







官方仓库:
https://github.com/protocolbuffers/protobuf/releases/tag/v21.8
https://developers.google.com/protocol-buffers/docs/overview
protobuf是Google开源的一个跨平台的结构化数据存储格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式,当然,protobuf在使用中也存在弊端,比方说调用自身的序列化和反序列化函数会导致在模板参数传参时,导致非pb类型的参数引起的编译失败,所以如果为了序列化和反序列化,推荐使用cereal序列化工具,直接调用第三方的序列化字节流函数,减少类型之间的依赖
序列化和反序列化
在程序运行中,我们往往希望将数据存储到文件或者其他的进程,在传输之前,会将数据结构或对象以某种格式转化为字节流,该过程称之为序列化,将当前的状态进行保存,在需要时将数据进行复原,称之为反序列化。
在进行序列化和反序列化过程中,pb提供了可直接调用的库函数,而在序列化和反序列化中,需要有pb文件经过工具转化为cpp和.h文件,此时使用的协议为Protobuf协议。
Protobuf简介
Protobuf是Google开发的一种用于序列化结构化数据(比如Java中的Object,C中的Structure)的语言中立、平台中立、可扩展的数据描述语言,可用于数据存储、通信协议等方面。Protocol Buffers可以理解为是更快、更简单、更小的JSON或者XML,区别在于Protocol Buffers是二进制格式,而JSON和XML是文本格式。
目前protobuf支持的语言包括:C++、C#、Java、JS、OC、PHP、Ruby这七种。
相比较于XML、json,Protobuf的优点:
简洁,体积小,消息大小只需要json的10分之一,XML的20分之一;
速度快,解析速度比XML、json快20~100倍;
自动生成数据访问类,方便应用程序的使用。Protobuf编译器会将.proto文件编译生成对应的数据访问类;
向后兼容性好,不必破坏旧数据格式的程序就可以对数据结构进行升级。不必担心因为消息结构的改变而造成的大规模的代码重构或者迁移的问题。
相对而言,Protobuf缺点:
protobuf采用了二进制格式进行编码,可读性差;
protobuf并非自描述的,必须要有格式定义文件(.proto 文件)。
既然Protobuf可以自动生成数据访问类,也就是说,只要规定了.proto文件,可以直接生成C++的.cc文件和.h文件,可以直接生成python的.py文件,可以直接生成Java的.java文件……
Protobuf的下载安装
release版本:
https://github.com/protocolbuffers/protobuf/releases
linux下的地址
https://github.com/protocolbuffers/protobuf/releases/download/v3.8.0/protoc-3.8.0-linux-x86_64.zip
源码下载地址:
https://github.com/protocolbuffers/protobuf/archive/v3.8.0.tar.gz
Protobuf的使用
在使用Protobuf之前,需要提前创建一个.proto文件。在.proto文件中,需要定义要生成的数据访问类的成员信息等内容,
proto语法:
版本声明:
在编写.proto文件的最开始部分,需要指定.proto文件版本
syntax = "proto2"; //声明proto2版本(选其一)
syntax = "proto3"; //声明proto3版本(选其一)
定义message结构
使用message定义一个消息类型,与C++、Java等高级语言对应起来就可以理解为Class。
每个message通常由字段修饰符、字段类型、字段名、标识号组成。
以Person为例,在proto2中:
message Person {
required int32 id =1;
required string name = 2;
optional int32 age = 3;
repeated string email = 4;
}
字段修饰符:只有三种字段修饰符(required、optional、repeated),且每个字段必须有字段修饰符。
