







 文章详细介绍了Java中Object类的equals和hashCode方法,以及它们在子类重写时的应用。重点讲述了如何正确重写equals方法,以及hashCode的重要性及其在哈希表中的作用,强调了equals和hashCode一致性在数据结构如HashMap和HashSet中的必要性。
文章详细介绍了Java中Object类的equals和hashCode方法,以及它们在子类重写时的应用。重点讲述了如何正确重写equals方法,以及hashCode的重要性及其在哈希表中的作用,强调了equals和hashCode一致性在数据结构如HashMap和HashSet中的必要性。
Object类
Object类是所有类的父类,所以:
-
Object的类的成员变量和成员方法,其余的类会继承,可以使用
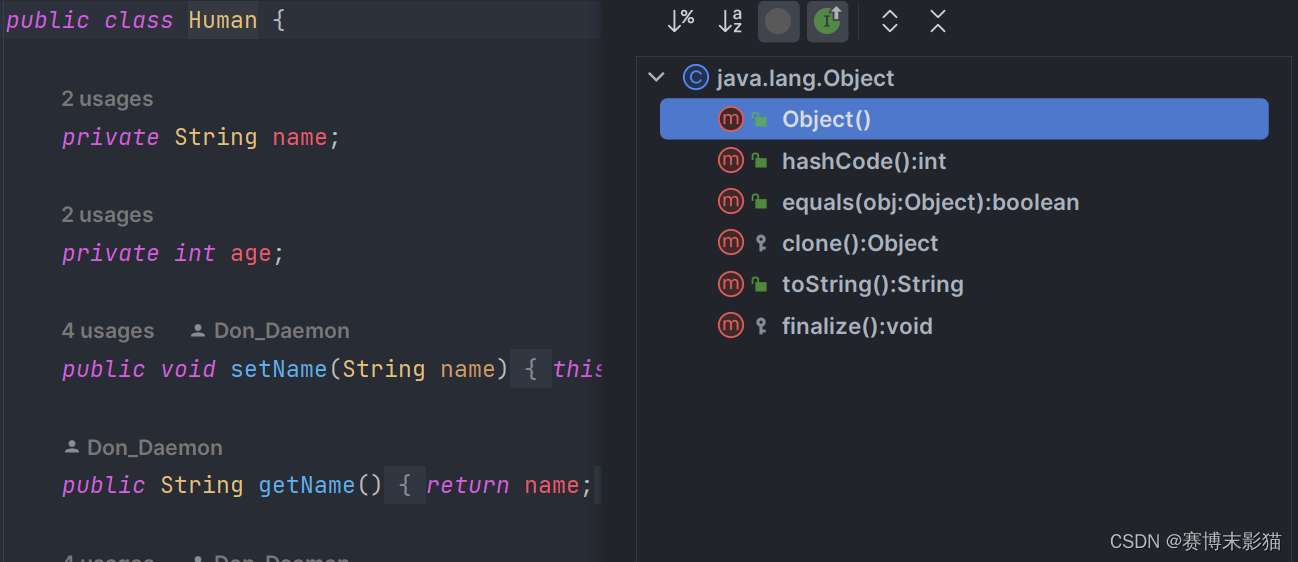
-
Object类可以使用多态创建任意对象,同时拥有子类的重写方法
我们先假设子类重写了equals方法和hashCode方法(IDEA默认的重写)
public class Human {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Human)) return false;
Human human = (Human) o;
if (getAge() != human.getAge()) return false;
return getName() != null ? getName().equals(human.getName()) : human.getName() == null;
}
@Override
public int hashCode() {
int result = getName() != null ? getName().hashCode() : 0;
result = 31 * result + getAge();
return result;
}
}
此时我们调用equals方法
public class ObjectTest {
public static void main(String[] args) throws Throwable {
