






长话短说,有个需求:已知很多企业名称,存放在excel表格中,想要查询这些企业的地址;
一开始想使用爱企查/高德地图,爱企查不允许使用开发者模式,高德地图搞不太懂,后来找到了一位大哥的代码,就使用AI在大哥代码上进行修改,最终打包成了一个exe文件。
大哥网址我也贴一下:利用selenium批量获取百度地图的地址搜索结果_地图上批量搜索地址-CSDN博客
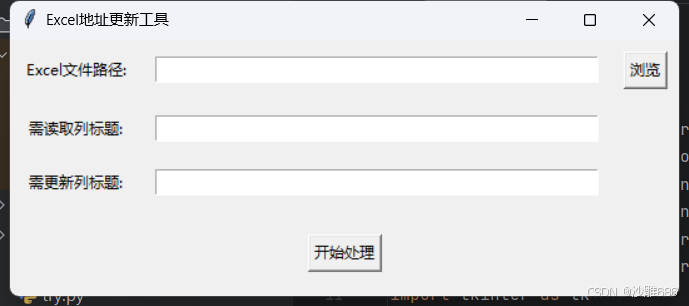
功能:如上,选择excel文件路径,找到企业名称所在的列标题名(需读取列标题),然后输入需更新列标题,也就是想要把地址存放在哪个列标题下面,或者输入一个不存在的列标题名,他会创建一个新的列,将地址保存进去。
存在的问题:不知道为啥有些地址明明能查到,但是程序运行结果有些企业的地址是空白的,但是对于大批量的查询来说还是能够缩短一些人力。(我自己的垃圾电脑,500条数据处理了50min,不知道其他的咋样,仅供参考)
代码如下:
import pandas as pd
import time
import logging
import concurrent.futures
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tkinter as tk
from tkinter import filedialog, messagebox
# 创建一个logger对象
logger = logging.getLogger('my_logger')
logger.setLevel(logging.DEBUG)
# 创建一个控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 创建一个文件处理器,将日志输出到文件
file_handler = logging.FileHandler('app.log')
file_handler.setLevel(logging.DEBUG)
# 创建一个格式化器,设置日志输出格式
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# 将格式化器添加到控制台处理器和文件处理器
console_handler.setFormatter(formatter)
file_handler.setFormatter(formatter)
# 将控制台处理器和文件处理器添加到logger对象
logger.addHandler(console_handler)
logger.addHandler(file_handler)
def setup_driver():
"""
创建并配置Chrome浏览器驱动实例,设置为无头模式并返回
:return: 配置好的Chrome浏览器驱动实例
"""
options = webdriver.ChromeOptions()
options.page_load_strategy = 'eager'
options.add_argument("-headless")
driver = webdriver.Chrome(options=options)
# 设置全局隐式等待时间5s
driver.implicitly_wait(5)
return driver
def search_address(driver, location, refresh_count=0, max_refresh=3):
"""
在百度地图页面上搜索单个地址,并返回查询到的第一个地址结果,如果未找到则返回原地址
:param driver: Chrome浏览器驱动实例
:param location: 要搜索的地址
:param refresh_count: 刷新次数
:param max_refresh: 最大刷新次数
:return: 查询到的第一个地址结果或者原地址
"""
driver.get("https://map.baidu.com/@12713770.095,3547943.7200000007,19z")
logger.debug(f"已打开百度地图页面,准备输入地址: {location}")
input_box = wait_for_element_to_be_clickable(driver, By.ID, "sole-input")
input_box.send_keys(Keys.CONTROL, "a")
input_box.send_keys(Keys.BACKSPACE)
input_box.send_keys(location)
logger.debug(f"已在输入框中输入地址: {location}")
search_button = wait_for_element_to_be_clickable(driver, By.XPATH, '//*[@id="search-button"]')
search_button.click()
logger.debug(f"已点击搜索按钮,开始等待搜索结果,搜索地址为: {location}")
# 智能等待策略:等待页面加载完成
wait_for_page_load(driver)
POILIST_CLASS_NAME = 'poilist'
ADDRESS_XPATH = '//*[@id="card-1"]/div/div[1]/ul/li[1]/div[1]/div[3]/div[2]/span'
try:
poilist_element = wait_for_element_to_be_present_and_visible(driver, None, By.CLASS_NAME, POILIST_CLASS_NAME)
address_element = wait_for_element_to_be_present_and_visible(driver, poilist_element, By.XPATH, ADDRESS_XPATH)
result = address_element.text
logger.info(f"获取到地址信息: {result},对应搜索地址: {location}")
return result
except NoSuchElementException as e:
logger.error(f"元素定位失败,异常信息: {str(e)},搜索地址: {location},将返回原地址")
if refresh_count < max_refresh:
logger.info(f"正在进行第 {refresh_count + 1} 次刷新,尝试重新搜索")
driver.refresh()
# 递归调用自身,增加刷新次数
return search_address(driver, location, refresh_count + 1, max_refresh)
else:
logger.warning(f"达到最大刷新次数 {max_refresh},将返回原地址")
return location
def wait_for_element_to_be_clickable(driver, by, value):
"""
等待页面元素变为可点击状态,最长等待时间为15秒,如果超时则抛出异常
:param driver: Chrome浏览器驱动实例
:param by: 元素定位方式(如By.ID、By.XPATH等)
:param value: 对应定位方式的具体值
:return: 可点击的页面元素
"""
return WebDriverWait(driver, 15).until(
EC.element_to_be_clickable((by, value))
)
def wait_for_element_to_be_present_and_visible(driver, parent_element, by, value):
"""
等待元素在其父元素下呈现且可见,最长等待时间为30秒,如果超时则抛出异常
:param driver: Chrome浏览器驱动实例
:param parent_element: 父元素
:param by: 元素定位方式(如By.ID、By.XPATH等)
:param value: 对应定位方式的具体值
