







这是一篇2025年发表在arxiv中的LLM领域论文,斯坦福大学的研究员认为 Base 模型边界锁死了 RL 的上限,虽然这个结论看上去显而易见,因为RL的作用其实是让LLM能够输出更好的结果,但这个结果的边界仍然是LLM自身决定的,但这篇文章提出了这一点,与之相应的还有两外两篇来自清华和交大的论文,我后续会写对应的笔记。
这篇文章另一个贡献是模型固有的认知能力会决定其解决复杂问题的上限,但通过少量微调也可以让不具备认知能力的模型获得这一能力;同时,正式因为模型有认知行为的存在,才使得RL可以对齐性能进行提升,否则RL也无法限制拉高模型表现。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基本的 LLM、RL相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
- 原文链接: https://arxiv.org/abs/2503.01307
- 发表时间:2025年03月03日
- 发表平台:arxiv
- 预印版本号:[v1] Mon, 3 Mar 2025 08:46:22 UTC (2,097 KB)
- 作者团队:Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, Noah D. Goodman
- 院校机构:
- Stanford University
- 项目链接: 【暂无】
- GitHub仓库: https://github.com/kanishkg/cognitive-behaviors
Abstract
测试时推理(TTS)已成为一种强大的范例,它使语言模型能够像熟练的人类专家一样对复杂挑战进行更长时间、更仔细的“思考”。虽然强化学习 (RL) 可以推动语言模型在可验证任务上的自我改进,但有些模型显示出显着的进步,而其他模型则很快达到平台期。作者发现在相同的 Countdown 游戏 RL 训练下,Qwen-2.5-3B 远远超过 Llama-3.2-3B。这种差异提出了一个关键问题:哪些内在属性可以实现有效的自我改进?作者引入了一个框架,通过分析四种关键的认知行为(verification 验证、backtracking 回溯、subgoal setting 子目标设定、backward chaining 后向链接)来调查这个问题,这四种行为都是人类问题解决专家和成功的语言模型所采用的。研究表明,Qwen 自然地表现出这些推理行为,而 Llama 最初缺乏这些行为。