









文章目录
一.前言
1.1 Lucene
ES是基于Lucene的,Lucene是全文检索工具. 重点内容和原理包括信息检索,分词原理,词项,倒排索引,排序算法等; 对每个字段都建立了索引,即一切皆索引.
分词原理由很多分词算法,可以深入研究.常见的分词器有IKAnalyzer分词器,Mmseg4j分词器等.我们遇到的最大问题是中文分词问题.
词项Term是索引的最小单位,是经过语言学处理之后的词条.词条化是将字符序列拆分为子序列的过程.每一个子序列即词条.
倒排索引是相对于正序排列的概念;例如文档内容是字符序列,字符序列词条化,按照文档查找词项是正排索引,则按照词项查询文档就是倒排索引.Lucene和ES实际应用中更多的是倒排索引.
1.2 ElasticSearch Concepts
| ElasticSearch官方中文文档 | ElasticSearch官方英文文档 |
|---|---|
| https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html | https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html |
1.2.1 ElasticSearch 专业术语概念
ElasticSearch6.x 基本概念解读:
https://blog.csdn.net/chengyuqiang/article/details/85272238
(1)Near Realtime
Elasticsearch is a near-realtime search platform.
Elasticsearch 是一个分布式、可扩展、近实时的搜索与数据分析引擎.是准实时刷新检索引擎.
基于Lucene,Lucene是支持实时查询的, 原理是每次索引之后都做一次刷新.
ES不是实时的, 在插入或更新索引之后是查不到新的数据的.
这样做肯定会影响到索引效率, ElasticSearch 引入了刷新策略, 不是即时的而是延时毫秒级或者秒级单位来处理,做到的是理论上查询结果是接近实时的查询结果,即准实时的概念.
常用刷新策略:
IMMEDIATE更新策略立即更新,所有分片默认1s更新
Java代码调用实例:
IndexResponse response = client
.prepareIndex(index,type,productId)
.setSource(data)
.setRefreshPolicy(RefreshPolicy.IMMEDIATE)
.get();
(2) Node
节点,一个ElasticSearch Server可以作为一个节点来看待.而集群是多个节点组成的一个水平扩展来大大提升性能的设计.
(3) Cluster
集群由多个节点组成,一般包含一个主节点master node.主节点挂了,集群存在其他节点也能保证服务仍然可用,而不是整个系统直接挂掉了.
1.2.2 ElasticSearch与传统数据库
数据存储格式为JSON
(1) Index
一个索引是文档的集合.对应关系型数据库中的概念就是数据库.
(2) Document
文档是信息检索的对象,是检索信息的基本单元.对应数据库中的一行记录.
{
"name" : "Jay",
"desc" : "Is Jay",
"gender" : "male",
"birth" : "2000-10-10"
}
(3) Field
字段, 域的概念,对应数据库中的字段; 比如上面的name, desc
(4) Type
类型, 6.X版本一个索引允许包含一个type,7.X版本将type弃用了.
一种类型, 用来区分索引的逻辑类别,分区.Lucene没有这个概念.
(5) Shards & Replicasedit
分片,简单理解为分表.将一个大表拆分为多个表来处理数据量非常大的场景.这是为了方便理解,并不等价于分表的概念.
分片的原理是在物理上实现拆分, 不同的分片支持放在不同的服务器; 解决了单台服务器性能限制的问题. 而ES面对的场景就是存储数据量级较大的情况, 所以支持在创建索引时自定义分片数.
副本,就是对分片的备份,主分片损坏或者异常丢失时,副本可顶上来代替主分
片,保证功能可用.
(6)Template
模板设置包括settings和mappings,定义了Index的基本设置和field映射关系等信息,支持配置文档的字段数据类型分词器等详细属性.多个索引可通过模式匹配的方式重用一个模板.例如模logs.template适用于以log开头的所有索引.
二.安装运行
2.1 ElasticSearch安装
要求JDK,这里安装JDK1.8; JDK安装这里就不介绍了.
Linux 服务器安装ElasticSearch 命令, 当然使用wget命令下载或者rz命令上传也可以.
安装
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
解压
tar -zxvf elasticsearch-6.5.4.tar.gz
进入安装路径下的config,修改elasticsearch.yml配置文件,修改host为当前服务器IP,修改post为指定端口,默认端口为9200-9300
在ElasticSearch安装路径下运行bin/elasticsearch即可.访问localhost:9200可以看到ElasticSearch运行成功的基本信息.localhost修改为服务器IP亦可.
2.2 ElasticSearch运行
运行命令,进入安装目录,执行bin/elasticsearch或者进入bin执行./elasticsearch命令.
安装目录下执行:
bin/elasticsearch
安装目录的bin目录下:
./elasticsearch
后台运行服务命令:
nohup ./elasticsearch >/dev/null
运行成功信息如下:
此时访问ip:host 即可看到ES 运行成功了,可查看集群与节点信息; 在Dos 窗口命令行执行查询命令:
查看集群状态信息
C:\Users\Lenovo>curl -X GET "192.168.15.135:9200/_cat/health?v"
查看节点信息
C:\Users\Lenovo>curl -X GET "192.168.15.135:9200/_cat/nodes?v"

