






机器学习
基本流程
- 数据获取 :大量数据
- 数据预处理:归一化,离散化、去除共线性(清洗数据,提高算法效果)
- 特征工程:筛选显著特征,摒弃无用特征(数据和特征工程决定机器学习上限,算法决定模型上限)
- 机器学习(模型训练):选模型,调参优化
- 模型评估(效果预测):过拟合、欠拟合;精准率(P),召回率(F)
机器学习算法分类
监督学习
数据集全部包含标签,标签在学习过程中起监督作用(猫、狗、兔子)
房价预测,图像分析
无监督学习
数据集全部没有标签(自主学习数据映射关系。没有标签主要是因为数据太乱、标注成本高、区分难度大)
客户分类、购物行为分析
半监督学习
部分数据集包含标签;对小部分数据起监督作用(通过已知标签的小部分数据,使用所有数据样本)
文本分类、
强化学习
基于环境的反馈行动,通过不断与环境交互,最终完成特定目标。
无人驾驶
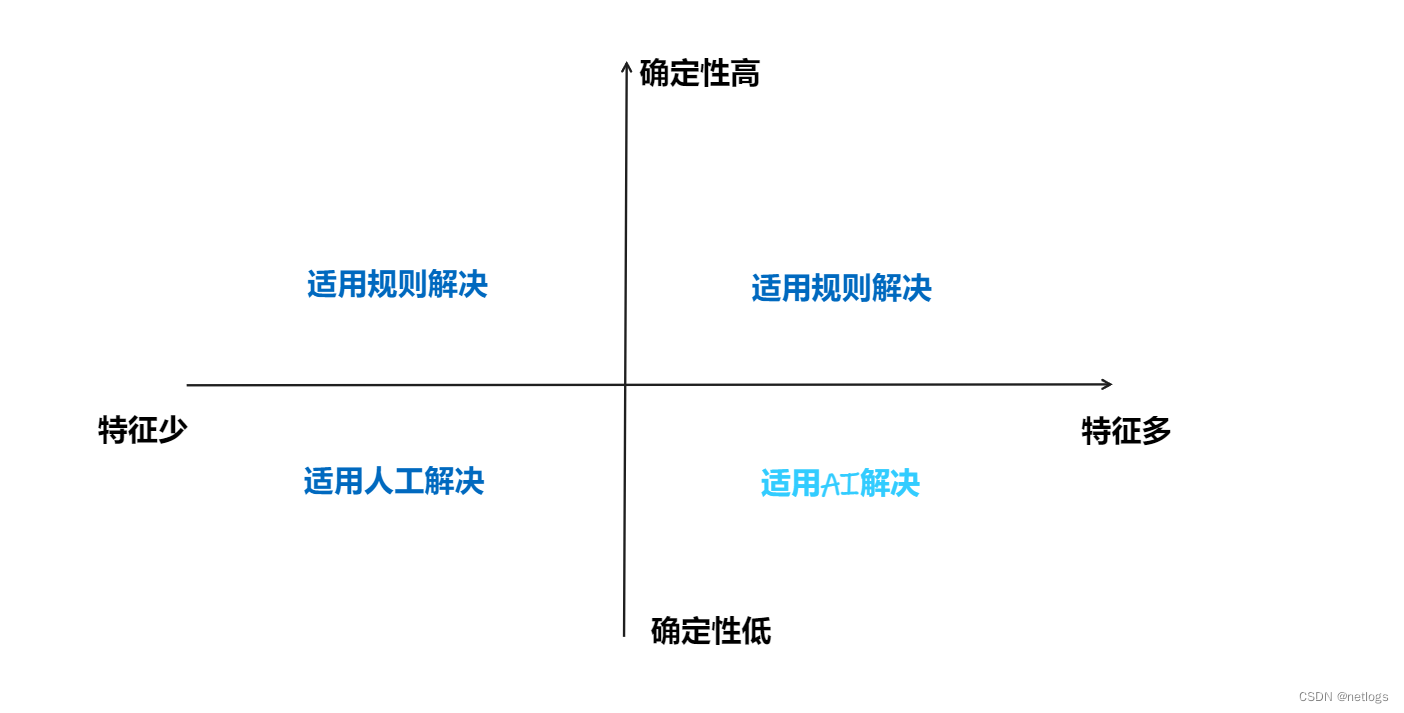
机器学习场景适用性
适用场景
- 有大量经验数据或者特征可以借鉴;
- 应用场景和条件简单清晰,比如下棋
- 寻找最优解比较慢或者复杂的时候
- 文本翻译等感知性问题
不适用场景
- 缺乏数据系统训练
- 准确计算、或者有明确映射关系
- 逻辑证明
深度学习十问
- 神经网络由什么构成
- 为何分层,我们期待中间层做什么
- 中间的“连线”是在干什么
- 这个网络参数量有多大
- 层与层之间如何互相影响
- ”正向传播“这么复杂?编程困难吗?
- 从0到部署模型,有哪些步骤
- 深度学习和传统机器学习算法有哪些优势?
- 深度学习繁荣的关键?
深度学习场景
- cv
- NLP














 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









