量寻址,比如bx,必然会因为字节数的不一样(这里指“雇员人数”和“年”“收入”占的字节数不一样),导致寻址偏差。
如何解决这一问题?
显然,在设计循环体的时候,代表“年份”的数据和代表“收入”数据,是可以用同一个寄存器来作为偏移量寻址,比如bx来寻址的,因为他们都占4个字节;而代表“雇员人数”的寄存器,是不能用同一个寄存器来偏移量寻址的,但我们可以考虑用si或者di来实现,这取决于我们在程序设计中如何合理使用。
这里,要把程序设计分成“读取”、“计算”和“存储”三个步骤。
第一、将data段中的“年份”、“收入”和“雇员人数”,逐一地读取出来;
第二、将“收入”和“雇员人数”,进行除法运算,得到商值(平均收入);
第三、将“年份”、“收入”、“雇员人数”和“平均收入”,存储在table段中,并且覆盖住table段中的字符串“year summ ne ?? ”
在codesg 中,以循环体来体现,下面是改进后的代码:
=========这是代码与内容的分割线==========
codesgsegment
start:mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov bx,0
mov si,0
mov di,0
mov cx,21
s:mov ax,[bx]
mov es:[bx+si],ax
mov ax,[bx+2]
mov es:[bx+si+2],ax
mov ax,[bx+84];从datasg中读取收入的低16位
mov es:[bx+si+5],ax;将收入的低16位存入tablesg中,覆盖字符串summ中的su
mov ax,[bx+84+2];从datasg中读取收入的高16位
mov es:[bx+si+7],ax;将收入的高16位存入tablesg中,覆盖字符串summ字符串中的mm
mov dx,ax;将收入的高16位赋值给DX
mov ax,[di+84+84];将雇员人数从datasg中读取
mov es:[bx+si+10],ax;将雇员人数存入tablesg中,覆盖字符串ne
mov ax,es:[bx+si+5];将收入的低16位赋值给AX
div word ptr es:[bx+si+10];雇员人数是除数,存放在es:[bx+si+5+4+1]中,收入作为被除数,由dx的高16位和ax的低16位构成32位。商保存在AX中
mov es:[bx+si+13],ax;将商存入tablesg中,覆盖字符串??
add bx,4
add di,2
add si,12
loop s
mov ax,4c00h
int 21h
codesgends
=========这是代码与内容的分割线==========
下步,逐一讲解以上代码,在S循环体中,先看第一组代码:
mov ax,[bx]
mov es:[bx+si],ax
mov ax,[bx+2]
mov es:[bx+si+2],ax
这一组代码的目的是,将代表“年份”的数据从data段中读取出来,然后存入table段中。
1、在mov ax,[bx]这行命令中,段地址默认在ds中,也就是debug中的076A。在第一次循环的时候,bx一开始设置的是0,所以寻址从076A:0000 开始,将076A:0000~076A:0001的第1个内存单元和第2个内存单元的内容,也就是将字符串“1977”的第1个字符“1”(16进制31)和第二个字符“9”(16进制39),也就是 31 39读取出来,存入寄存器AX中。
因为AX是16位寄存器,可以一次传送2个字节的数据,所以mov ax,[bx]这行命令可以一次性将字符串“19”进行存储。
2、在mov es:[bx+si],ax这行命令中,段地址在es中,也就是debug中的0778,在寻址时用的是bx+si,bx一样是0,而si一开始也是0,同时si也是作为循环变量,用于对下一行的“year summ ne ?? ”寻址。在第一次循环的时候,把AX所读取的16进制数据31 39 存入es:[bx+si]中,也就是0778:0000~0778:0001这两个单元中。
3、在mov ax,[bx+2]这行命令中,段地址默认在ds中,目的是把字符串“1977”的第三个字符“7”(16进制37)和第四个字符“5”(16进制35)读取出来存入寄存器AX中。但是偏移量要加2,因为字符串“1977”占了4个字节,反映在debug中,是 31 39 37 35,而“19”(16进制31 39) 两个字符就占了2个字节。
