






 本文深入探讨Mysql慢查询的定义与作用,详细介绍慢查询日志的配置与分析,包括启动、配置参数、记录规则及分析工具mysqldumpslow的使用。同时,文章覆盖了数据库设计的三大范式及其在减少冗余中的应用,并提供了多种慢查询优化策略,如服务器硬件升级、Mysql服务器优化、SQL语句优化、反范式设计和索引优化等。
本文深入探讨Mysql慢查询的定义与作用,详细介绍慢查询日志的配置与分析,包括启动、配置参数、记录规则及分析工具mysqldumpslow的使用。同时,文章覆盖了数据库设计的三大范式及其在减少冗余中的应用,并提供了多种慢查询优化策略,如服务器硬件升级、Mysql服务器优化、SQL语句优化、反范式设计和索引优化等。
Mysql 优化从基础到落地 一 节
● 慢查询, 找到值得优化的 SQL
慢查询的定义以及作用:
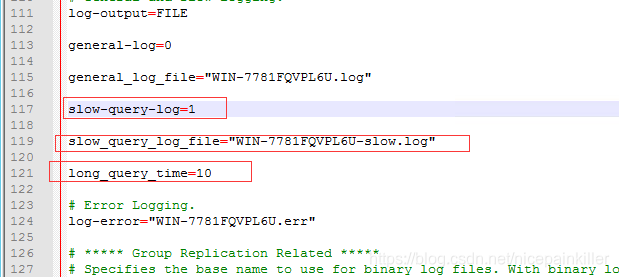
慢查询日志, 顾名思义 就是查询慢的日志, 是指 Mysql 记录所有执行 超过 long_query_time 参数设定的时间的 阀值 的 SQL 语句的 日志。 该日志能为 SQL 语句的优化 带来 很好的帮助。 默认情况下 慢查询日志是关闭的, 要使用慢查询日志功能 首先要开启慢 查询的日志功能
启动慢查询:
● 常用配置
- show_query_log 启动 停止慢查询
- show_query_log_file 指定慢查询日志的 存储路径及 文件(默认和数据文件放在一起)
- long_query_time 指定记录慢查询日志 SQL 执行 时间的 阀值 (单位 秒, 默认 10秒)
- log_queries_not_using_indexes 是否记录未使用的 索引的 SQL
- log_output 日志存放的地方 [table] [file] [file, table]
● 记录符合条件的 SQL
- 查询语句
- 数据修改语句
- 已经回滚的 SQL
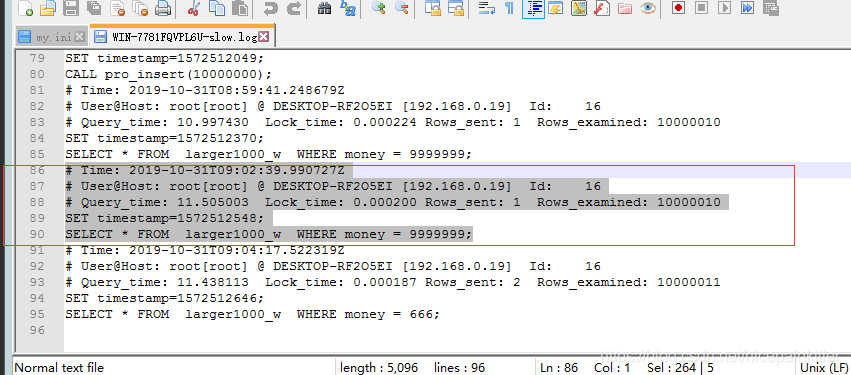
下面是 其中的几条慢查询日志
(单位毫秒)
- query_time :查询时间
- lock_time :执行获取 锁 的时间
- row_sent :获得结果时间
- row_examined :扫描的行数
- set_ timestamp :sql 执行的具体时间
慢查询 分析工具 mysqldumpslow
● 常用的 慢查询 日志分析工具 mysqldumpslow
汇总除查询 条件以外 完全相同的 SQL, 并将 分析结果 按照参数中指定的顺序输出
● 语法
mysqldumpslow -s r -t 10 slow-mysql.log
● -s 排序参数 : c,t,l,r,at,ai,ar
c :总次数
t :总时间
l :总次数
r :总数行数
at, al, ar / t,l,r :平均数 at = 总时间 / 总次数
● -t 指定取前面几天 作为结果输入:
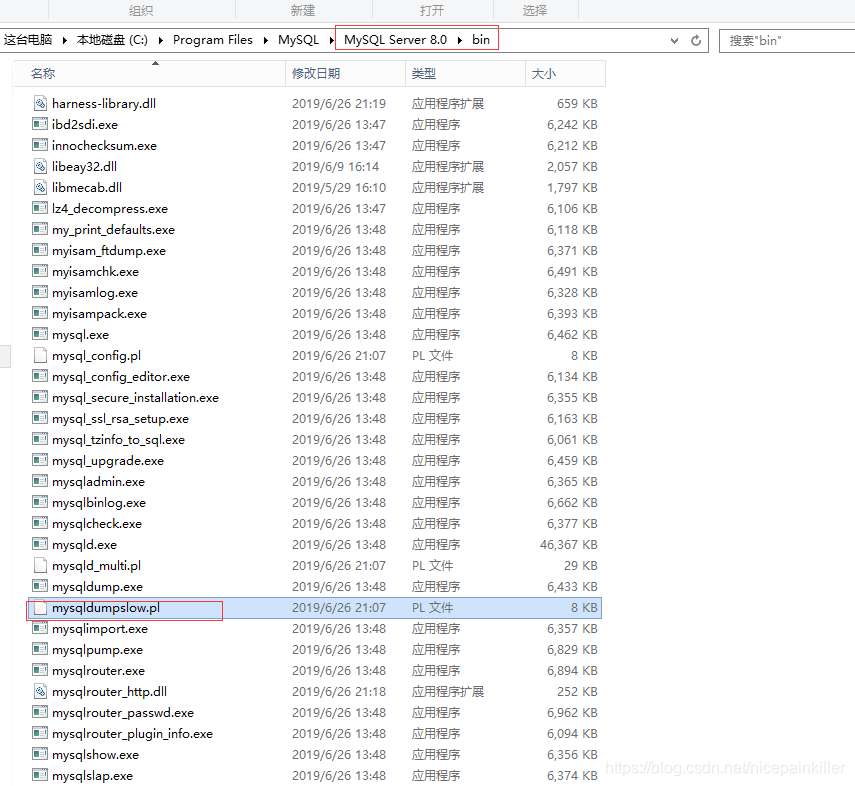
这个需要 安装 perl 来运行 mysqldumpslow.pl