Object object = new Human();
Human human = new Human();
System.out.println(object.equals(human));
}
}
如果这里的equals使用的Object类的equals方法,肯定是false
但是实际上的执行结果是true
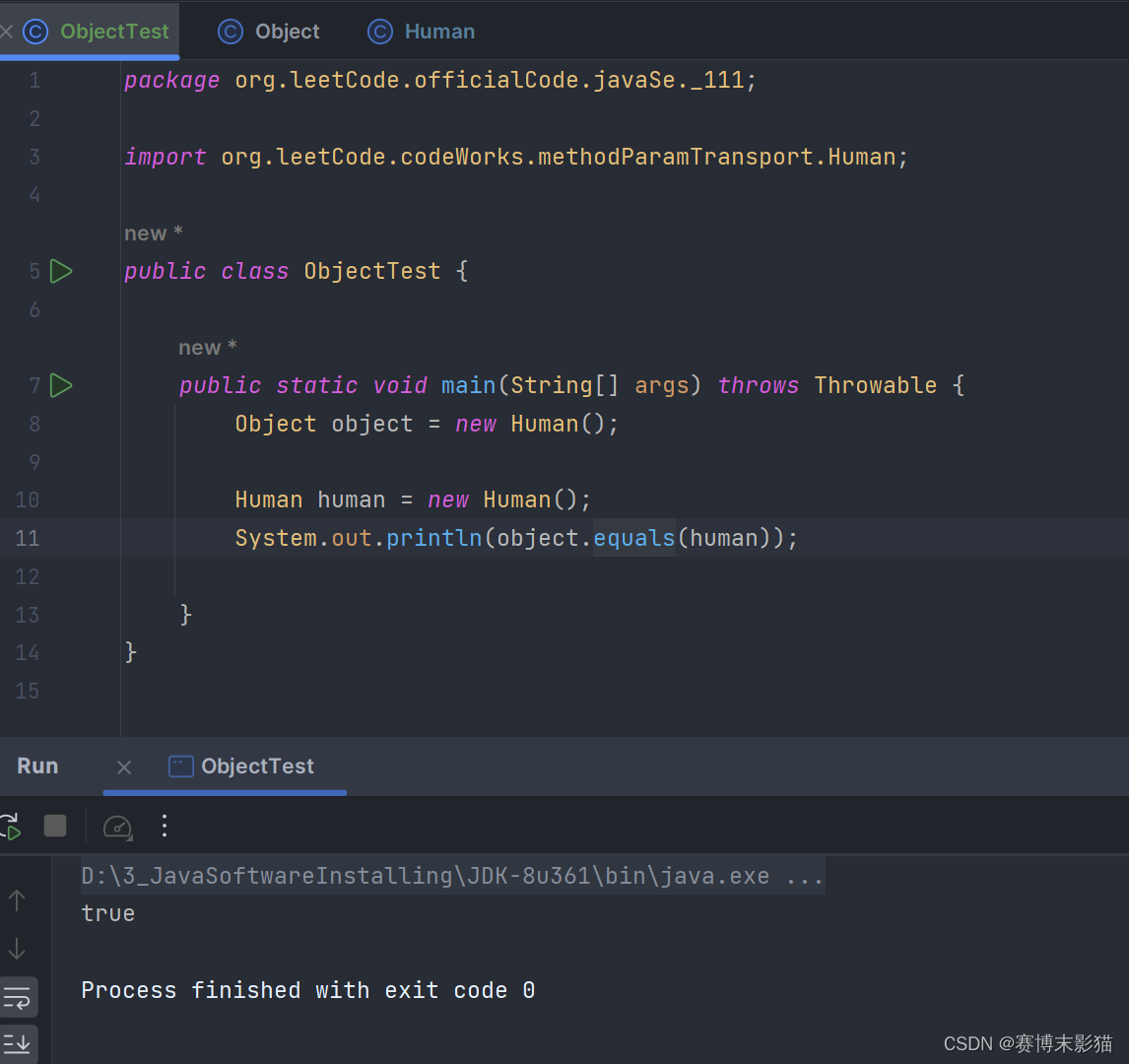
说明已经调用了子类重写之后的方法
equals方法
本质上是为了判断两个引用类型的对象/两个基本类型的数值是否相等
equals用于基本类型
判断两个数值是否相等
char a = 'a';
byte aa = 97;
System.out.println(a == aa);// 这里发生了自动类型提升,char和byte都可以无损失地转为int,a的ascii值就是97,所以是true
结果是true
equals用于引用类型
Human h1 = new Human();
h1.setAge(1);
h1.setName("rainbowSea");
Human h2 = new Human();
h2.setAge(1);
h2.setName("rainbowSea");
System.out.println(h1.equals(h2));
上面讲了,这里重写了,比较的是age和name的值是否相等,所以是true
如果不重写,比较的就是内存地址,必然是false
如何重写equals方法
但是怎么重写,其实大有讲究,我们以String类重写的equals方法以及Human类重写的equals方法为例,展开说说
String类的equals方法:
/**
* Compares this string to the specified object. The result is {@code
* true} if and only if the argument is not {@code null} and is a {@code
* String} object that represents the same sequence of characters as this
* object.