4、在mov es:[bx+si+2],ax这行令中,段地址在es中,也就是debug中的0778。在第一次循环的时候,把AX所读取的16进制数据37 35 存入es:[bx+si]中,也就是0778:0002~0778:0003这两个单元中。
我们在debug中执行一下:

用 d 0778:0000 指令观察。
看得出来,在0778:0000~0778:0003这四个内存单元中,已经成功写入 31 39 37 35 (左边红框部分),也就是1975(右边红框部分)。
下面,就要对字符串“summ”进行改写。我们来看第二组代码:
mov ax,[bx+84];从datasg中读取收入的低16位
mov es:[bx+si+5],ax;将收入的低16位存入tablesg中,覆盖字符串summ中的su
mov ax,[bx+84+2];从datasg中读取收入的高16位
mov es:[bx+si+7],ax;将收入的高16位存入tablesg中,覆盖字符串summ字符串中的mm
mov dx,ax;将收入的高16位赋值给DX
这一组代码的目的是,将代表“收入”的数据从data段中读取出来,然后存入table段中。
1、在mov ax,[bx+84] 这行命令中,段地址默认在ds中,也就是debug中的076A。在第一次循环的时候,bx一开始设置的是0,所以寻址从076A:0000 开始,偏移量为0+84,因为前面的代表“年份”的数据占了84个字节,而84对应的16进制就是54,也就是将076A:0054~076A:00055的第1个内存单元和第2个内存单元的内容,也就是数字16(16进制 10 00 00 00)的第1个字节“10”和第二个字节“00”读取出来,存入寄存器AX中。
这里需要注意的是,代表“收入”的数据,定义的是dd,也就是双字,占了4个字节;数字16,完整的16进制是 10 00 00 00。因此,mov ax,[bx+84] 这行命令,实际上只是把2个低字节的 10 00,赋值给了AX;下一步,还需要把另外2个高字节的 00 00 赋值给 AX,并转送到table 中相应的内存单元中去。
2、在mov es:[bx+si+5],ax这行命令,段地址在es中,也就是debug中的0778,在寻址时用的是bx+si,bx一样是0,而si一开始也是0,同时si也是作为循环变量。在第一次循环的时候,把AX所读取的16进制数据10 00 存入 es:[bx+si+5]中,也就是0778:0005~0778:0006这两个单元中。
这里需要注意的是,偏移量5,指的是AX中的16进制数据10 00要覆盖住“summ”字符串中的su,要考虑“summ”字符串前面的“year”字符串占了4个字节,“year”字符串后面还跟了一个空格,加起来就是5个字节。
3、在mov ax,[bx+84+2] 这行命令中,段地址默认在ds中,也就是debug中的076A。在第一次循环的时候,bx一开始设置的是0,所以寻址从076A:0000 开始,偏移量为0+84+2,因为前面的代表””年份“的数据占了84个字节,而前面已经读取了2个字节的数据,所以还要加上2,也就是等于0+84+2 = 86。
而86对应的16进制就是56,也就是将076A:0056~076A:00057的内存单元的内容,也就是数字16(16进制 10 00 00 00)的第三个字节“00”和第四个字节“00”读取出来,存入寄存器AX中。
4、在mov es:[bx+si+7],ax 这行命令中,段地址在es中,也就是debug中的0778,在寻址时用的是bx+si,bx一样是0,而si一开始也是0,同时si也是作为循环变量。在第一次循环的时候,把AX所读取的16进制数据00 00 存入es:[bx+si+7]中,也就是0778:0007~0778:0008这两个单元中。
这里需要注意的是,偏移量7,指的是AX中的16进制数据00 00要覆盖住“summ”字符串中的mm,要考虑“summ”字符串前面的“year”字符串占了4个字节,“year”字符串后面还跟了一个空格,占了1个字节,后面的su又占了2个字节,加起来就是0+0+5+2=7个字节。所以,也可以直接写成:
mov es:[bx+si+7],ax
我们在debug中执行一下:

可以看到,10 00 00 00 这4个字节代表的数字16,已经成功写入了table 中的内存单元(左边红框部分),而右边的红框部分的省略号,则是相关16进制数据映射的字符串,这个不管它。
再来看最后一句命令:
mov dx,ax