三.配置优化
3.1elasticsearch.yml
编辑安装路径/config/elasticsearch.yml配置文件
# ---------------------------------- Cluster ----------------------------------#
# Use a descriptive name for your cluster:
# 集群名称自定义, 集群内多个节点的集群名称唯一
cluster.name: log_elk
# ------------------------------------ Node ---------------------------------#
# Use a descriptive name for the node:
# 节点名称自定义,集群内多个节点名称不重复
node.master: false
node.name: node-135
# ----------------------------------- Paths ----------------------------------
# Path to directory where to store the data (separate multiple locations by comma):
path.data: /opt/elkf/esData/data
path.logs: /opt/elkf/esData/logs
# ----------------------------------- Memory --------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# ---------------------------------- Network ---------------------------------
network.host: 192.168.15.135
http.port: 9200
# 配置集群自动发现节点
discovery.zen.ping.unicast.hosts:["192.168.15.135", "192.168.15.134"]
# 配置最大master节点数目
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
# 解决bootstrap启动问题
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
ES 启动时可能会出现bootstrap启动问题, 这个问题主要原因是服务器本身系统配置默认参数大小设置偏低, 适当调大即可; 百度一下修改指定系统文件即可.
3.2 jvm.options
编辑/安装路径/config/ jvm. options配置文件, 根据服务器本身配置去合理修改堆内存分配.默认分配4g, 服务器配置低的话, 就调小2或1; 配置高就适当调大多次测试ES的吞吐量找到最优配置参数.
## You should always set the min and max JVM heap
## size to the same value. For example, to set
## the heap to 4 GB
-Xms4g
-Xmx4g
四.索引下的增删改查
4.1 Curl 命令
4.1.1 安装
Curl是支持命令行模拟URL请求的工具; Windows默认支持此命令, 下载路径:
http://www.paehl.com/open_source/?CURL_7.49.1
其中GUI for CURL 0.1 为对应curl版本的可视化工具; 在DOS窗口执行命令Curl --help查看帮助
4.1.2 常用的指令
- -X 指定http的请求方法 有HEAD GET POST PUT DELETE
- -d 指定要传输的数据
- -H 指定http请求头信息
- -L 指定跳转地址
eg: curl -L www.sina.com ch
4.2 ES命令支持场景
4.2.1 DOS窗口命令行
这里以Windows 系统命令行窗口下使用curl 为例演示,