*
* @param anObject
* The object to compare this {@code String} against
*
* @return {@code true} if the given object represents a {@code String}
* equivalent to this string, {@code false} otherwise
*
* @see #compareTo(String)
* @see #equalsIgnoreCase(String)
*/
public boolean equals(Object anObject) {
// 先比较两个对象是否是同一个对象(即内存地址是否相等)
if (this == anObject) {
// 若相等,直接返回true
return true;
}
// 再比较两个对象的字符串值,这一步有很多技巧
// 1. 先判断这个对象是不是String类的对象,不是直接返回false
if (anObject instanceof String) {
// 2. 再判断两个字符串长度是否相等,不相等返回false
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
// 3. 是String对象,而且字符串长度也相等,没办法了,只能判断字符串内容了
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
// 不用比较全部的字符串,而是从头到尾逐个对比,发现不同直接返回false
if (v1[i] != v2[i])
return false;
i++;
}
// 内容相同,返回true
return true;
}
}
// 不是String类的对象
return false;
}
三部分筛选,环环相扣,逻辑严谨(写在前面的判断一定是后面判断的前提),代码简洁
强烈建议每一位读者多去读源码,不管是什么项目的,JDK,MySQL,Spring,MyBatis……都可以读,非常有帮助!
IDEA自动生成的equals方法
@Override
public boolean equals(Object o) {
// 1. 和String一样,先判断是不是相同引用
if (this == o) return true;
// 2. 再判断是不是这个类的对象
if (!(o instanceof Human)) return false;
Human human = (Human) o;
// 3. 先比较年龄,再比较姓名,使用三元运算符简化代码
if (getAge() != human.getAge()) return false;
return getName() != null ? getName().equals(human.getName()) : human.getName() == null;
}
hashCode方法
HashSet集合
可以用于去重,存取顺序不同
HashSet集合的add方法
HashSet可以去重,主要就是靠add方法实现
public static void main(String[] args) throws Throwable {
HashSet<Integer> hashSet = new HashSet<>();
hashSet.add(1);
hashSet.add(1);
System.out.println(hashSet);
}
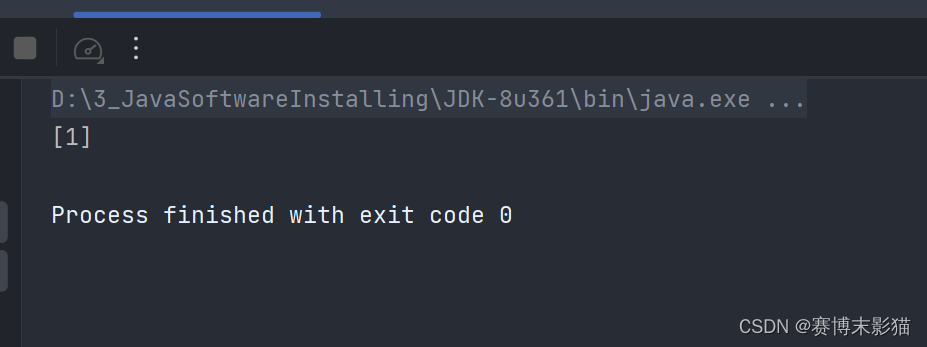
只有一个1,说明去重了
在调用HashSet的add方法时,会先进行判断,如果add的对象之前添加过,就不会添加进去,以此达到去重的目的
那么add方法是通过何种办法判断对象相等?它和hashCode方法又有什么关系呢?
