







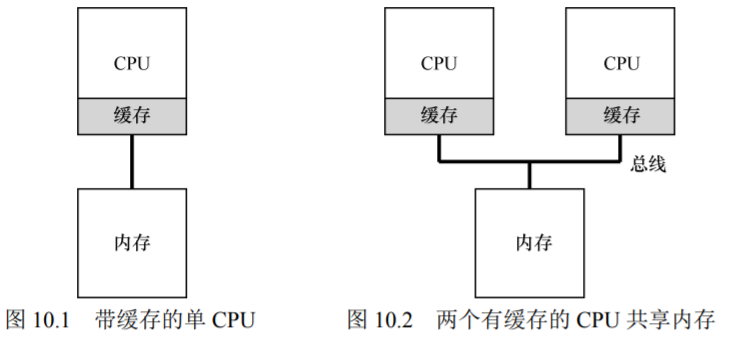
1.背景:多处理器架构
如果系统有多个处理器,并共享同一个内存,会怎样呢?
假设一个运行在 CPU 1上的程序 从内存地址 A 读取数据。由于不在 CPU 1的缓存中,所以系统直接访问内存,得到值 D。 程序然后修改了地址 A 处的值,只是将它的缓存更新为新值 D'。将数据写回内存比较慢, 因此系统(通常)会稍后再做。假设这时操作系统中断了该程序的运行,并将其交给 CPU 2, 重新读取地址 A 的数据,由于 CPU 2的缓存中并没有该数据,所以会直接从内存中读取, 得到了旧值 D,而不是正确的值 D'。
这一普遍的问题称为缓存一致性(cache coherence)问题。
解决方案:
通过监控内存访问,硬件可以保证获得正确的数据,并保证共享内存的唯一性。在基于总线的系统中,一种方式是使用总线窥探(bus 10.2 别忘了同步 75 snooping)[G83]。每个缓存都通过监听链接所有缓存和内存的总线,来发现内存访问。如 果 CPU 发现对它放在缓存中的数据的更新,会作废(invalidate)本地副本(从缓存中移除), 或更新(update它(修改为新值)。
2.别忘了同步
我们设想这样的代码序列,用于删除共享链表的一个元素。假设两个 CPU 上的不同线程同时进入这个函数。如果线程 1 执行第一行,会将 head 的当前值存入它的 tmp 变量。如果线程 2 接着也执行第一行,它也会将同样的 head 值存入它 自己的私有 tmp 变量(tmp 在栈上分配,因此每个线程都有自己的私有存储)。因此,两个线程会尝试删除同一个链表头,而不是每个线程移除一个元素,这导致了各种问题(比如 在第 4 行重复释放头元素,以及可能两次返回同一个数据)。

解决方案:加锁(locking)。这里只需要一个互斥锁(即 pthread_mutex_t m;),然后在函数开始时调用 lock(&m),在结束时调用 unlock(&m),确保代码的执行如预期。我们会看到,这里依然有问题,尤其是性能方面。具体来说,随着 CPU 数量的增加,访问同步共享的数据结构会变得很慢。
3.单队列调度(SQMS)
概念: 简单地复用单处理器调度的基本架构,将所有需要调度的工作放入一个单独的队列中,我们称之为单队列多处理器调度。
短板:
1. 缺乏可扩展性。为了保证在多 CPU 上正常运行,调度程序的开发者需要在代码中通过加锁(locking)来保证原子性。随着这 种单个锁的争用增加,系统花费了越来越多的时间在锁的开销上,较少的时间用于系统应该完成的工作。
2. 缓存亲和性。 假设我们有 5 个工作(A、B、C、D、 E)和 4 个处理器。调度队列如下:

一段时间后,假设每个工作依次执行一个时间片,然后选择另一个工作,下面是每个 CPU 可能的调度序列:
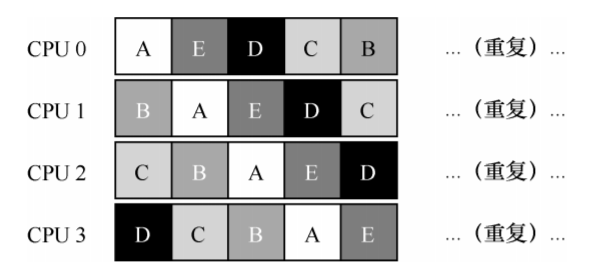
每个 CPU 都简单地从全局共享的队列中选取下一个工作执行,因此每个工作都不断在不同 CPU 之间转移,这与缓存亲和的目标背道而驰。
解决方案:加入亲和机制,尽可能让进程在同一个CPU上运行。例如:
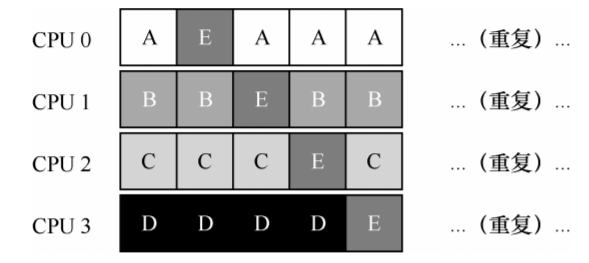
A、B、C、D 这 4 个工作都保持在同一个 CPU 上,只有工作 E 不断地来回迁移(migrating),从而尽可能多地获得缓存亲和度。
4.多队列调度(MQMS)
使用多队列的方案, 比如每个CPU一个队列,我们称之为多队列多处理器调度。 基本调度框架包含多个调度队列,每个队列可以使用不同的调度规则, 比如轮转或其他任何可能的算法。
例如,假设系统中有两个 CPU(CPU 0 和 CPU 1)。这时一些工作进入系统:A、B、C 和 D。由于每个 CPU 都有自己的调度队列,操作系统需要决定每个工作放入哪个队列。可能像下面这样做:
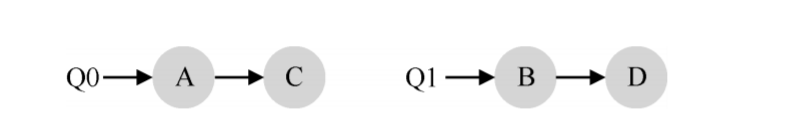
根据不同队列的调度策略,每个CPU从两个工作中选择,决定谁将运行。例如,利用轮转,调度结果可能如下所示:

优点: 1.更具有可扩展性。队列的数量会随着 CPU 的增 加而增加,因此锁和缓存争用的开销不是大问题。
2.MQMS 天生具有良好的缓存亲和度。所有工作都保持在固定的 CPU 上,因而可以很好地利用缓存数据。
问题:负载不均。 假定和上面设定一样(4 个工作,2 个 CPU),但假设一个工作(如 C)这时执行完毕。现在调度队列如下:
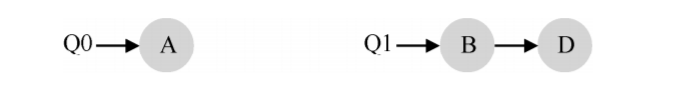
如果对系统中每个队列都执行轮转调度策略,会获得如下调度结果:

从图中可以看出,A 获得了 B 和 D 两倍的 CPU 时间,这不是期望的结果。更糟的是, 假设 A 和 C 都执行完毕,系统中只有 B 和 D。调度队列看起来如下:
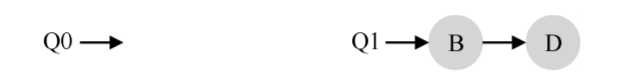
因此 CPU 使用时间线看起来令人难过:

解决方案:迁移。 通过工作的跨 CPU 迁移,可以真正实现负载均衡。
不断地迁移一个或多个工作。一种可能的解决方案是不断切换工作,如下面的时间线所示。可以看到,开始的时候 A 独享 CPU 0,B 和 D 在 CPU 1。一些时间片后,B 迁移到 CPU 0 与 A 竞争,D 则独享 CPU 1 一段时间。这样就实现了负载均衡。

5.小结
本章介绍了多处理器调度的不同方法。其中单队列的方式(SQMS)比较容易构建,负载均衡较好,但在扩展性和缓存亲和度方面有着固有的缺陷。多队列的方式(MQMS)有很好的扩展性和缓存亲和度,但实现负载均衡却很困难,也更复杂。无论采用哪种方式, 都没有简单的答案:构建一个通用的调度程序仍是一项令人生畏的任务,因为即使很小的代码变动,也有可能导致巨大的行为差异。















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