浏览器GET请求

kibana DEV Tool工具
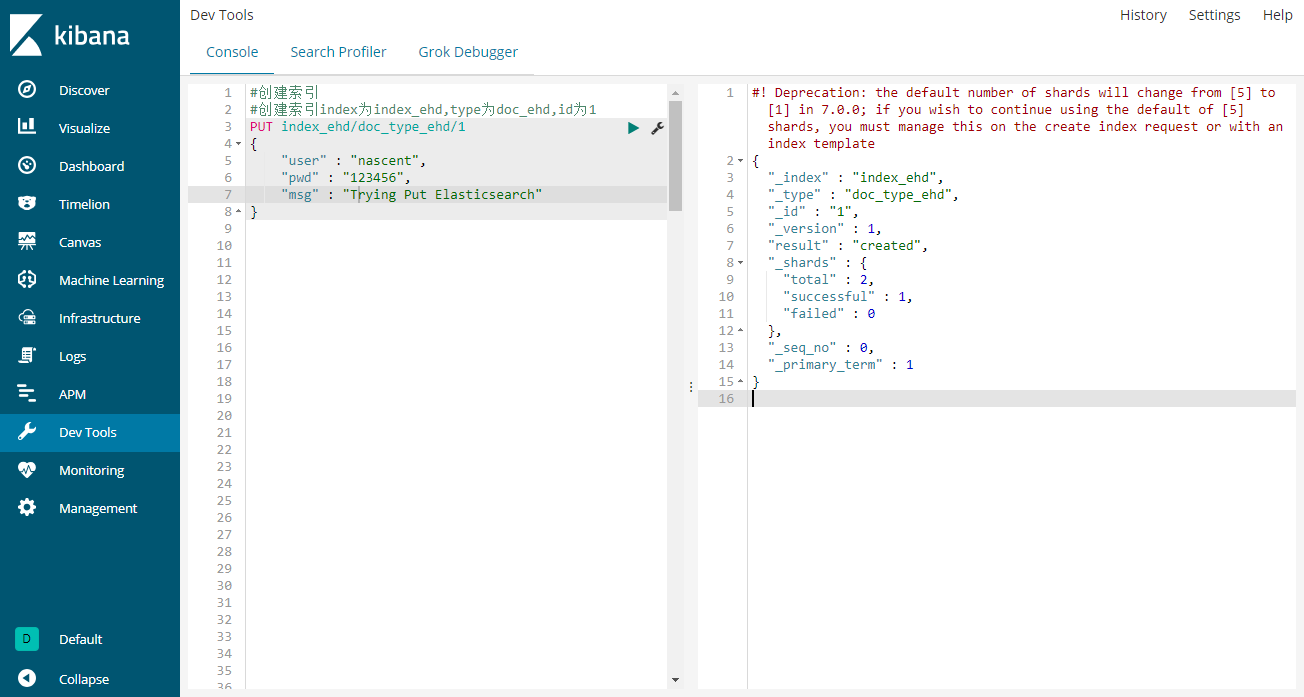
也支持使用Postman工具模拟请求, CURL可视化工具,Kibana的管理工具,ES监控工具等直接执行或间接模拟以下命令来交互ES.
4.3 Index CRUD
(1)查看全部索引
curl -X GET "192.168.15.135:9200/_cat/indices?v"
(2)删除索引
curl -X DELETE "192.168.15.135:9200/my_index?pretty"
响应
{
"acknowledged" : true
}
(3)创建新索引
curl -X PUT "192.168.15.135:9200/index_zyn_test?pretty"
响应
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "index_zyn_test"
}
4.4 Document CURD
词项查询,模糊查询,复合查询等是重点关注对象; 此处没有整理这类查询, 只演示基本的操作.
在Windows 命令行要注意双引号的使用,比较特殊.

(1)新增document文档并创建type类型, 插入与更新命令
C:\Users\Lenovo>curl -H "Content-Type: application/json" -XPOST 192.168.15.135:9200/index_zyn_test/test_type/1 -d "{"""user_name""":"""xiaoming"""}"
响应
{"_index":"index_zyn_test","_type":"test_type","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
C:\Users\Lenovo>curl -H "Content-Type: application/json" -XPOST 192.168.15.135:9200/index_zyn_test/test_type/1?pretty -d "{"""name""":"""xiaoxiao""","""gender""":"""male"""}"