在对受控行为数据集进行系统性实验时发现,用包含这些推理行为的示例对 Llama 进行启动训练,可以显著提升其在强化学习过程中的表现,使其达到甚至超越 Qwen 的表现。重要的是推理行为的存在而非答案的正确性,被证明是关键因素,即用包含正确推理模式的错误答案进行启动训练的模型,其性能与用正确答案进行训练的模型相当。最后,利用 OpenWebMath 数据进行持续预训练,并对其进行过滤以增强推理行为,使 Llama 模型能够匹配 Qwen 的自我提升轨迹。研究结果建立了初始推理行为与改进能力之间的基本关系,解释了为什么某些语言模型能够有效地利用额外的计算,而另一些则停滞不前。
1. Introduction
当人类遇到困难但可解决的问题时,会花更多时间深入思考、慎重考虑以找到解决方案。最近的语言模型在通过强化学习进行自我改进训练时,已经开始表现出类似的推理行为。使用强化学习 (RL) 对可验证问题训练语言模型并不是一个新方法,但利用 RL 的旧方法在几次迭代后就停滞不前,而没有探索出许多使用测试时计算进行思考的有效方法。在这项工作中,作者研究了这种自我改进能力变化背后的原因,重点关注基础语言模型中关键认知行为的存在。
重点研究了两个基础模型:Qwen-2.5-3B 和 Llama-3.2-3B。这两个模型在用强化学习训练“Countdown”游戏时表现出显著差异。Qwen 在问题解决能力方面表现出显著提升,而 Llama2 在相同的训练过程中提升有限。讨论初始语言模型的哪些特性促成了这样的提升。
为了系统地研究这个问题,作者开发了一个框架来分析有助于解决问题的认知行为。描述了四种关键的认知行为:验证(系统性错误检查)、回溯(放弃失败的方法)、子目标设定(将问题分解为可管理的步骤)、后向链接(从期望结果推理到初始输入)。这些行为反映了专家级问题解决者处理难题的方式:数学家会验证证明的每一步,在遇到矛盾时回溯,并将复杂的定理分解为更简单的引理。研究这四种行为,因为可以用来表示基于搜索的推理,这种推理超越了语言模型所展现的典型“线性”推理。虽然还存在许多其他认知行为,但本文从这些行为入手,因为它们定义明确,并且在模型输出中易于识别。
初步分析表明,Qwen 自然地表现出这些推理行为,特别是验证和回溯,而 Llama 则缺乏这些行为。这一观察结果启发了核心假设:初始策略中的某些推理行为对于通过扩展推理序列有效利用增加的测试时间计算是必不可少的。通过对初始模型进行干预来检验这一假设。首先证明了,用包含这些行为(特别是回溯)的合成推理轨迹对 Llama 进行启动,可以在 RL 过程中实现显着的改进,与 Qwen 的表现轨迹相匹配;其次,如果模型表现出正确的推理模式,即使在错误的解决方案上进行启动,这些收益也会持续存在,这表明推理行为的存在,而不是获得正确的解决方案,才是成功自我改进的关键因素;第三,通过整理来自 OpenWebMath 强调这些推理行为的预训练数据表明,有针对性地修改预训练分布可以成功诱导有效使用测试时计算所必需的行为模式,Llama 的改进轨迹与 Qwen 的改进轨迹相匹配。
