







 本文介绍了如何使用pyspider自定义爬虫抓取指定网页的数据,包括标题、标签、描述和图片URL。详细讲述了如何从首页获取详情页URL,再到详情页抓取所需信息。数据抓取后,将其存储到本地的MongoDB数据库,通过配置`config.json`文件,并重载`on_result`函数实现数据保存。最后,文章提供了进一步学习和实践pyspider的可能性。
本文介绍了如何使用pyspider自定义爬虫抓取指定网页的数据,包括标题、标签、描述和图片URL。详细讲述了如何从首页获取详情页URL,再到详情页抓取所需信息。数据抓取后,将其存储到本地的MongoDB数据库,通过配置`config.json`文件,并重载`on_result`函数实现数据保存。最后,文章提供了进一步学习和实践pyspider的可能性。
自定义爬取指定数据
接下来我们通过自定义来抓取我们需要的数据,目标为抓取这个页面中,每个详情页内容的标题、标签、描述、图片的url、点击图片所跳转的url。


点击首页中的 project name > reo,跳转到脚本的编辑界面

获取所有详情页面的url
index_page(self, response) 函数为获取到 www.reeoo.com 页面所有信息之后的回调,我们需要在该函数中对 response 进行处理,提取出详情页的url。
通过查看源码,可以发现 class 为 thum 的 div 标签里,所包含的 a 标签的 href 值即为我们需要提取的数据,如下图
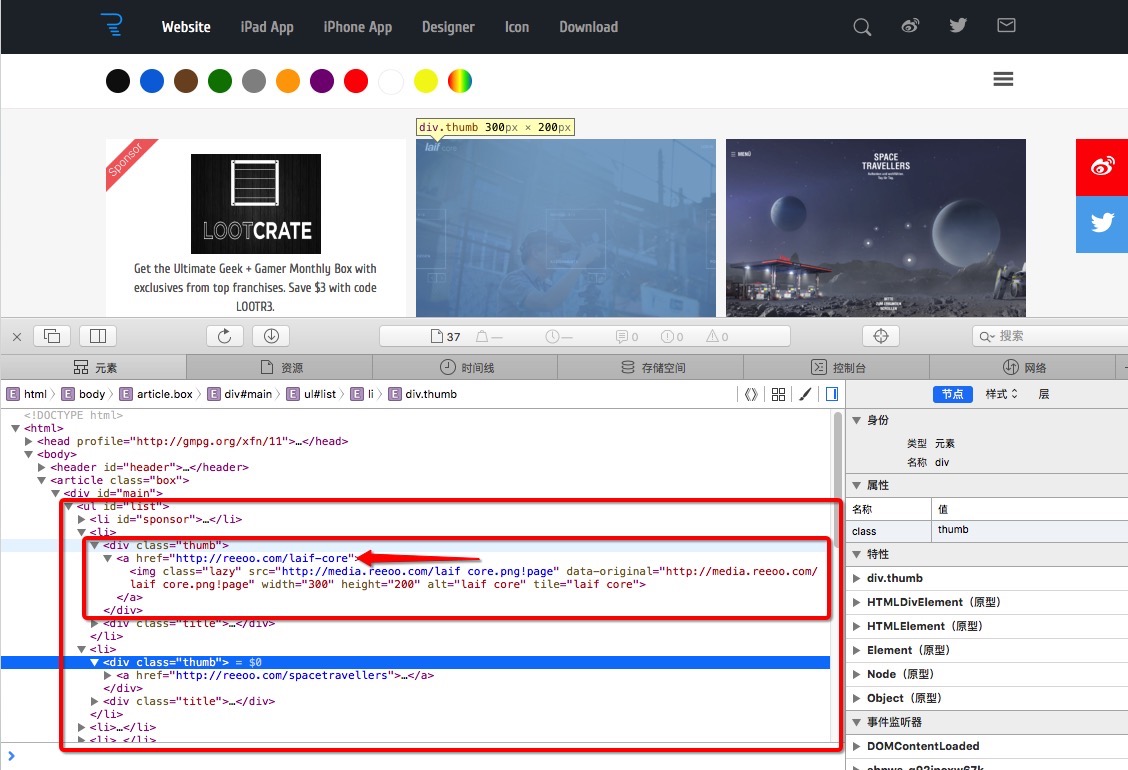
代码的实现
-
def index_page(self, response): -
for each in response.doc('div[class="thumb"]').items(): -
detail_url = each('a').attr.href -
print (detail_url) -
self.crawl(detail_url, callback=self.detail_page)
response.doc(‘div[class=”thumb”]’).items() 返回的是所有 class 为 thumb 的 div 标签,可以通过循环 for…in 进行遍历。
each(‘a’).attr.href 对于每个 div 标签,获取它的 a 标签的 href 属性。
可以将最终获取到的url打印,并传入 crawl 中进行下一步的抓取。
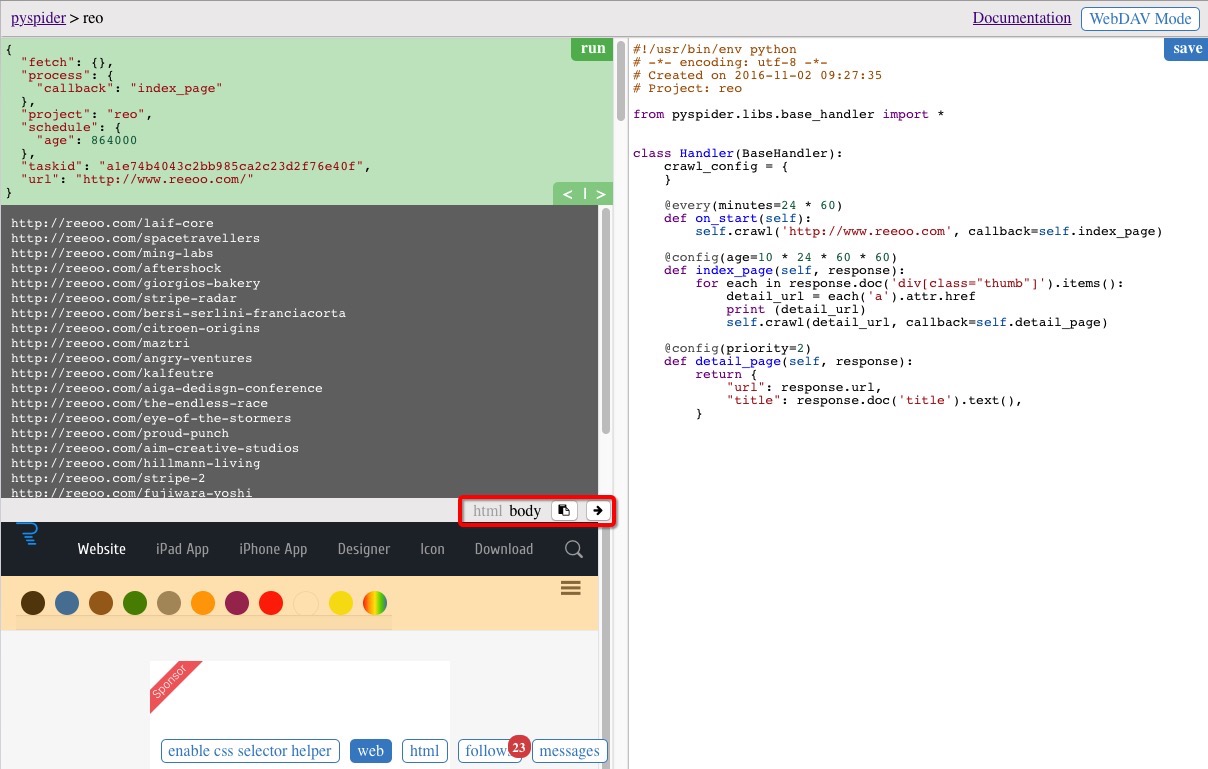
点击代码区域右上方的 save 按钮保存,并运行起来之后的结果如下图,中间的灰色区域为打印的结果