required:表示该字段的是必须设置的;
optional: 表示该字段的是可选设置的;
repeated: 表示该字段可以有多个值,一般会被编译为对应语言的集合类或数组。
但是,在proto3中,对这些规则做了一些的修改:
取消了required字段修饰符,optional字段修饰符可以省略;
移除了default选项;
repeated字段默认采用packed编码
proto3:
message Person {
string name = 1;
string phone = 2;
string email = 3;
repeated string address = 4;
}
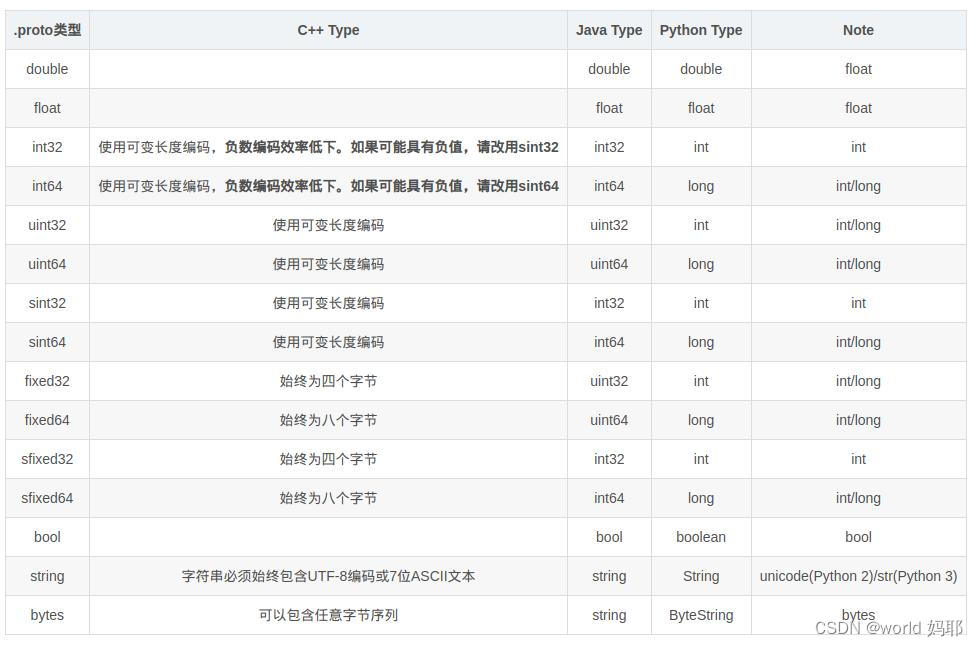
自定义数据类型
除了proto定义的数据类型之外,还可以指定自己定义的数据类型,甚至是枚举类型。
自己定义新的数据类型,只需要在.proto文件中定义新的message类型。枚举类型利用enum开头,需要注意枚举类型的第一个字段的标识号必须为0
在proto2中:
syntax = "proto2";
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2;
}
message Address {
optional string country = 1;
optional string detail = 2;
}
message Person {
required int32 id =1;
required string name = 2;
optional int32 age = 3;
repeated string email = 4;
repeated PhoneNumber phone = 5;
optional Address address = 6;
}
在proto3中:
syntax = "proto3";
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
message Address {
string country = 1;
string detail = 2;
}
message Person {
int32 id =1;
string name = 2;
int32 age = 3;
repeated string email = 4;
repeated PhoneNumber phone = 5;
Address address = 6;
}
proto转换:
linux:
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/addressbook.proto
windows:
protoc -I=C:\Users\Downloads\protoc-21.8-win64\bin --cpp_out=C:\Users\Downloads\protoc-21.8-win64\bin C:\Users\Downloads\protoc-21.8-win64\bin\Demo.proto
./protoc 指定.proto文件 --cpp_out=./
./protoc 指定.proto文件 --java_out=./
./protoc 指定.proto文件 --python_out=./
序列化、反序列化
bool ParseFromIstream(std::istream* input);
bool SerializeToOstream(std::ostream* output) const;
bool ParseFromString(const std::string& data);
bool SerializeToString(std::string* output) const;
bool SerializeToArray(void* data, int size) const;
std::string GetTypeName() const override;
size_t ByteSizeLong() const override;
















 7210
7210











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