研究揭示了模型的初始推理行为与其改进能力之间的密切关系。这种联系有助于解释为什么有些语言模型能够有效地利用额外的计算能力,而另一些则停滞不前。理解这些动态变化可能是开发能够显著提升解决问题能力的人工智能系统的关键。
2. Related Work
提高语言模型推理能力的最新方法大致可分为三个互补的方向:利用多个样本的外部搜索方法、使模型能够推理自身输出的上下文搜索、允许模型自主发现推理策略的强化学习方法。
External Search for Reasoning
最近的研究表明,当给予额外的推理时间计算时,语言模型可以显著提高它们在复杂任务上的性能。Snell 等人通过开发各种方法来搜索推理轨迹,系统地探索了这一空间。这些方法包括简单的并行采样与使用验证器或过程奖励模型 (PRM) 的更复杂方法。一些研究人员更进一步,通过使用搜索过程本身来改进底层推理模型。然而,这些方法通常在没有意识到先前探索过的解决方案的情况下运行,从而通过冗余探索限制了它们的效率。
In-Context Search and Self-Improvement
与外部搜索方法相比,另一研究方向侧重于使模型能够按语言顺序进行搜索。这已通过多种方法实现,例如:1)上下文相关示例;2)基于线性化搜索轨迹进行微调;3)基于自校正示例进行训练。Schultz 等人的最新研究弥合了上下文相关方法和外部搜索方法之间的差距,并在战略博弈中展现出更高的性能。这些方法虽然有效,但通常需要精心设计训练数据以融入所需的行为,例如自校正和回溯。
Reinforcement Learning for Reasoning
模型自主发现有效推理策略的前景,激发了强化学习方法领域的大量研究。早期在教授语言模型进行可验证结果推理方面的工作探索了各种强化学习方法,从离线策略 (off-policy) 和批量方法到在线策略 (on-policy) 方法。这些方法在推理轨迹的信用分配方式上有所不同。 Deepseek-R1取得了显著突破,它表明即使是 PPO 的简化版本 GRPO 也能带来显著的改进,并催生情境内搜索行为。最近的分析开始解读这些结果,发现与较短的推理链相比,使用较长的结构化思维链进行监督微调可以提高强化学习的效率和性能。然而,一个关键问题仍未得到解答:为什么有些模型能够通过强化学习成功学习,而其他模型却无法改进?作者的工作通过研究能够成功进行推理行为强化学习的初始模型的基本属性来解决这一问题。
