









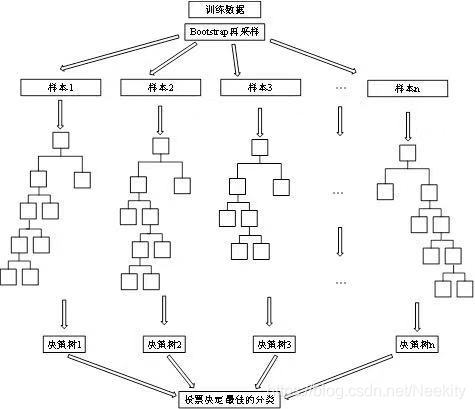
随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器。随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度(将来自集合中的某种结果随机应用于集合中某一数据项的预期误差率)或者信息增益(当前熵与两个新群组经加权平均后的熵之间的差值)。
能否将随机森林中的基分类器由决策树替换为线性分类器或K近邻?
随机森林属于Bagging类的集成学习,Bagging的主要好处是集成后的分类器的方差,比基分类器的方差小。所以基分类器最好是不稳定的本身对样本分布较为敏感的基分类器。
线性分类器或者K-近邻都是较为稳定的分类器,本身方差并不大,所以用Bagging方法并不能获得更好的表现,甚至因为采样问题更难收敛增大了集成分类器的难度。














 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