源码讲解
add方法调用了put方法
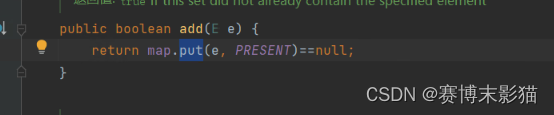
put方法又调用了putVal,putVal又调用了hash()

hash又调用了hashCode方法,null统一都是0,所以只能插入一次;不是null,则让对象的哈希值与哈希值无符号右移16位后的值进行异或运算,返回运算后的结果
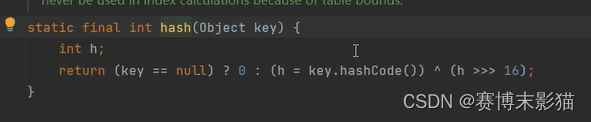
hashCode方法不能再往下点了,native表示用C++实现

看到这里我们可以大胆猜测,add方法能去重,就是因为每次添加的时候都会计算添加对象的hashCode方法的哈希值,如果计算的哈希值相等,就说明这是同一个对象,就不予添加;反之,则添加
hashCode可以将任何一个对象转化为一个int类型的值,相同的对象会转换位相同的哈希值,不同的对象会被映射成不同的哈希值
为什么重写equals方法后,一定要重写hashCode方法
Java当中比较对象/数值是否相等,一般有3种:==,equals,hashCode
==
==没什么好说的,比较基本类型数值的时候还算是有用,比较引用类型是否相等,就非常的强硬,只能比较地址,意思就是“如果两个对象不是同一个对象,那么这两个对象就是不相等的”
但是我们实际生活中,定义两个东西是不是相同的,概念没有这么严格,我买了两个盒装的13600kf的CPU,他们价格一样,性能参数一样,甚至体质和超频潜力都是一模一样的,尽管他们并不是同一个CPU,但是我们基本上都认为这两个CPU是“等价”的
其他的例子还有很多,在这里不再赘述
由此,我们引出了重写的equals方法
equals方法
只能用于引用类型的对象,不能用于基本类型
刚才说了,我们现实生活中,不会有这么严格的比较相等的标准,而重写Object的equals方法,就满足了我们的这个需求。当两个对象是同一个类的对象,并且所有的成员变量的属性值都是相等的,那么我们就可以认为,这两个对象是相等的
重写的equals方法,重写逻辑都是相同的:
- 是否是同一个对象引用
- 是否是同一个类型
- 逐个比较属性值是否相等
hashCode方法
既可以用于基本类型,也可以用于引用类型
hashCode源码简单分析
get_next_hash() 方法会根据 hashCode 的取值来决定采用哪一种哈希值的生成策略。
默认的hashCode为5
1~5分别是:随机数,根据内存指针计算,恒定2,自增,xor-shift算法
static inline intptr_t get_next_hash(Thread * Self, oop obj) {
intptr_t value = 0 ;
if (hashCode == 0) {
// 返回随机数
value = os::random() ;
} else
if (hashCode == 1) {
//用对象的内存地址根据某种算法进行计算
intptr_t addrBits = cast_from_oop<intptr_t>(obj) >> 3 ;
value = addrBits ^ (addrBits >> 5) ^ GVars.stwRandom ;
} else
if (hashCode == 2) {
// 始终返回1,用于测试
value = 1 ;
} else
if (hashCode == 3) {
//从0开始计算哈希值
value = ++GVars.hcSequence ;
} else
if (hashCode == 4) {
//输出对象的内存地址
value = cast_from_oop<intptr_t>(obj) ;
} else {
// 默认的hashCode生成算法,利用xor-shift算法产生伪随机数
unsigned t = Self->_hashStateX ;
t ^= (t << 11) ;
Self->_hashStateX = Self->_hashStateY ;
Self->_hashStateY = Self->_hashStateZ ;
Self->_hashStateZ = Self->_hashStateW ;
unsigned v = Self->_hashStateW ;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8)) ;
Self->_hashStateW = v ;
value = v ;
}
value &= markOopDesc::hash_mask;
if (value == 0) value = 0xBAD ;
assert (value != markOopDesc::no_hash, "invariant") ;
TEVENT (hashCode: GENERATE) ;
return value;
}
未被重写的hashCode方法,使用的就是5,也就是xor-shift算法,去生成伪随机数的哈希值
Marsaglia’s xor-shift 随机数生成法是一种快速并且散列性好的哈希算法
参考文章
Object中的hashCode()终于搞懂了!!!