3. Identifying and Engineering Self-Improving Behavior
3.1 Initial Investigation: A tale of two models
首先探讨一个令人惊讶的观察结果:规模相当但来自不同家族的语言模型,通过强化学习展现出显著不同的改进能力。Countdown 游戏是我们的主要测试平台,这是一个数学谜题,玩家必须使用四种基本算术运算
(
+
,
−
,
×
,
÷
)
(+,-,\times,\div)
(+,−,×,÷)组合一组输入数字,以达到目标数字。例如,给定数字 25、30、3、4 和目标数字 32,解决方案是通过一系列运算将这些数字组合起来,以达到恰好
32
:
(
30
−
25
+
3
)
×
4
32: (30-25+3)\times4
32:(30−25+3)×4。
选择 “Countdown” 进行分析,是因为它需要数学推理、规划和搜索策略,这些策略与数学等其他推理领域类似,反映了一般问题解决的关键方面。与更复杂的领域不同,“Countdown”提供了一个受限的搜索空间,使其能够进行易于处理的分析,同时仍然需要复杂的推理。此外,与其他数学任务(领域知识可能会影响对推理能力的评估)相比,游戏中的成功更多地取决于解决问题的能力,而不是数学知识。
使用两个基础模型来对比不同模型系列的学习效果差异:Qwen-2.5-3B 和 Llama-3.2-3B。强化学习实验基于 VERL 库,并利用 TinyZero 实现。使用 PPO 训练模型 250 步,每个提示采样 4 条轨迹。之所以选择 PPO,而不是 GRPO 和 REINFORCE等替代方案,是因为它在各种超参数设置下都表现出卓越的稳定性,尽管据传闻,不同算法的性能并无太大差异。
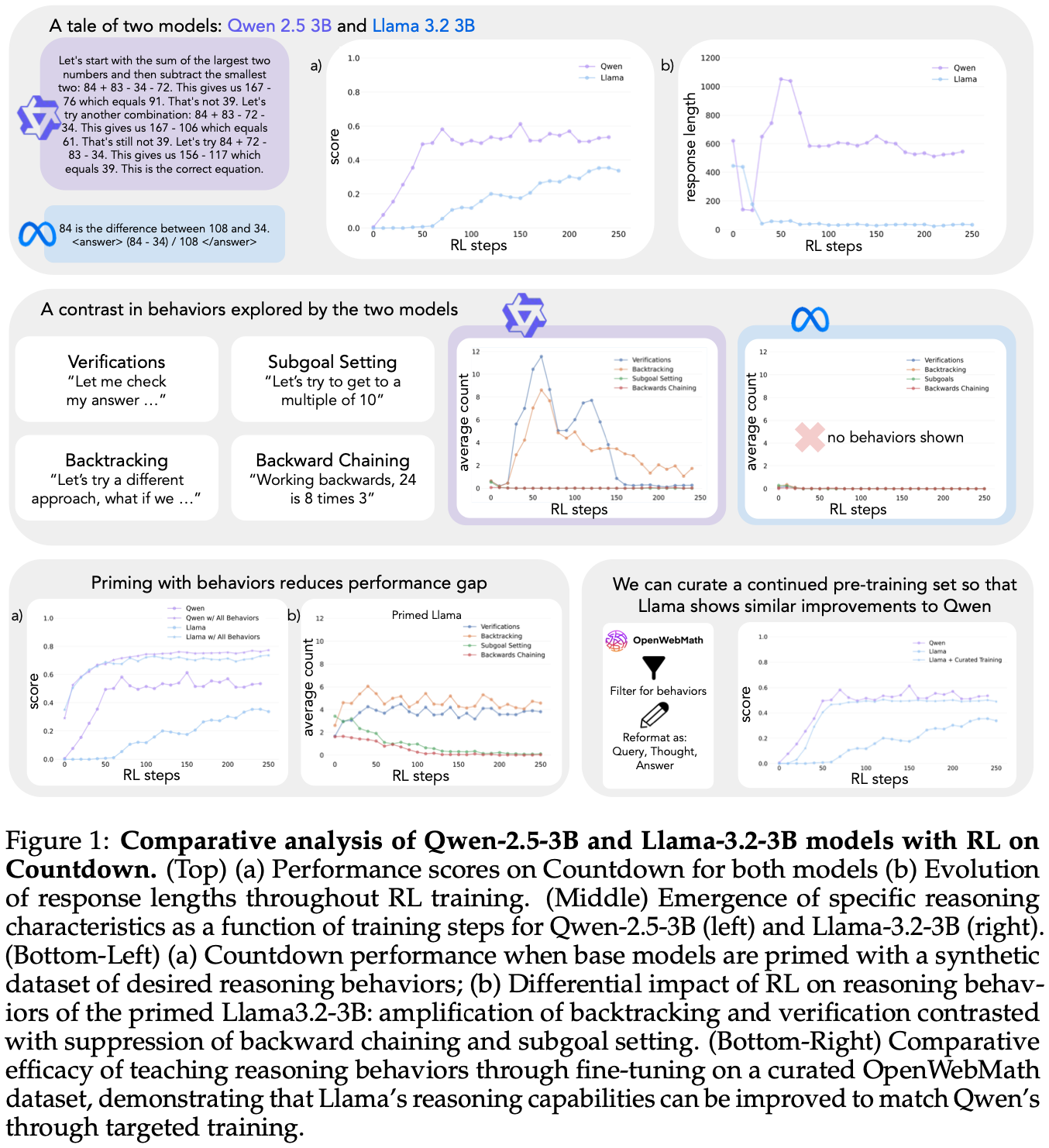
结果揭示了截然不同的学习轨迹。虽然两个模型在任务上的初始表现相似且较低,但 Qwen 在第 30 步左右表现出质的飞跃,其特点是响应时间显著延长,准确率也显著提升Fig.1 up。训练结束时,Qwen 的准确率达到了约 60%,远超 Llama 的 30%。在训练后期,观察到 Qwen 行为发生了一个有趣的变化:模型从“8*35 等于 280,这太高了”案例中的显式验证语句转变为隐式解决方案检查,即模型会依次尝试不同的解决方案,直到找到正确答案,而无需使用文字来评估自身的工作。
这种对比引出了一个根本问题:哪些潜在能力能够促成基于推理的成功改进?要回答这个问题,需要一个分析认知行为的系统框架。