则是将AX读取的高16位的数据 00 00 ,赋值给 DX,目的是用于后面的除法运算。暂时也可以不管它。
接下来,我们来看第三组代码:
mov ax,[di+84+84];将雇员人数从datasg中读取
mov es:[bx+si+10],ax;将雇员人数存入tablesg中,覆盖ne字符串
mov ax,es:[bx+si+5];将收入的低16位赋值给AX
这一组代码的目的是,将代表“雇员人数”的数据从data段中读取出来,然后存入table段中。
1、在movax,[di+84+84] 这行命令中,段地址默认在ds中,也就是debug中的076A。在第一次循环的时候,di一开始设置的是0,所以寻址从076A:0000 开始,偏移量为84+84,因为前面的代表””年份“的数据占了84个字节,后面的代表“收入”的数据又占了84个字节,加起来就是168。
而168对应的16进制就是A8,也就是将076A:00A8~076A:00A9的第1个内存单元和第2个内存单元的内容,也就是数字3(16进制 03 00 )的第1个字节“03”和第二个字节“00”读取出来,存入寄存器AX中。
这里需要注意的是,由于“年份”这组数据,定义的是db类型(字节型),每一个年份占了4个字节;“收入”这组数据,定义的是dd(双字型),每一个数字占了4个字节;“雇员人数”,定义的是dw(字型),每一个数据占了2个字节;所以我们不能再用同一个寄存器BX来寻址了,这里就引入的DI这个寄存器。
2、在mov es:[bx+si+10],ax 这行命令中,段地址在es中,也就是debug中的0778,在寻址时用的是bx+si,bx一样是0,而si一开始也是0,同时si也是作为循环变量。在第一次循环的时候,把AX所读取的16进制数据 03 00 存入 es:[bx+si+10]中,也就是0778:0005~0778:0006这两个单元中。
这里需要注意的是,偏移量bx+si+10,继续使用寄存器BX作为其中的一个偏移量而不是DI,是因为将雇员人数从datasg中读取的时候,是读取的2个字节,但在将这些数据存储在以ES为段的地址中的时候,“year summ ne ?? ”这个字符串中的“year”“summ”也是4个字节,对应的“年份”“收入”也都是4个字节,所以可以延续前面的存储数据的偏移量BX。而加10,是因为在字符串 “ne”前面,加上空格以及相关字符,一共是10个字节。
3、mov ax,es:[bx+si+5] 这行命令中,是将收入的低16位赋值给AX,用于除法运算。
最后,我们来看第四组代码:
divword ptr es:[bx+si+10];雇员人数是除数,存放在es:[bx+si+5+4+1]中,收入作为被除数,由dx的高16位和ax的低16位构成32位。商保存在AX中
moves:[bx+si+13],ax;将商存入tablesg中,覆盖字符串??
add bx,4
add di,2
add si,12
这一组代码的目的是,是将赋值给AX的收入的低16位,与赋值给DX的收入的高16作为被除数,存储在es:[bx+si+10]中的雇员人数作为除数,然后计算出“平均收入”的商,然后存入table段中;并且将相关值赋值给bx、di、si等用于循环变量的寄存器。
这里需要注意的是,在8086汇编语言中,如果除数为32位,被除数为16位,那么除数的高16位,需要存储在DX中,除数的低16位,需要存储在AX中。
而在本实验中,作为被除数的“收入”,每个10进制数值,比如16,以及最后一个10进制数值5937000,都是4个字节,32位;而作为除数的“雇员人数”,都是2个字节,16位。所以才有前面的代码:
mov dx,ax;将收入的高16位赋值给DX
mov ax,es:[bx+si+5];将收入的低16位赋值给AX
而后面的代码:
mov es:[bx+si+13],ax
bx+si+13,偏移量加13,是因为在字符串“year summ ne ?? ”中,两个?的前面,还有13个字节。
而在变量自加的这段代码中:
add bx,4
add di,2
add si,12
1、bx每次自加4,其作用是在读取和存储“年份”“收入”这些数据的时候,每次偏移4个字节,因为“年份”“收入”每组数据都是4个字节。
2、di每次自加2,其作用是在读取“雇员人数”这些数据的时候,每次偏移2个字节,因为“雇员人数”每组数据都是2个字节。
3、si每次自加12,其作用是配合bx进行换行,bx+si = 16,在字符串“year summ ne ?? ”中,一共是16个字节,在对其下一行进行操作时,下一行的首字母又是“y”,而“y”的前面,连同三个空格就有16个字节。
