







1.使用TABLESAMPLE返回样本行;
使用TABLESAMPLE,我们可以从From子句的表中提取一些样本行。这个取样可以基于一定百分比的行。当应用程序只需要一些样本行而不是完整的结果集时,可以使用TABLESAMPLE来实现。
从某个数据源返回一定百分比的随机行:
use AdventureWorks
go
SELECT FirstName,LastName
FROM Person.Contact
TABLESAMPLE SYSTEM(2 PERCENT)
ORDER BY FirstName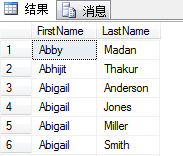
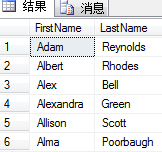
两次执行得到的结果不同
TABLESAMPLE用于从查询结果集中提取一些样本行。在这个示例中,我们从Person.Contact表取样2%的行。然而,这个百分比是表数据页的百分比。一旦选中了一个样奉页,那么页中的所有行都会返回。由于页的填充状态各不相同,所以返回行的数量也不一样。其实就算指定了行数,SQL Server也会把它转化为百分比,然后用同样的方法找出一定百分比的数据页。
2.使用PIVOT把值转化为列,并且使用聚合根据新的列来分组数据;
PIVO运算符能让我们创建交叉表的查询,它把值转化为多列,使用聚合来根据新列对数据进行分组.
下一个示例演示如何实现类似微软Excel旋转表特性的PIVOT和聚合数据功能t把~列中的值转到多列,在结果中显示聚合数据。
示例的第一部分显示旋转之前的数据。查询结果显示了雇员的轮换和他们所在的部门:
use AdventureWorks
go
SELECT s.Name ShiftName,
h.EmployeeID,
d.Name DepartmentName
FROM HumanResources.EmployeeDepartmentHistory h
INNER JOIN HumanResources.Department d ON
h.DepartmentID=d.DepartmentID
INNER JOIN HumanResources.Shift s ON
d.Name IN('Production','Enginering','MarKeting')
ORDER BY ShiftName 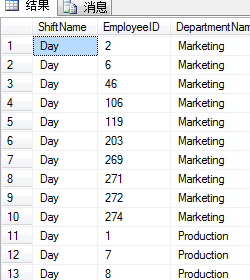
下面的查询把轮换的雇员数量和部门值旋转到列中:
use AdventureWorks
go
SELECT ShiftName,Production,Engineering,Marketing
FROM(
SELECT s.Name ShiftName,
h.EmployeeID,
d.Name DepartmentName
FROM HumanResources.EmployeeDepartmentHistory h
INNER JOIN HumanResources.Department d ON
h.DepartmentID=d.DepartmentID
INNER JOIN HumanResources.Shift s ON
d.Name IN('Production','Enginering','MarKeting')
) AS a
PIVOT
(
COUNT(EmployeeID)
FOR DepartmentName IN([Production],[Engineering],[Marketing])
)as b
ORDER BY ShiftName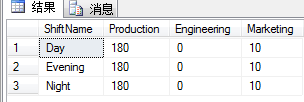
3.使用UNPIVOT来规范化重复的列分组:
UNPIVOT命令的功能几乎和PIVOT相反,它把列转成行。它和PIVOT有相同的语法,不同的是指定UNPIVOT.
这个示例演示如何使用UNPIVOT移除经常在非规范化表中看到的一组重复列。示例的第一部分创建了一个非规范化表,表中有几个生日复的、递增的电话号码列:
use AdventureWorks
go
CREATE TABLE dbo.Contact
(
EmployeeID INT NOT NULL,
PhoneNumber1 BIGINT,
PhoneNumber2 BIGINT,
PhoneNumber3 BIGINT
)
GO
INSERT dbo.Contact
(EmployeeID,PhoneNumber1,PhoneNumber2,PhoneNumber3)
VALUES (1,2718353881,3385531980,5244571342)
INSERT dbo.Contact
(EmployeeID,PhoneNumber1,PhoneNumber2,PhoneNumber3)
VALUES (2,12388971,1238931980,1237571342)
INSERT dbo.Contact
(EmployeeID,PhoneNumber1,PhoneNumber2,PhoneNumber3)
VALUES (4,45688971,4568931980,4567571342)
SELECT EmployeeID,PhoneType,PhoneValue
FROM(SELECT EmployeeID,PhoneNumber1,PhoneNumber2,PhoneNumber3
FROM dbo.Contact) c
UNPIVOT(PhoneValue FOR PhoneType
IN([PhoneNumber1],[PhoneNumber2],[PhoneNumber3])) AS p 使用UNPIVOT把重复的电话号码转化成更规范化的形式(重新利用一个PhoneValue字段来替代重复电话号码列多次);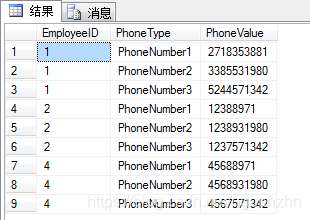
4.使用INTERSECT和EXCEPT操作数来返回仅在左查询中的不重复行(使用EXCEPT),或者左查询和右查询中都不重复的行(使用INTERSECT)。
INTERSECT和EXCEPT在数据集比较时很有用。例如,如果你需要比较测试表和正式表中的行,可以使用EXCEPT轻松找到和获取那些在一个表中存在而另外一个表中不存在的行。这些操作数在数据恢复的时候同样有用,因为你可以从过去的数据库中恢复丢失的数据,先和当前正式表中的数据进行比较,然后恢复相应的被删除的行。
USE AdventureWorks
go
--先创建两个基于Production.Product的表,用于演示EXCEPT和INTERSECT
--创建TABLEA
SELECT prod.ProductID,Prod.Name
INTO dbo.TableA
FROM (SELECT ProductID,Name,ROW_NUMBER() OVER (ORDER BY ProductID) RowNum
FROM Production.Product) prod
WHERE RowNum BETWEEN 1 AND 20
--创建TableB
SELECT Prod.ProductID,Name
INTO dbo.TableB
FROM(SELECT ProductID,Name,ROW_NUMBER() OVER (ORDER BY ProductID) RowNum
FROM Production.Product) prod
WHERE RowNum BETWEEN 10 AND 29 
现在使用EXCEPT运算符检测只在查询左表TableA中存在而不在TableBr+i存在的行:
SELECT ProductID,Name
FROM dbo.TableA
EXCEPT
SELECT ProductID,Name
FROM dbo.TableB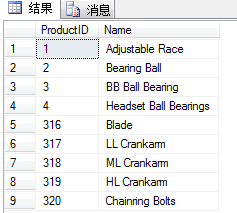
要显示在两个结果集中都能找到的不重复值,可以使J日INTERSECT运算符:
SELECT ProductID,Name
FROM dbo.TableA
INTERSECT
SELECT ProductID,Name
FROM dbo.TableB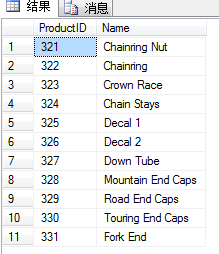
















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