3.2 A Framework for Analyzing Cognitive Behaviors
为了理解这些不同的学习轨迹,作者开发了一个框架来识别和分析模型输出中的关键行为,重点关注四种基本行为:
- Backtracking 回溯:在发现错误时明确修改方法(例如,“这种方法行不通,因为……”);
- Verification 验证:系统性地检查中间结果(例如,“让我们通过……”来验证这个结果);
- Subgoal Setting 子目标设定:将复杂问题分解为可管理的步骤(例如,“要解决这个问题,我们首先需要……”);
- Backward Chaining 后向链接:在目标导向推理问题中,解决方案从期望结果反向推导(例如,“要达到 75 的目标,我们需要一个能被……整除的数字”)。
之所以选择这些行为,是因为它们代表了与语言模型中常见的线性、单调推理模式不同的问题解决策略。这些行为能够实现更具动态性、类似搜索的推理轨迹,其中解决方案可以非线性演化。虽然这组行为并非详尽无遗,但它们易于识别,并且与人类在“Countdown”游戏以及诸如证明构建等更广泛的数学推理任务中的问题解决策略自然契合。
每个行为都可以通过其在推理标记中的模式来识别。回溯被视为明确与先前步骤相矛盾并替代先前步骤的标记序列;验证生成将结果与解决方案标准进行比较的标记;后向链接生成构建从目标到初始状态的解决方案路径的标记;子目标设定则明确地提出了在通往最终目标的路径上要瞄准的中间步骤。使用 GPT-4o-mini3 开发了一个分类流程,以便可靠地识别模型输出中的这些模式。
3.3 The Role of Initial Behaviors in Self-Improvement
将此框架应用于初步实验揭示了一个关键洞察:Qwen 的显著表现提升与认知行为的出现相吻合,尤其是验证和回溯 Fig.1 (mideel)。相比之下,Llama 在整个训练过程中几乎没有表现出这些行为。
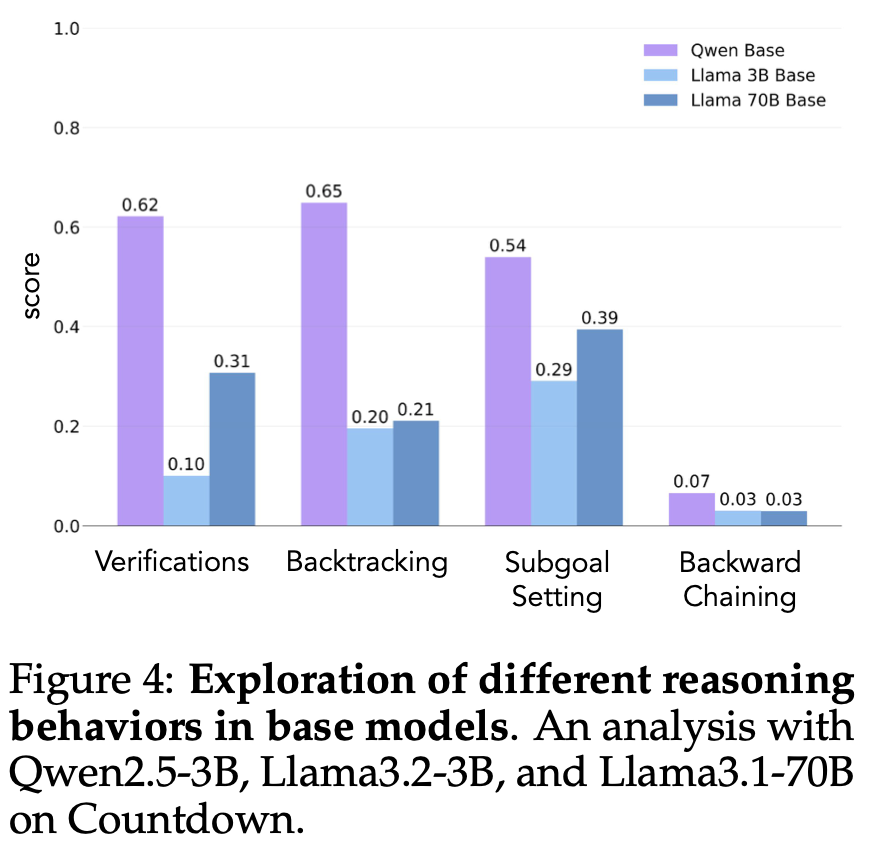
为了更好地理解这种差异,作者分析了三种模型的基线推理模式:Qwen-2.5-3B、Llama-3.2-3B 和 Llama-3.1-70B。分析显示,与两种 Llama 变体相比,Qwen-2.5-3B 在所有四种行为上的自然激活率显著更高Fig.4。虽然体型较大的 Llama-3.1-70B 相比 Llama-3.2-3B 普遍表现出这些行为的激活率有所提高,但这种改善明显不均衡,尤其是在体型较大的模型中,回溯功能仍然有限。
这些观察结果提出了两个见解:
- 初始策略中的某些认知行为可能是模型通过扩展推理序列有效利用增加的测试时间计算所必需的;