现在所有的讲解已经完毕,贴出完整的代码:
=========这是代码与内容的分割线==========
assume cs:codesg,ds:data,es:table
data segment
db '1975','1976','1977','1978','1979','1980','1981','1982','1983'
db '1984','1985','1986','1987','1988','1989','1990','1991','1992'
db '1993','1994','1995'
;以上是表示21年的21年字符串
dd 16,22,382,1356,2390,8000,16000,24486,50065,97479,140417,197514
dd 345980,590827,803530,1183000,1843000,2759000,3753000,4649000,5937000
;以上是表示21年公司总收入的21个dword型数据
dw 3,7,9,13,28,38,130,220,476,778,1001,1442,2258,2793,4037,5635,8226
dw 11542,14430,15257,17800
;以上是表示21年雇员人数的21个word型数据
data ends
table segment
db 21 dup ('year summ ne ?? ')
table ends
codesg segment
start:mov ax,data
mov ds,ax
mov ax,table
mov es,ax
mov bx,0
mov si,0
mov di,0
mov cx,21
s:mov ax,[bx]
mov es:[bx+si],ax
mov ax,[bx+2]
mov es:[bx+si+2],ax
mov ax,[bx+84];从datasg中读取收入的低16位
mov es:[bx+si+5],ax;将收入的低16位存入tablesg中,覆盖字符串summ中的su
mov ax,[bx+84+2];从datasg中读取收入的高16位
mov es:[bx+si+7],ax;将收入的高16位存入tablesg中,覆盖字符串summ字符串中的mm
mov dx,ax;将收入的高16位赋值给DX
mov ax,[di+84+84];将雇员人数从datasg中读取
mov es:[bx+si+10],ax;将雇员人数存入tablesg中,覆盖字符串ne
mov ax,es:[bx+si+5];将收入的低16位赋值给AX
div word ptr es:[bx+si+10];雇员人数是除数,存放在es:[bx+si+10]中,收入作为被除数,由dx的高16位和ax的低16位构成32位。商保存在AX中
mov es:[bx+si+13],ax;将商存入table中,覆盖字符串??
add bx,4
add di,2
add si,12
loop s
mov ax,4c00h
int 21h
codesg ends
end start
=========这是代码与内容的分割线==========
在debug下运行程序p897.exe
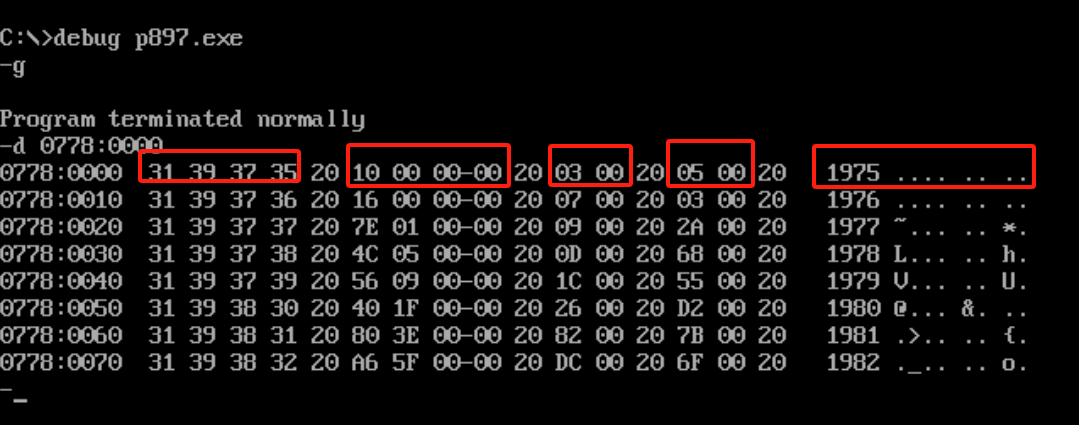
用 d 0778:0000 指令观察,可以很清楚地看到,在debug显示下,第一行:
年份:10进制1975,16进制 31 39 37 35
收入:10进制16,16进制 10 00 00 00
雇员人数:10进制3,16进制 03 00
平均收入:10进制5(16 / 3 = 5,取整),16进制 05 00
打完收工,完美解决问题。其他的数据,请各位自行验证。
这里需要注意的是,内存单元中的20,是空格符号的16进制ASCII码;程序中并没有用到栈的方式,当然也可以继续思考,是否可以用到栈的方式。
小结:本实验其实考察的是:
1、db、dw、dd 对数据的定义和使用,要注意三者之间的数据宽度的问题;
2、在进行寻址的过程中,如何使用ds、es的问题,以及如何运用bx、si、di的问题;
3、在进行除法运算的过程中,如何理解ax、dx的问题。
其实这些问题并不难,需要的是耐心和细心而已。















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









