






目录
1.6.4 earliesCreditLine 借款人最早报告的信用额度开立的月份
0.前言
又是苦恼毕设的一天......好想出去玩啊/(ㄒoㄒ)/~~
因为这两天拿到了一个数据集,但一看有20来个特征,又完全没有清洗过,很脏很脏的数据,一时不知如何下手,又因为之前一直都在做NLP,机器学习的东西又忘得差不多了,现在回过头来看,特征处理,真的非常麻烦。
该博客出于记录拿到一个新的数据该如何着手去分析,分析之后又该如何处理成可以输入进模型的数据。
1.数据分析处理
默认拿到了一个数据集,已经划分好了训练集和测试集,这里以金融风控-贷款违约预测为例。该任务取自Datawhale与天池联合发起的金融风控赛事。
零基础入门金融风控-贷款违约预测_学习赛_天池大赛-阿里云天池的赛制 (aliyun.com)
下图所示是整个数据分析处理的框架。
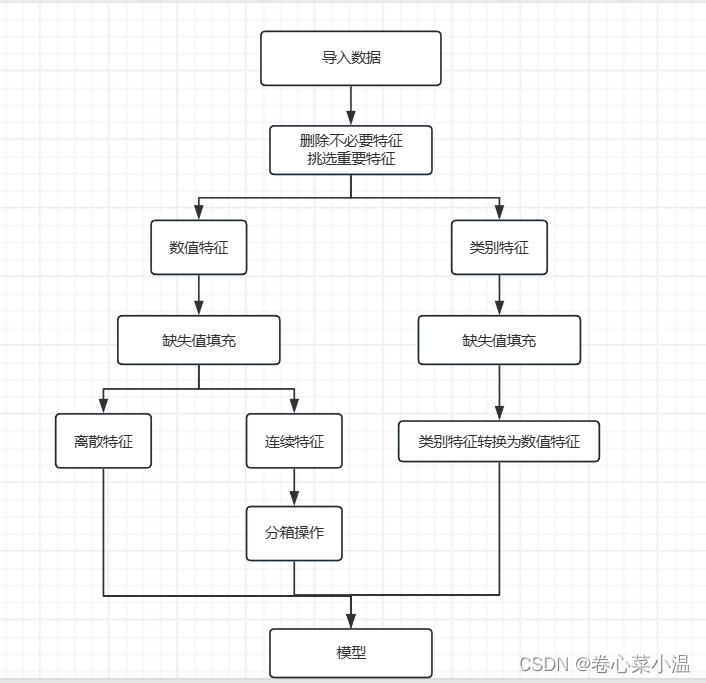
1.1 导入训练集和测试集
import pandas as pd
train_data = pd.read_csv("./data/train.csv") # 导入训练集
test_data = pd.read_csv("./data/test.csv") # 导入测试集
train_data.head() # 打印DataFrame的前5行
这里一般会打印前5行数据来看看,但对于这种有47列的数据,我觉得......我打印完,看了一下,还不如不看,没看出个啥。

这里其实建议打印所有的列名看看,其中“isDefault”为该数据集的目标值,然后再看看各列的数据是怎样的,有个大致的印象就可以了。这里以‘loanAmnt’为例,可以大概看看,这应该是一个连续数值的特征。
print(train_data.columns) # 打印数据的所有列名
train_data['loanAmnt'].head(10) # loanAmnt前10个数据
1.2 检查是否有可舍去的数据
1.对于序号、id这类特征,对最结果没有影响,可以删除。
2.缺失值存在过多的特征,可以删除。
【这里可以谨慎处理,因为缺失值也可以通过填充处理】
3.该特征只有一种值,对结果没有影响,可以删除。
# 查看训练集,测试集中特征属性只有一值的特征
one_value_fea = [col for col in train_data.columns if train_data[col].nunique() <= 1]
one_value_test_fea = [col for col in test_data.columns if test_data[col].nunique() <= 1]
有一个值的列
train_data.drop('id', axis=1, inplace = True) # id列对最终的结果并无影响,删除,但为了最终提交结果,保留test_data的id
train_data.drop('policyCode', axis=1, inplace = True) # 该列只有一个值,所以对结果并不能提供有用信息,删除
test_data.drop('policyCode', axis=1, inplace = True)
train_data.isnull().sum() # 查看缺失值情况1.3 利用IV值挑选特征
IV值:用来表示特征对目标预测的贡献程度,即特征的预测能力,一般来说,IV值越高,该特征的预测能力越强,信息贡献程度越高。
由于这次也是初次接触金融风控这块,特征挑选其实还有很多其他的算法,这里就留到后面慢慢探索吧~
import toad
toad.quality(train_data, target='isDefault', cpu_cores=0, iv_only=False)
# PS:若只想参考IV值,可以将iv_only=True,不然需要耗费很多时间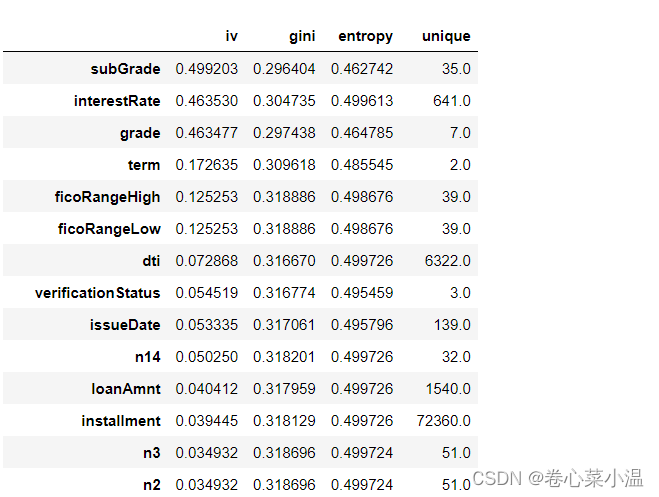
因为IV值 < 0.02 判定为该特征无预测能力,所以在这里就选择保存IV >= 0.02的特征。
# 删除无预测能力的特征
for data in [train_data, test_data]:
data.drop('n5', axis=1, inplace = True)
data.drop('n0', axis=1, inplace = True)
data.drop('regionCode', axis=1, inplace = True)
data.drop('n4', axis=1, inplace = True)
data.drop('n13', axis=1, inplace = True)
data.drop('n6', axis=1, inplace = True)
data.drop('pubRec', axis=1, inplace = True)
data.drop('n8', axis=1, inplace = True)
data.drop('revolBal', axis=1, inplace = True)
data.drop('openAcc', axis=1, inplace = True)
data.drop('postCode', axis=1, inplace = True)