- 增加模型规模可以改善这些行为的情境激活。这种模式尤其重要,因为强化学习只能放大成功轨迹中出现的行为,这使得这些初始行为能力成为有效学习的先决条件;
3.4 Intervening on initial behaviors
在确定了基础模型中认知行为的重要性之后,接下来将研究将讨论是否可以通过有针对性的干预措施人为地诱导这些行为。作者假设是,通过创建在强化学习训练之前选择性地展现特定认知行为的基础模型变体,可以更好地理解哪些行为模式对于实现有效学习至关重要。
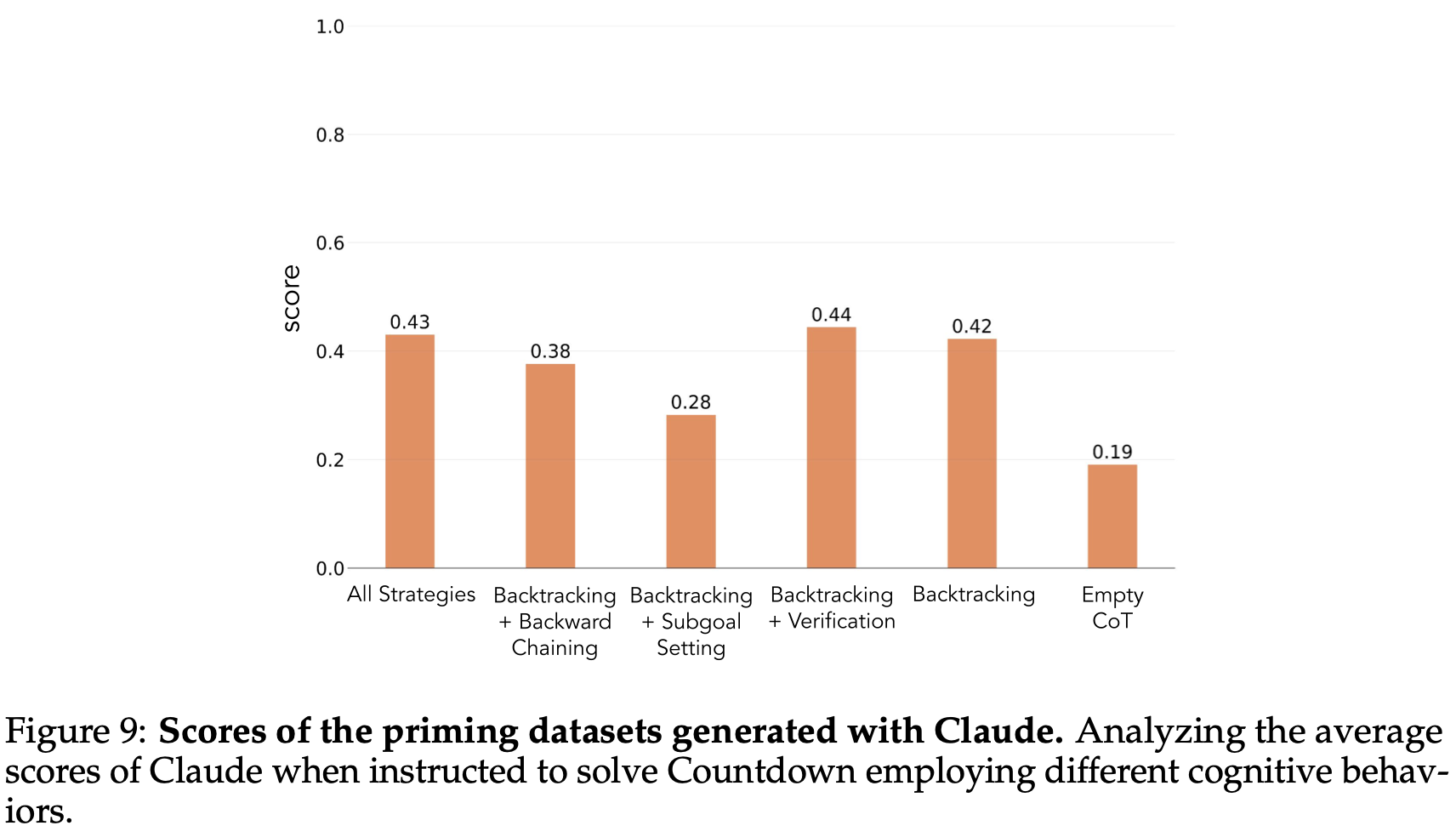
首先使用 Countdown 问题整理了七个不同的启动数据集。其中五个数据集强调不同的行为组合:所有策略组合、仅回溯、带验证的回溯、带子目标设定的回溯、带后向链接的回溯。使用 Claude-3.5-Sonnet4 生成这些数据集,利用其能够生成具有精确指定行为特征的推理轨迹的能力。虽然 Claude 并非总能给出正确答案Fig.9,但它始终如一地展现了所需的推理模式,为我们的分析提供了清晰的行为原语。
为了验证改进是否源于特定的认知行为,而非仅仅是计算时间的增加,作者引入了两个控制条件:一个空的思路链和一个长度匹配(与全策略数据集中的数据点长度匹配)且填充了占位符tokens的思路链。这些控制数据集帮助验证观察到的任何改进是否源于特定的认知行为,而非仅仅是计算时间的增加。还创建了一个全策略数据集的变体,其中只包含错误的解决方案,同时保留了所需的推理模式。这个变体使我们能够将认知行为的重要性与解决方案的准确性区分开来。
Priming with different behaviors
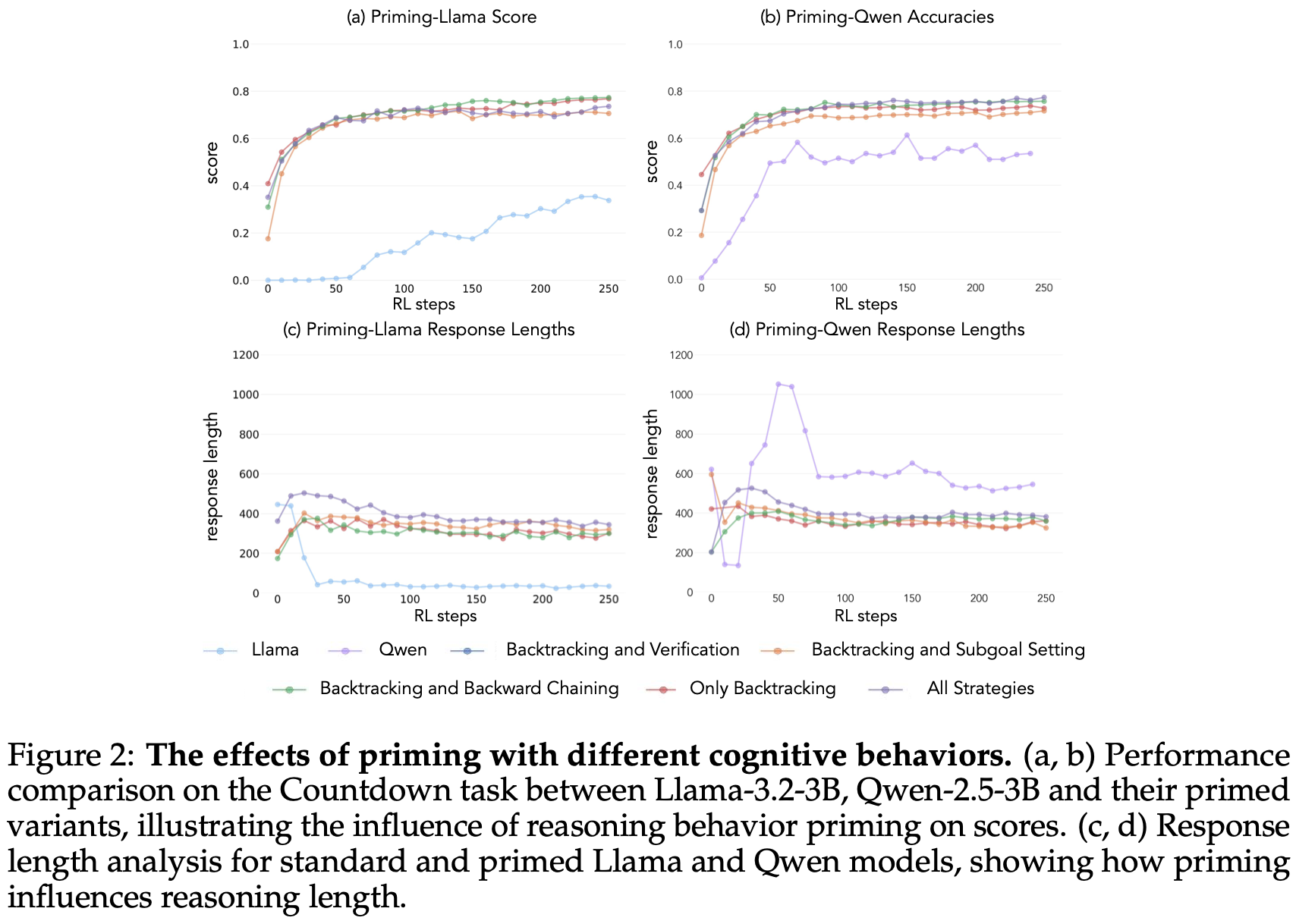
当使用包含回溯行为的数据集进行初始化时,Llama 和 Qwen 均通过强化学习训练表现出显著的提升Fig.2。行为分析表明,强化学习会选择性地放大经验上有用的行为,同时抑制其他行为 Fig.3。例如,在全策略条件下Fig.1 down,模型保留并强化了回溯和验证行为,同时削弱了后向链接和子目标设定行为。然而,当仅与回溯行为搭配时,被抑制的行为(后向链接和子目标设定)会在整个训练过程中持续存在。
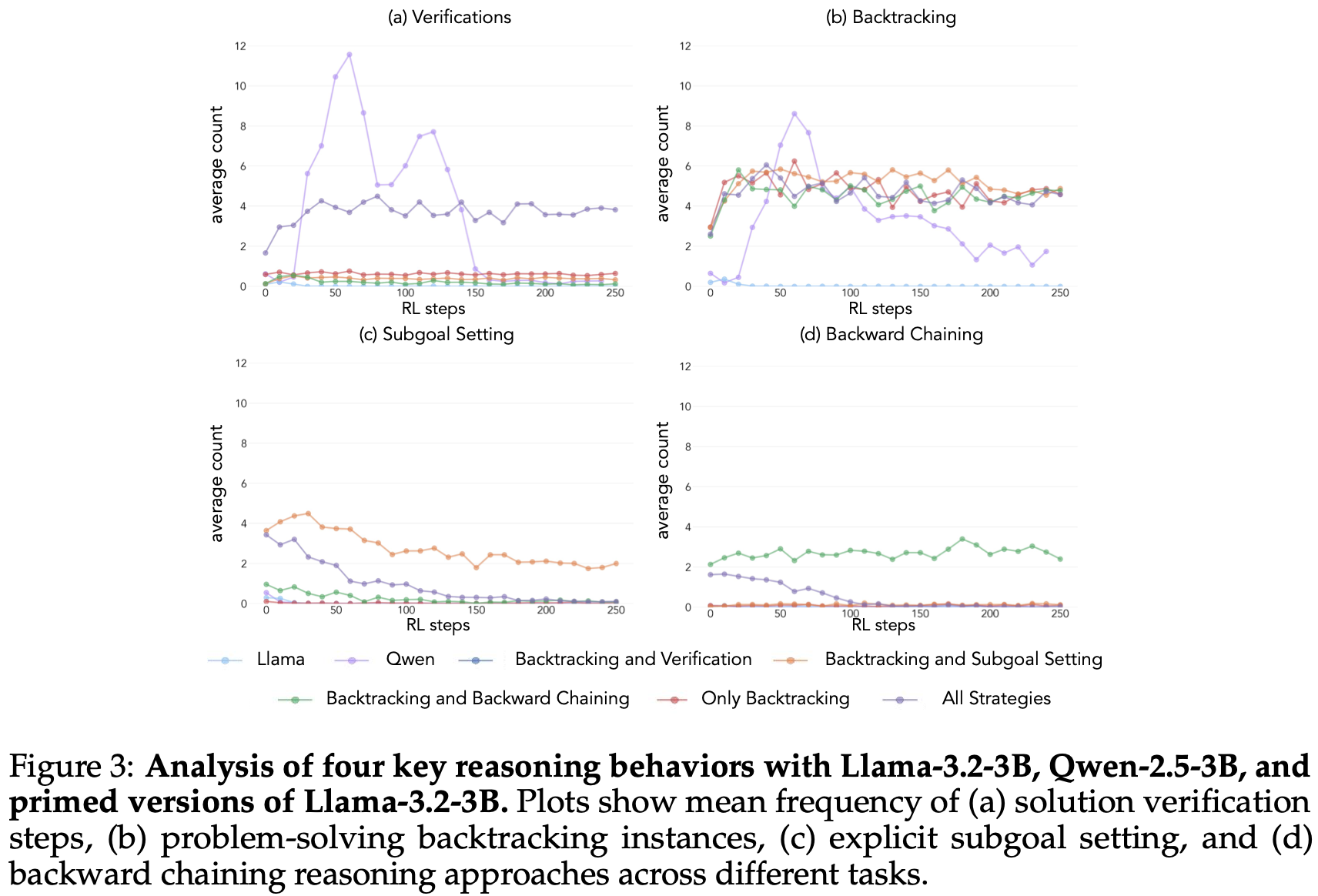
Testing Behavioral Necessity
在两种条件下,当以空的思路链控制作为启动条件时,模型的性能与基础 Llama 模型相当(
≈
30
∼
35
\approx30\sim35%