(2)查看文档及映射
- _id文档的 ID 字符串
- _type文档的类型名
- _index文档所在的索引
_index + _type + _id 唯一确定一个文档.
curl -H "Content-Type: application/json" -XGET 192.168.15.135:9200/index_zyn_test/test_type/_search
curl -H "Content-Type: application/json" -XGET 192.168.15.135:9200/index_zyn_test/test_type/1?pretty
4.5 Template CURD
模板设置包括settings和mappings,定义了Index的基本设置和field映射关系等信息.多个索引可通过模式匹配的方式重用一个模板.例如模板logs.template适用于以log开头的所有索引.
存在多个索引模板,某个索引匹配支持多个模板时,模板的settings和mappings按照order属性自动整合为新模板来支持该索引.
模板支持在ElasticSearch安装路径下的配置; 配置文件为JSON文件.
(1)新增模板, 模板名称自定义, 以logs.template为例
curl -XPUT localhost:9200/_template/logs.template -d '
{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"doc" : {
"_source" : {"enabled" : false }
}
}
}'
(2)更新模板, 主要修改mappings和settings; 支持更新原配置, 扩展过滤器, 分词方式等.
curl -XPOST localhost:9200/_template/logs.template -d '
{
"settings" : {
"number_of_shards" : 5
},
"mappings" : {
"doc" : {
"_source" : {"enabled" : true}
}
}
}
(3)删除模板,可以指定模板名称,也可以使用通配符
curl -XDELETE localhost:9200/_template/logs.template
(4)查看模板,不指定具体名称则返回全部的模板.
curl -XGET localhost:9200/_template/logs.template
curl -XGET localhost:9200/_template
可直接指定类型, 设计文档, 字段设计及数据类型
五.补充说明
5.1 PUT 和POST的区别
两种请求本身是都支持新增和更新的.
主要区别是PUT的方法是幂等的, 多次操作的结果是一样的, 用于更新.POST不是幂等方法, 会出现资源重复加载问题, 用于新增.
POST作用于资源集合, PUT作用于具体的资源之上.
5.2 非查询字段不建立索引
ES全文检索嘛,默认对所有的field字段建立索引,如果存在field确实不需要作为索引字段,可以通过分析器设置field 的index: no来不为其创建索引.
- no: 不把此字段添加到索引中,也就是不建索引,此字段不可查询
- not_analyzed:将字段的原始值放入索引中,作为一个独立的term,它是除string字段以外的所有字段的默认值。
- analyzed:string字段的默认值,会先进行分析后,再把分析的term结果存入索引中。
eg:
{
"settings":{
},
"mappings":{
"doc_type":{
"properties":{
"name":{
"type":"keyword",
"index":"no"
}
}
}
}
}
5.3 数据类型对照关系
| Json数据格式 | ES存储数据类型 |
|---|---|
| 布尔型true/false | boolean |
| 整数123 | long |
| 浮点数123.45 | double |
| 有效的日期格式2019-01-07 | date |
| 字符串hello | text / keyword |
类型keyword 和text 的区别是, keyword 类型的数据存储在ES 中, 不进行分析, 将整个字符串作为一个词项, Text 类型的数据存储后会进行词项分析.
5.4 数据对照关系
| ElasticSearch | 传统数据库 |
|---|---|
| Index 索引 | Database 数据库 |
| Type 类型 | Table 表 |
| Field 字段/域 | Column 列/字段 |
| Document 文档 | Row 行/记录 |
| Mappings 映射 | Schema 数据库对象集合 |
| Settings 设置 | |
| 一切皆索引 | 指定字段创建索引 |
| Query DSL | SQL 数据库语句 |
| GET http:// GET请求 | Select 查询 |
| POST http:// POST请求 | Add 新增 |
| PUT http:// PUT请求 | Update 更新 |
| DELETE http:// DELETE请求 | Delete 删除 |
注意:
- 所有比照都是为了便于理解的,不存在对等关系
- ES聚合查询性能本身缺陷
- ES推荐使用英文小写,大写有各种坑…















 6935
6935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











