



优化Elasticsearch索引分片策略
大多数Elasticsearch用户在创建索引时,都会面对一个关键问题:我应该创建多少个分片?在这篇文章中,我将探讨分片分配时的一些权衡因素,以及不同设置对性能的影响。如果您希望深入了解分片策略及其优化方法,请继续阅读。
为什么需要考虑分片数?
分片分配是一个非常重要的概念,很多用户对此感到困惑,主要是为了实现更合理的数据分布。在生产环境中,随着数据集的增长,不合理的分片策略可能会给系统的扩展带来严重的问题。此外,这一领域的文档资料相对较少,许多用户希望得到具体的答案,而不仅仅是数字范围,甚至没有意识到随意设置分片可能引发的问题。
当然,我也有些建议。但在深入讨论之前,让我们先了解一下分片的基本定义,然后通过几个常见的案例来提出我们的建议。
分片定义
如果您刚刚接触Elasticsearch,理解几个基本术语和核心概念是非常必要的。
(如果您已经熟悉Elasticsearch,可以跳过这一部分)
假设ElasticSearch集群的部署结构如下:
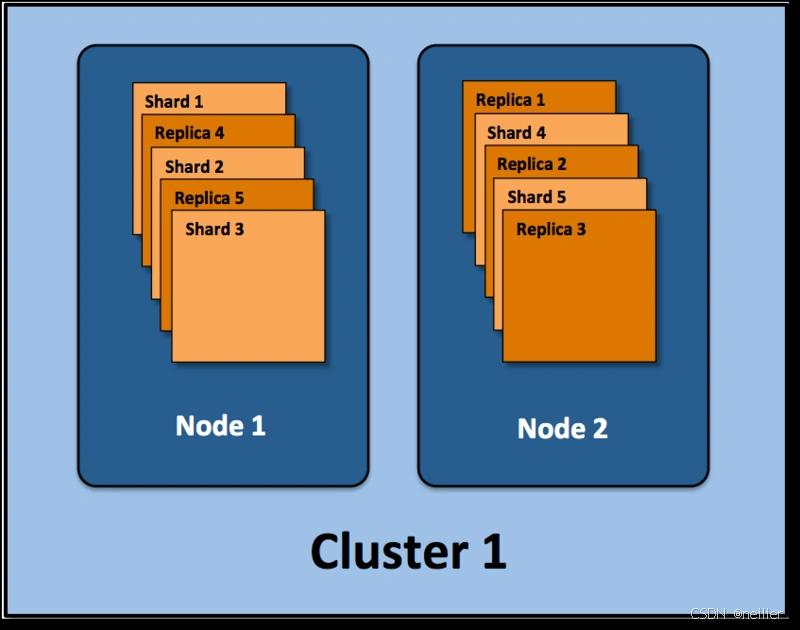
- 集群(Cluster):由一个或多个节点组成,通过集群名称与其他集群区分开来。
- 节点(Node):单一的Elasticsearch实例,通常运行在一个隔离的容器或虚拟机中。
- 索引(Index):在Elasticsearch中,索引是一组文档的集合。
- 分片(Shard):因为Elasticsearch是一个分布式的搜索引擎,所以索引通常会被拆分成不同的部分,这些分布在不同节点上的数据被称为分片。Elasticsearch自动管理并组织分片,在必要时重新平衡分片数据,因此用户通常无需担心分片的具体处理细节。
- 副本(Replica):Elasticsearch默认为一个索引创建5个主分片,并分别为每个主分片创建一个副本。这意味着每个索引由5个主分片组成,每个主分片都有一个副本。对于分布式搜索引擎而言,分片和副本的分配是实现高可用性和快速搜索响应的核心设计。主分片和副本都可以处理查询请求,但只有主分片可以处理索引请求。
在上述示例中,我们的Elasticsearch集群包含两个节点,并使用了默认的分片配置。Elasticsearch自动将这5个主分片分配到这两个节点上,而它们各自的副本则位于完全不同的节点上。这就是分布式的概念。
请注意,索引的number_of_shards参数仅对当前索引有效,而不是对整个集群有效。对于每个索引,该参数定义了当前索引的主分片数量(而不是集群中所有主分片的数量)。
副本的作用
本文不会详细介绍Elasticsearch的副本机制。如果想深入了解副本,请参阅相关文章。
副本对搜索性能至关重要,用户也可以随时添加或移除副本。正如另一篇文章所述,额外的副本可以提升系统的容量、吞吐量和故障恢复能力。
谨慎选择分片数量
在Elasticsearch集群中配置索引后,您需要知道在集群运行期间无法调整分片设置。即使后来发现需要改变分片数量,也只能通过重新创建索引并重新索引数据来实现,虽然这会消耗一定的时间,但至少可以避免服务中断。
主分片的配置类似于磁盘分区。在对一块空硬盘进行分区时,通常需要先备份数据,然后配置新的分区,最后将数据写入新分区。
对于大约2~3GB的静态数据集,分片分配主要考虑的是数据集的增长趋势。我们也经常遇到一些不必要的过度分片场景。从Elasticsearch社区用户的反馈来看,有些人认为过度分配是一种绝对安全的策略,即为每个索引分配超过当前数据量所需数量的分片。
Elasticsearch早期确实提倡过这种做法,但随后许多用户走得更远——例如分配1000个分片。实际上,Elasticsearch现在对此持更加谨慎的态度。
- 稍微留有余地是好的,但过度分配分片则是错误的。具体应该分配多少分片很难有定论,这取决于用户的数据量和使用模式。100个分片,即便很少使用也可能是合适的;而2个分片,即便使用频繁也可能显得多余。
需要注意的是,每个分片都有额外的成本:
- 每个分片本质上是一个Lucene索引,因此会消耗文件句柄、内存和CPU资源。
- 每个搜索请求都会被调度到索引的每个分片上。如果分片分布在不同的节点上,这通常不是问题;但如果分片开始争夺相同的硬件资源,性能就会逐渐下降。
- Elasticsearch使用词频统计来计算相关性,这些统计信息也会被分配到各个分片上。如果在大量的分片上只存储了少量数据,最终可能导致文档相关性的降低。
我们的客户通常认为随着业务的发展,数据量也会相应增加,因此为长远规划做准备是有必要的。许多用户预计会出现爆炸性增长(尽管大多数从未经历过高峰),并且希望避免重新分配分片和潜在的服务中断。
如果您担心数据快速增长,我们建议您关注以下限制:Elasticsearch推荐的最大JVM堆空间为30~32GB,因此建议将每个分片的最大容量限制在30GB左右,然后再根据数据量合理估计分片数量。例如,如果您预计数据总量将达到200GB,我们建议您最多分配7到8个分片。
总的来说,不要为可能三年后才能达到的10TB数据提前分配过多的分片。如果真的到了那一天,您也会提前察觉到性能的变化。
尽管本节没有详细讨论副本分片,但我们建议您保持适度的副本数量,并根据需要随时调整。如果您正在部署新的环境,可以参考我们的基于副本的集群设计。这个集群由三个节点组成,每个分片仅分配了一个副本。但是,随着需求的变化,您可以轻松调整副本数量。
大规模及持续增长的数据场景
对于大型数据集,我们强烈建议您为索引分配更多的分片——当然,仍然要在合理的范围内。上述每个分片不超过30GB的原则同样适用。
不过,您最好能够说明在每个节点上仅放置一个索引分片的必要性。在初期,一个好的策略是根据节点数量按1.5到3倍的比例创建分片。例如,如果您有3个节点,建议创建最多9个分片(3x3)。
随着数据量的增加,如果您通过集群状态API发现问题或遇到性能下降,只需添加额外的节点即可。Elasticsearch会自动帮您完成分片在不同节点上的重新分配。
再次强调,虽然这里没有详细讨论副本节点,但上述指导原则仍然适用:是否需要在每个节点上仅分配一个索引的分片。另外,如果为每个分片分配一个副本,您需要的节点数量将翻倍;如果分配两个副本,则需要三倍的节点数量。更多信息请参见基于副本的集群设计。
Logstash场景
如果您有基于日期的索引需求,并且对这些索引的搜索场景非常有限,那么这些索引的数量可能会达到数百甚至数千,但每个索引的数据量可能只有1GB甚至更小。在这种情况下,我们建议您只为索引分配一个分片。
如果使用Elasticsearch的默认配置(5个分片),并通过Logstash按天生成索引,那么6个月内您将拥有890个分片。如果分片数量进一步增加,除非您提供了更多的节点(例如15个或更多),否则集群将难以正常工作。
试想一下,大多数Logstash用户并不会频繁进行搜索,甚至每分钟都不会有一次查询。因此,在这种场景下,推荐采用更为经济高效的设置。搜索性能不是首要考虑的因素,因此不需要很多副本。保持单个副本用于数据冗余已足够。不过,这也意味着数据被加载到内存中的比例会更高。
如果您为索引分配一个分片,那么在3节点的集群中可以维持6个月的运行。当然,您至少需要4GB的内存,但建议使用8GB,因为在多租户云平台上,8GB的内存可以提供更好的网络速度和更少的资源争用。
总结
再次强调,数据分片也会产生相应的资源消耗,并需要持续的投资。
当索引包含较多分片时,为了组合查询结果,Elasticsearch必须单独查询每个分片(当然是以并行方式),并对结果进行合并。因此,高性能的I/O设备(如SSD)和多核处理器对分片性能有着显著的提升作用。尽管如此,您仍需关注数据本身的大小、更新频率和未来的状态。在分片分配方面没有绝对的答案,只希望本文的讨论能为您带来启示。
通过上述内容,希望能为您提供有价值的指导,帮助您在Elasticsearch的使用过程中做出更加明智的选择。

















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