data.drop('pubRecBankruptcies', axis=1, inplace = True)
data.drop('delinquency_2years', axis=1, inplace = True)
data.drop('totalAcc', axis=1, inplace = True)
data.drop('applicationType', axis=1, inplace = True)
data.drop('n12', axis=1, inplace = True)
data.drop('initialListStatus', axis=1, inplace = True)
data.drop('n11', axis=1, inplace = True)
data.drop('purpose', axis=1, inplace = True)
data.drop('n1', axis=1, inplace = True)
data.drop('employmentLength', axis=1, inplace = True)
data.drop('n7', axis=1, inplace = True)
data.drop('n10', axis=1, inplace = True)1.4 数值特征 & 类别特征
对于上一步处理好剩下的特征,我们将其分成数值特征和类别特征。由于数值特征中包含了“isDefault”,这是目标值,不做任何的特征处理,所以去除。(注:这里只是在numerical_fea这个列表中去除了,表示后续不对这个特征进行处理,而不是在数据集中去除了它)
numerical_fea = list(train_data.select_dtypes(exclude=['object']).columns) # 数值特征
category_fea = list(filter(lambda x: x not in numerical_fea, list(train_data.columns))) # 类别特征
# 将 label 去除
label = 'isDefault'
numerical_fea.remove(label)1.5 缺失值填充
数值特征:中位数填充。
类别特征:众数填充。
# 按照中位数,填充数值型特征
train_data[numerical_fea] = train_data[numerical_fea].fillna(train_data[numerical_fea].median())
test_data[numerical_fea] = test_data[numerical_fea].fillna(test_data[numerical_fea].median())
# 按照众数,填充类别型特征
for cate_fea in category_fea:
train_data[cate_fea] = train_data[cate_fea].fillna(train_data[cate_fea].mode().values[0])
test_data[cate_fea] = test_data[cate_fea].fillna(test_data[cate_fea].mode().values[0])当然,除了上述两种填充方法还有很多其他处理缺失值的方法,比如,对于数据集中缺失值较少的情况,可以直接删除缺失值所在的行;对于数值特征,也可以使用平均值、近似值来填充;还有更复杂的填充方法,先训练一个模型来预测这个缺失值。
1.6 类别特征处理
该数据集的类别特征有:
grade、subGrade、issueDate、earliesCreditLine
1.6.1 grade 贷款等级
首先,我们先统计一下该样本,整体来看看:
train_data['grade'].value_counts()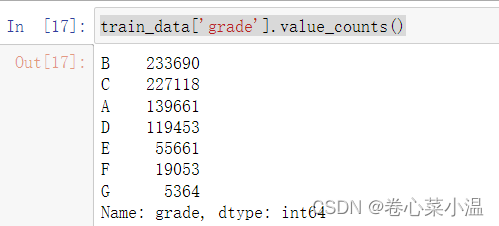
对于等级这种类别特征,是有优先级的,可以采用自映射编码。
# 1.grade
for data in [train_data, test_data]:
data['grade'] = data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7})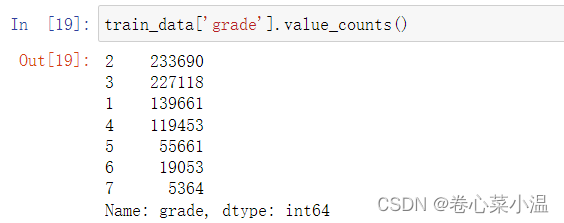
1.6.2 subGrade 贷款等级之子级
''等级之子级''和''等级''的处理方式一样。
# 该函数用于将 subGrade 转换为数值等级
def get_sub_grade(grade, sub):
return grade*10+int(sub[1])
# 2.subGrade
for data in [train_data, test_data]:
data['subGrade'] = data.apply(lambda row: get_sub_grade(row['grade'],row['subGrade']), axis=1)1.6.3 issueDate 贷款发放日期
这里将贷款发放日期转变成时间差,变成一个连续数值。
# 3.issueDate
import datetime