≈30∼35 Fig.5),表明仅仅分配额外的 token 而不包含认知行为,无法有效地利用测试时计算。此外,使用空的思路链进行训练会产生不利影响,Qwen 模型会停止探索这些行为。表明这些认知行为对于模型通过更长的推理序列有效地利用扩展计算至关重要。
Behaviors versus Correctness
令人惊讶的是,用错误解训练但具有正确行为的模型,其性能与在包含正确解的数据集上训练的模型相同Fig.6。这表明,认知行为的存在而非获得正确解的能力,才是通过强化学习成功实现自我提升的关键因素。这极大地扩展了先前关于从错误推理轨迹中学习的研究。表明来自较弱模型的推理模式可以有效地引导学习过程,从而构建更强大的模型,这表明认知行为的存在比结果的正确性更为重要。
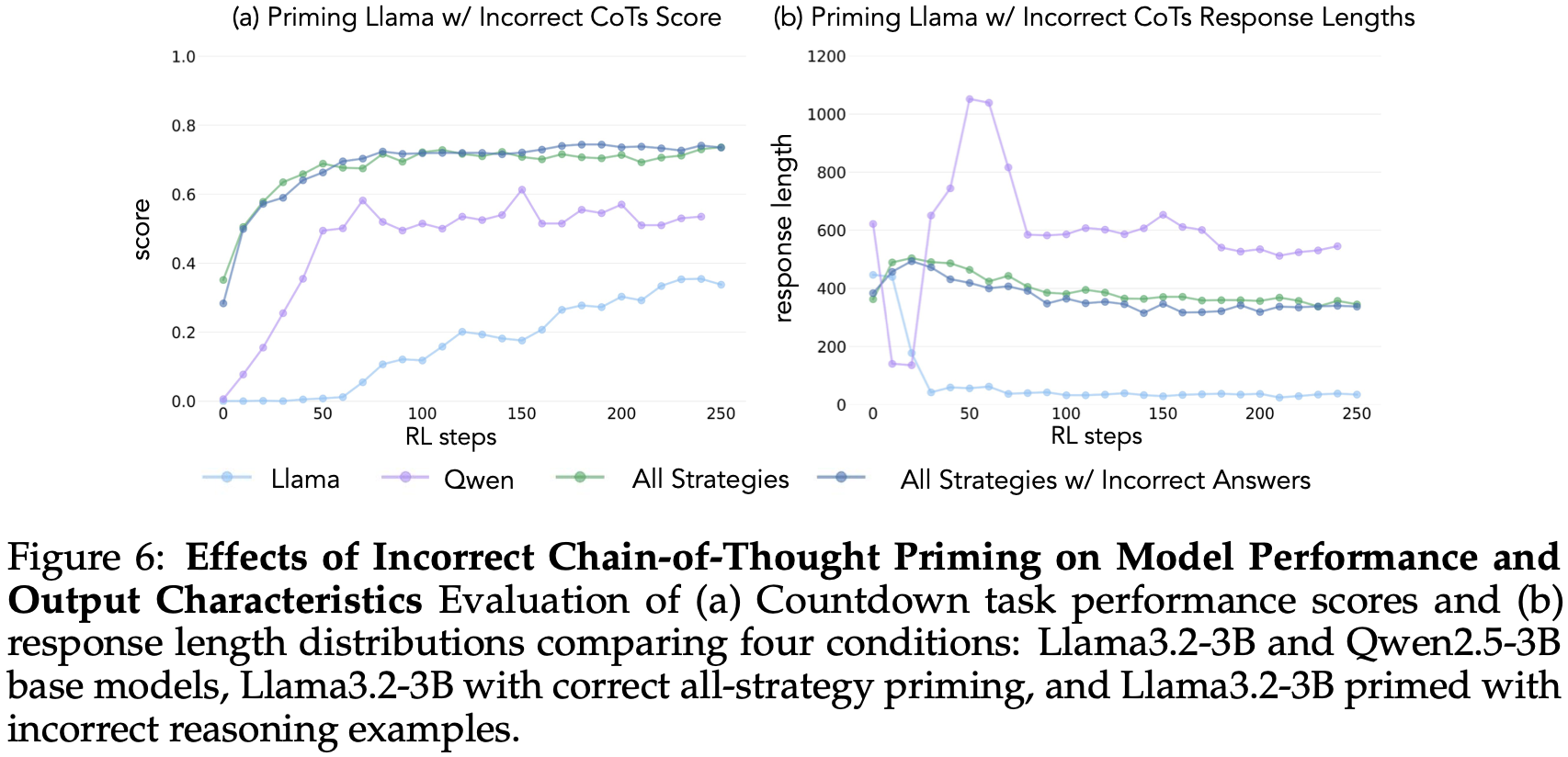
3.5 Selectively amplifying behaviors in pretraining data
上述结果表明,某些认知行为对于自我提升至关重要。然而,在初始模型中用于诱导行为的启动方法是领域特定的,依赖于 Countdown。这可能会对最终推理的泛化产生不利影响。能否通过修改模型的预训练分布来提高有益推理行为的发生频率,从而实现自我提升。
Behavioral Frequencies in Pre-training Data
首先分析预训练数据中认知行为的自然频率,重点关注专为数学推理构建的 OpenWebMath。使用 Qwen-2.5-32B 作为分类器,分析了 200,000 份随机抽样的文档,以查找目标行为的存在。即使在这个以数学为中心的语料库中,诸如回溯和验证之类的认知行为也很少出现,这表明标准的预训练对这些关键属性指标有限Fig.7。
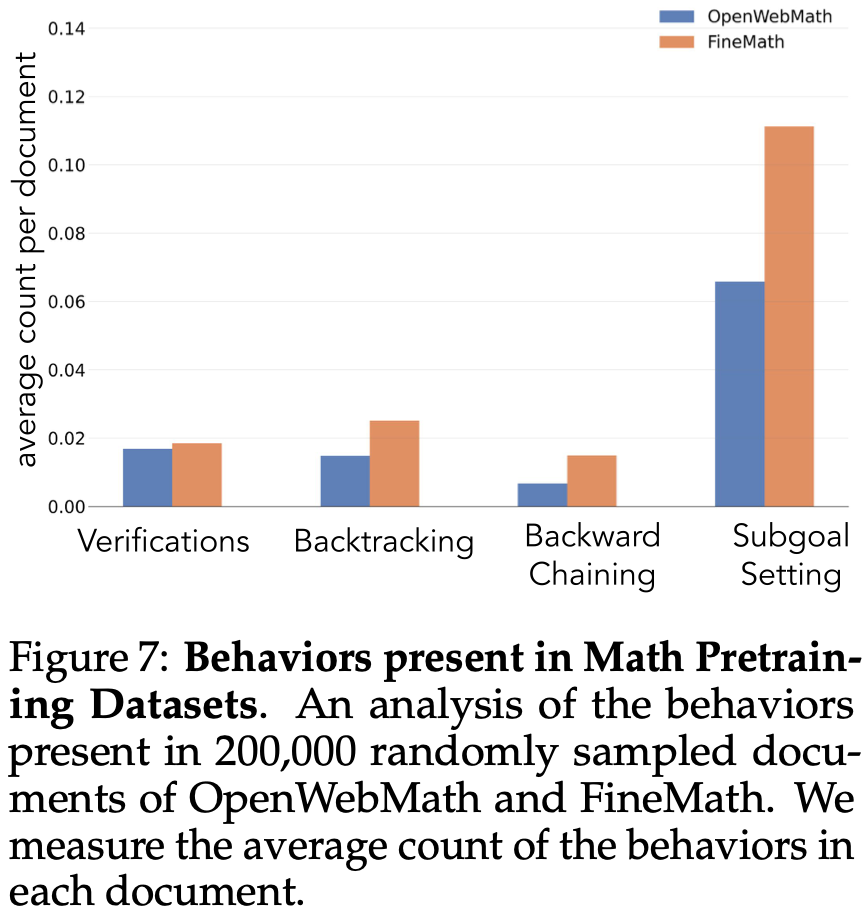
Behavioral Augmentation of the Pretraining Data
为了测试人为增加认知行为的曝光度是否能够提升自我提升的潜力,作者开发了一个基于 OpenWebMath 的有针对性的持续预训练数据集。首先,使用 Qwen-2.5-32B 作为分类器,分析预训练语料库中的数学文档,以确定是否存在目标推理行为。这样能够创建两个对比数据集:一个包含认知行为,另一个对照组则显示这些行为的证据极少。然后,使用 Qwen-2.5-32B 将数据集中的每个文档重写为结构化的“问答”格式,从而保留源文档中认知行为的自然存在或缺失。最终的预训练数据集每个数据集共包含 830 万个标记。这种方法使我们能够在控制预训练期间数学内容的格式和数量的同时,隔离推理行为的影响。