#以总时间排序,取出前5条
C:\Program Files\MySQL\MySQL Server 8.0\bin>perl mysqldumpslow.pl -s t -t 5 C:\WIN-7781FQVPL6U-slow.log
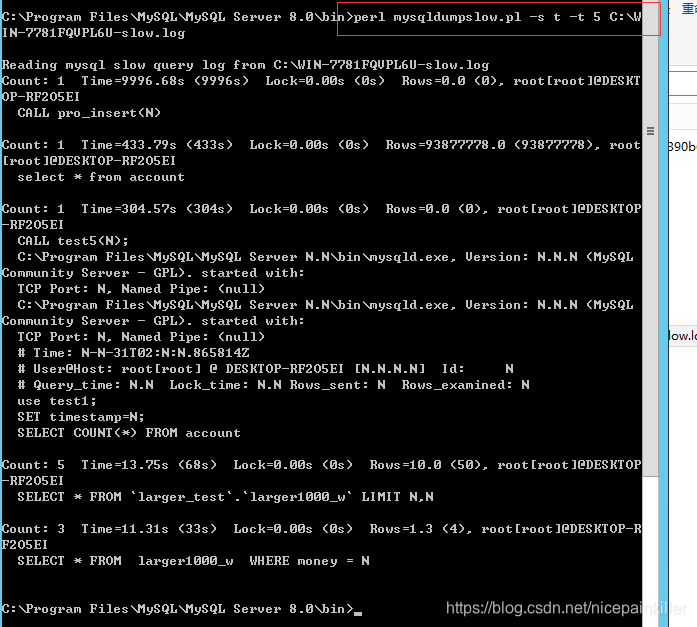
慢的 SQL 语句 已经找到出来了,接下来我们来优化慢的 SQL
数据库设计的三大范式
三大范式的主要作用: 减少冗余
● 第一大范式
数据库表中的 所有字段 都 只具有 单一属性
单一属性 的列是由 基本数据类型 所构成的
设计出来的表 都是简单的 二维表
● 第二大范式
要求表中只有一个业务主键, 也就是说符合第二范式的表 不能存在 非主键 列 只对部分主键的 依赖关系; (每一行数据 需要有一个 主键 来区分)
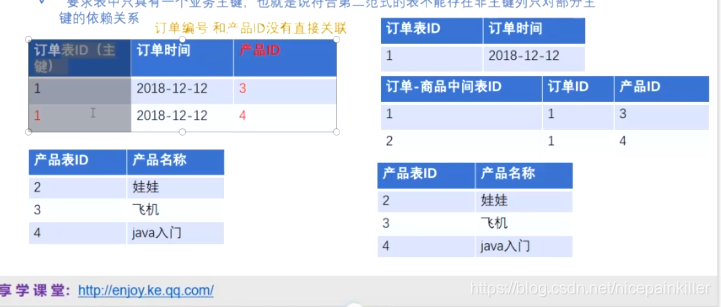
● 第三大范式
指 每一个 非 主键属性 即不能 部分依赖 也不传递依赖 与 主键。(属性之间不要有关联)
常用的慢查询 优化方式:
● 服务器硬件
SSD 比 HDD 高 10倍 左右
● Mysql 服务器优化
linux 随着时间推移 会比 window 稳定 而且系统效能 更高
● SQL 本身优化
子查询 优化为 关联查询
● 反范式设计优化
反范式 是针对 范式而言的
所谓的 反范式 优化 就是 为了 性能和 读取效率 考量 而 违反 数据库设计范式 进行的优化
允许存在 少量的 冗余 来换取 缩短查询时间。 换句话说 使用空间来换取时间
● 索引优化
索引的定义:
索引(index)是帮助 Mysql 高效获取数据的 数据结构。可以得到 索引的本质: 索引是数据结构
索引的分类:
- 普通索引: 一个索引只包含单个列, 一个表 可以包含多个单列索引 idnex
- 唯一索引: 索引列的值 必须唯一, 但是 允许为 null unique
- 主键索引: 主键索引 是在创建 主键的时候, 自动添加的 索引唯一 且不能为 null pramery key
- 复合索引: 一个索引包含多个列
执行计划:
执行计划是什么:
使用 EXPLAIN 关键字 可以 模拟 优化器 执行 SQL 查询语句; 从而知道 是如何 处理你的 MYSQL 语句的。 分析你的查询语句 或者 表的结构性 瓶颈
语法:
Explain + SQL语句
● Explain 看是否 用到了 索引; key 为 Null 则没有使用 到索引, ley_len 索引 算法
key_len 算法 类型 varchar char 字符编码 utf8 3 字符本身长度● 索引是否 充分使用, ley_len 的大小,数值越大 说明 索引利用的月充分
● Type 字段: type system > const > eq_ref > ref > range > index > ALL
● ALL 全表扫描 性能最低 ● Index 全表扫描(索引表)



















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