:return: 呈现且可见的页面元素
"""
if parent_element:
return WebDriverWait(parent_element, 30).until(
EC.visibility_of_element_located((by, value))
)
else:
return WebDriverWait(driver, 30).until(
EC.visibility_of_element_located((by, value)))
def wait_for_page_load(driver):
"""
等待页面加载完成,使用JavaScript检查document.readyState是否为'complete'
:param driver: Chrome浏览器驱动实例
:return: 无
"""
WebDriverWait(driver, 40).until(
lambda driver: driver.execute_script("return document.readyState") == "complete"
)
def getColumnData(file_path, column_name):
"""
从Excel文件中读取指定列的数据,并以列表形式返回
:param file_path: Excel文件路径
:param column_name: 列标题
:return: 指定列的数据列表
"""
try:
data = pd.read_excel(file_path, engine='openpyxl', usecols=[column_name])
logger.debug(f"成功从Excel文件 {file_path} 中读取列 {column_name} 的数据")
return data[column_name].tolist()
except Exception as e:
logger.error(f"读取Excel文件 {file_path} 中列 {column_name} 的数据出现错误,异常信息: {str(e)}")
raise e
def updateExcelColumn(file_path, column_name, new_data):
"""
将新数据更新到Excel文件的指定列中
:param file_path: Excel文件路径
:param column_name: 列标题
:param new_data: 要更新的数据列表
:return: 无
"""
try:
data = pd.read_excel(file_path, engine='openpyxl')
data[column_name] = new_data
data.to_excel(file_path, engine='openpyxl', index=False)
logger.info(f"已成功将新数据更新到Excel文件 {file_path} 的 {column_name} 列中")
except Exception as e:
logger.error(f"更新Excel文件 {file_path} 的 {column_name} 列数据出现错误,异常信息: {str(e)}")
raise e
def process_search(location):
driver = setup_driver()
try:
return search_address(driver, location)
except Exception as e:
logger.error(f"处理 {location} 时出现错误: {str(e)}")
return None
finally:
driver.quit()
def process_data():
"""
处理数据更新的主逻辑,包括获取需要更新的地址列表、查询新地址、合并数据以及更新Excel文件等操作
:return: 无
"""
file_path = file_entry.get()
read_column = read_column_entry.get()
update_column = update_column_entry.get()
if not file_path or not read_column or not update_column:
messagebox.showerror('请完整填写上述部分内容!')
return
try:
start_time = time.time()
# 获取待查询企业名称列表
address_list_to_update = getColumnData(file_path, read_column)
logger.debug(f"获取到待查询地址列表,长度为: {len(address_list_to_update)}")
# 使用线程池并行处理
with concurrent.futures.ThreadPoolExecutor() as executor:
new_address_list = list(executor.map(process_search, address_list_to_update))
logger.debug(f"获取到更新后的地址列表,长度为: {len(new_address_list)}")
# 更新列
updateExcelColumn(file_path, update_column, new_address_list)
end_time = time.time()
elapsed_time = end_time - start_time
messagebox.showinfo('完成!', f'数据更新完成,总用时:{elapsed_time:.2f}秒')
except Exception as e:
messagebox.showerror("错误", f"发生错误: {str(e)}")
logger.error(f"主逻辑处理出现错误,异常信息: {str(e)}")
except:
messagebox.showerror("更新失败", "在更新列数据时出现错误,请检查。")
logger.error("主逻辑处理出现未知错误")
root = tk.Tk()
root.title("Excel地址更新工具")
tk.Label(root, text="Excel文件路径:").grid(row=0, column=0, padx=10, pady=10)
file_entry = tk.Entry(root, width=50)
file_entry.grid(row=0, column=1, padx=10, pady=10)
tk.Button(root, text="浏览", command=lambda: file_entry.insert(0, filedialog.askopenfilename())).grid(row=0, column=2, padx=10, pady=10)
tk.Label(root, text="需读取列标题:").grid(row=1, column=0, padx=10, pady=10)
read_column_entry = tk.Entry(root, width=50)
read_column_entry.grid(row=1, column=1, padx=10, pady=10)
tk.Label(root, text="需更新列标题:").grid(row=2, column=0, padx=10, pady=10)
update_column_entry = tk.Entry(root, width=50)
update_column_entry.grid(row=2, column=1, padx=10, pady=10)
tk.Button(root, text="开始处理", command=process_data).grid(row=3, column=0, columnspan=3, pady=20)
root.mainloop()
















 2085
2085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