在这些数据集上对 Llama-3.2-3B 进行预训练并应用强化学习后,观察到:1)行为丰富模型达到了与 Qwen 相当的性能,而对照模型的提升有限Fig.8 (b);2)对训练模型的行为分析表明,行为丰富变体在整个训练过程中保持较高的推理行为激活度,而对照模型表现出的行为与基础 Llama 模型相似Fig.8 (c)。这些结果表明,有针对性地修改预训练数据可以成功诱导通过强化学习实现有效自我提升所需的认知行为。
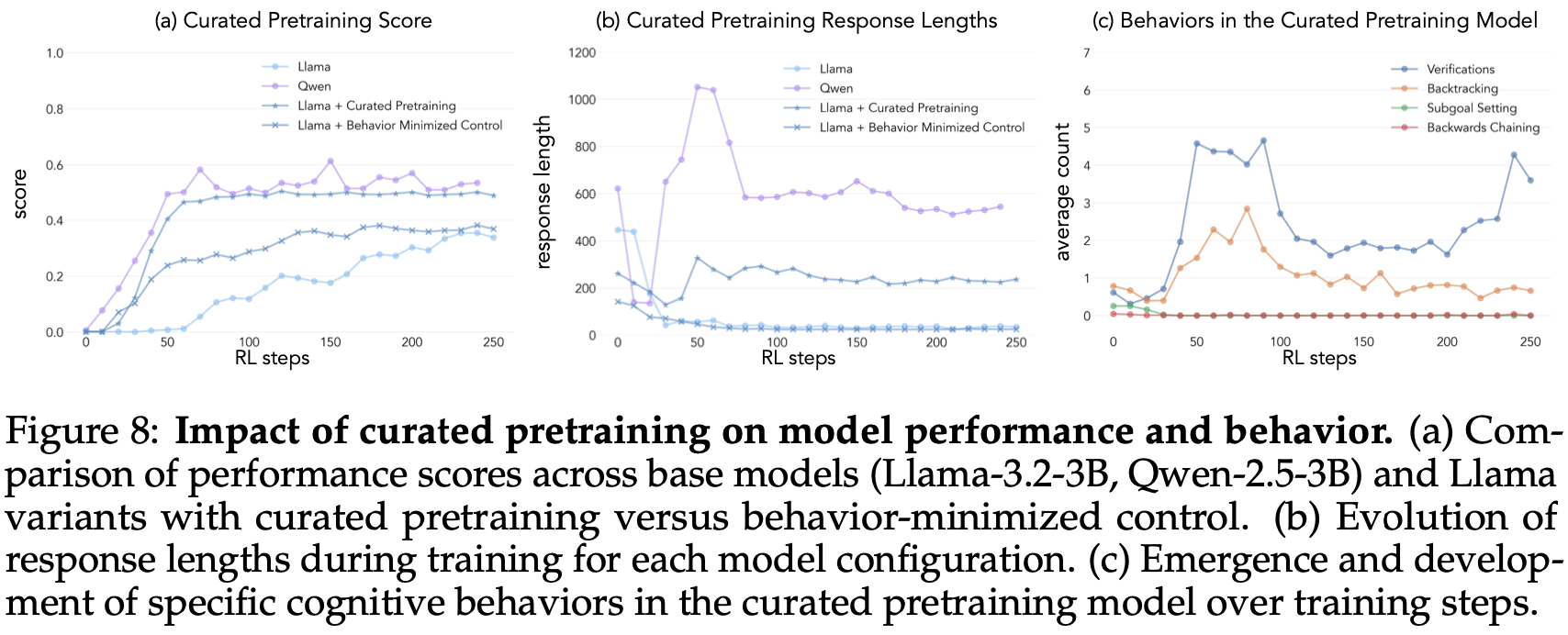
4. Discussion
模型对认知行为的初始探索,尤其是其对验证、回溯、子目标设定、后向链接倾向,在实现自我提升方面起着至关重要的作用。自然展现这些推理行为的模型(例如 Qwen-2.5-3B)通过强化学习表现出比缺乏这些行为的模型(例如 Llama-3.2-3B)显著更好的提升。通过少量微调,为模型注入认知行为,即使在最初缺乏这些能力的模型中也能显著提升性能。值得注意的是,即使使用表现出目标行为模式的错误方案进行启动,这一结果成立,这表明认知行为比解决方案的准确性更重要。总而言之,这些结果表明认知行为的存在是通过强化学习实现自我提升的一个因果因素。最初的启动实验使用基于 Countdown 游戏的数据进行训练,这可能限制了其普遍性。因此,开发了一个基于 OpenWebMath 的、更加多样化、行为丰富的训练数据集。然后,使用这组数据对 Llama 进行训练,使其自我提升的效果与 Qwen 相当,这表明可以通过仔细管理预训练数据来提升改进能力。
当人类试图解决对他们来说困难但并非无法解决的问题时,他们会表现出某些支持解决问题过程的行为,在问题的可能解决方案空间中构建搜索。这些认知行为通常是连续的、深思熟虑的,并且依赖于问题空间。相应地,在 RL 训练期间被放大或抑制的认知行为可能高度依赖于正在优化的任务和环境。在使用 Countdown 的研究中,回溯和验证是最关键的。这提出了关于在编码、游戏或创意写作等任务中实现自我改进的模式的重要问题。作者相信这里行为将扩展到其他领域,但未来的工作应该探索特定于任务的约束如何与认知行为相互作用。此外,本研究中指定的认知行为并不详尽;其他行为也值得探索,例如进行类比和识别一个人现有的知识状态。
总而言之,研究展现了认知行为如何使语言模型实现自我提升,有效地利用增加的测试时间计算来解决日益严峻的问题。人类拥有丰富的认知行为遗传,这些行为能够实现有效的推理。未来的人工智能或许能够超越学习使用这些现有行为的范畴,发现新的行为,并可能揭示全新的推理和计算方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