for data in [train_data, test_data]:
data['issueDate'] = pd.to_datetime(data['issueDate'],format='%Y-%m-%d') # 将原始数据转换为 Pandas 的日期时间格式
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d') # '2007-06-01'设定为开始日期
# 每个样本相对于 2007-06-01 的天数
data['issueDateDT'] = data['issueDate'].apply(lambda x: x-startdate).dt.days # dt.days 将 Timedelta 对象转换为天数1.6.4 earliesCreditLine 借款人最早报告的信用额度开立的月份
我们先打印几个特征的样本来看看:
train_data['earliesCreditLine'].sample(5)
这里处理的比较粗暴,就只保留年份。
# 4.earliesCreditLine
for data in [train_data, test_data]:
data['earliesCreditLine'] = data['earliesCreditLine'].apply(lambda s: int(s[-4:])) # 只保留年份好的!!!!!!做到这里,恭喜你!!!!!!!成功使类别特征(string、time啊......这些)转换为了数值特征。
1.7 数值特征处理
我们首先划分数值型变量中的:连续变量和离散型变量。通过统计该特征不同种类的数值个数来判断,若该特征的数值种类 <= 10,则认为其是离散型变量。
# 划分数值型变量中的:连续变量和离散型变量
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = [] # 连续变量
numerical_noserial_fea = [] # 离散变量
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
else:
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(train_data,numerical_fea)
1.7.1 离散型变量
对于离散型变量,我们不做任何处理,这里我觉得它是跟类别变量替换为数值之后是相同类型的。
1.7.2 连续型变量
对于连续型变量,我这里只做了分箱处理,分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度,从而使模型更加稳定。
具体做法就是,比如将age在0-5的分入一个箱子中,age在6-10的又分入另外一个箱子中。
另外,这十几个连续数值特征也不是每一个都进行了分箱操作,(我参照了大佬的选择需要分箱的数据,但具体是什么原因选择这些数据进行分箱,我也不太懂......)通常来说,取决于:
特征的分布情况: 对于近似正态分布或者接近线性关系的特征,不一定需要进行分箱操作。但对于偏态分布或者存在非线性关系的特征,分箱操作可能会有所帮助。
特征的重要性: 在特征选择过程中,通常会评估每个特征对目标变量的重要性。如果某个连续型数值特征对目标变量的影响较大,那么对其进行分箱操作可能会提高模型性能。
# 分箱操作
for data in [train_data, test_data]:
data['loanAmnt'] = pd.qcut(data['loanAmnt'], 10, labels=False)
data['interestRate'] = pd.qcut(data['interestRate'].rank(method='first'), 100, labels=False)
data['installment'] = pd.qcut(data['installment'], 100, labels=False)
data['annualIncome'] = pd.qcut(data['annualIncome'], 10, labels=False)
data['dti'] = pd.qcut(data['dti'], 100, labels=False)
data['revolUtil'] = pd.qcut(data['revolUtil'], 100, labels=False)2.总结
至此,该任务的数据分析处理就到此结束了,建模与评估请移步至:
【机器学习】金融风控贷款违约预测--建模与评估-CSDN博客
在本篇中,其实也有很多不足之处,比如,没有做特征交互,对于类别特征可以做更高维的映射,对于一些比较重要的特征其实并没有取出来好好分析,然后更好地做特征处理,因为在机器学习中,特征工程真的非常重要,在业界有一个很流行地说法:数据和特征工程决定了模型的上限,改进算法只不过是逼近这个上限而已。但本文也是我的初步探索金融风控,至少搞明白了拿到一份数据,分析处理的步骤是怎样的,后面再慢慢进步吧!

















 4220
4220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