注意左侧区域下方的几个按钮,可以展示当前所爬取页面的一些信息,web 按钮可以查看当前页面,html 显示当前页面的源码,enable css selector helper 可以通过选中当前页面的元素自动生成对应的 css 选择器方便的插入到脚本代码中,不过并不是总有效,在我们的demo中就是无效的~

抓取详情页中指定的信息
接下来开始抓取详情页中的信息,任意选择一条当前的结果,点击运行,如选择第一个
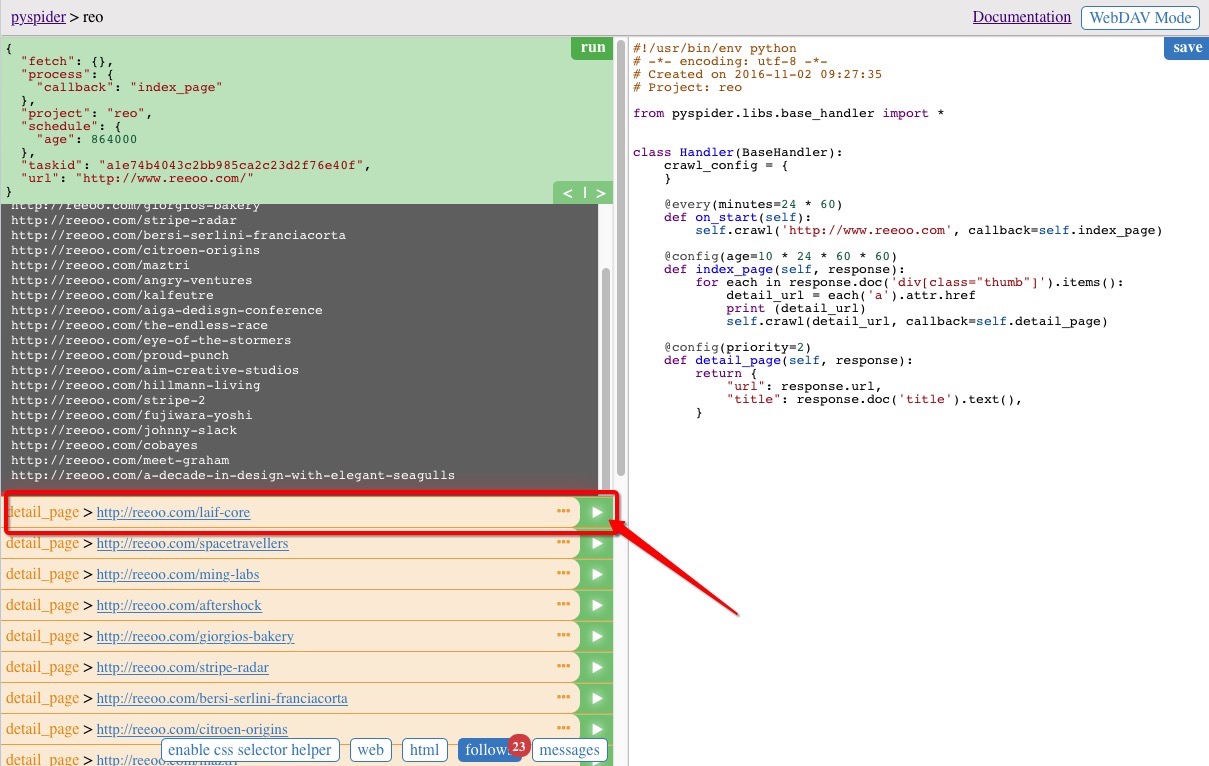
实现 detail_page 函数,具体的代码实现:
-
def detail_page(self, response): -
header = response.doc('body > ar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