JDK核心JAVA源码解析(9) - hashcode 方法
默认hashCode全局变量的值是5,也就是说会走到这里
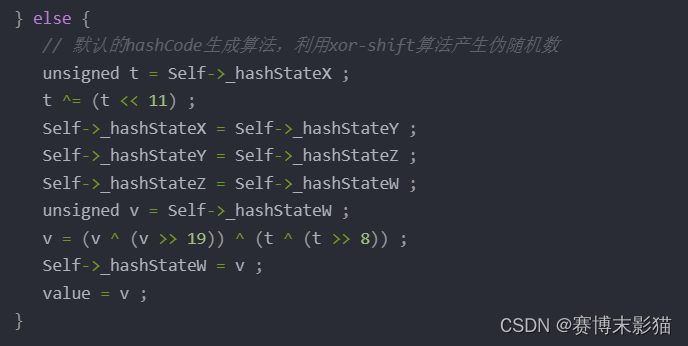
我们不需要看懂它在干什么,只需要知道一件事情:
它对相同的输入,一定是相同的输出;不同的输入,大概率是不同的输出
不知道为什么是大概率的读者可以自行搜索哈希算法,哈希碰撞,这里只做简单解释:
用有限的输出去映射无限的输入,只要输入的足够多,一定会发生哈希碰撞。
但是我们可以优化算法,尽量降低哈希碰撞在小数据量时候的发生的概率
讲了这么多,我们回归正题,hashCode也是一种判断是否相等的办法,而且非常高效,至少比equals快得多,但是hashCode方法不靠谱,有时候不相等也会认为是相等的
结论
关于重写equals方法,为什么一定要重写hashCode方法
hashCode计算虽然非常快,但是不靠谱,所以我们一般采用以下策略,去判断两个对象是否相等(这样效率很高):
- hashCode如果不相等,那么一定不是同一个对象,直接return false
- hashCode如果相等,再去调用equals方法,如果equals方法结果不相等,返回false
- 但是如果equals方法显示也相等,就说明出现了哈希碰撞,此时就需要在哈希表的数组对应位置生成链表;链表过长的时候还会转成红黑树,加快查询效率
所以这个方法重写的关联关系,本质上是因为人们约定俗成的一个规定:
equals方法相等,说明两个对象相等;两个对象相等,则hashCode一定相等;
hashCode不相等,则肯定不是相等的对象
equals方法是保底机制,但是比较慢
使用这种比较机制,可以大大加快哈希表数据结构key的地址的计算
最终的结论
- 如果只重写equals方法,不重写hashCode方法,就会出现“用户认为是相等的对象,hashCode值却不相等”
- hashMap和hashSet当中,计算key(hashSet的add方法其实就是hashMap的put方法)本质上是同一个方法,这个方法同时使用了hashCode和equals方法,以求能高效率的计算key,必须要保证这两个方法的比较逻辑一致,所以两个方法必须同时重写















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









