







 本文探讨了Java中的继承特性,包括子类继承父类的属性和方法,以及子类自身的特有内容。讲解了继承关系中的"is-a"概念,并介绍了定义父类和子类的语法。在成员变量重名的情况下,提出了访问规则的"就近原则",同时阐述了重写(override)和重载(overload)的区别。强调Java单继承但支持多级继承的特性,以及Object类作为所有类的父类的角色。
本文探讨了Java中的继承特性,包括子类继承父类的属性和方法,以及子类自身的特有内容。讲解了继承关系中的"is-a"概念,并介绍了定义父类和子类的语法。在成员变量重名的情况下,提出了访问规则的"就近原则",同时阐述了重写(override)和重载(overload)的区别。强调Java单继承但支持多级继承的特性,以及Object类作为所有类的父类的角色。
继承主要的解决的问题就是:共性抽取
继承关系的特点:
1.子类可以拥有父类的 “内容”
2.子类还可以拥有自己专有的内容
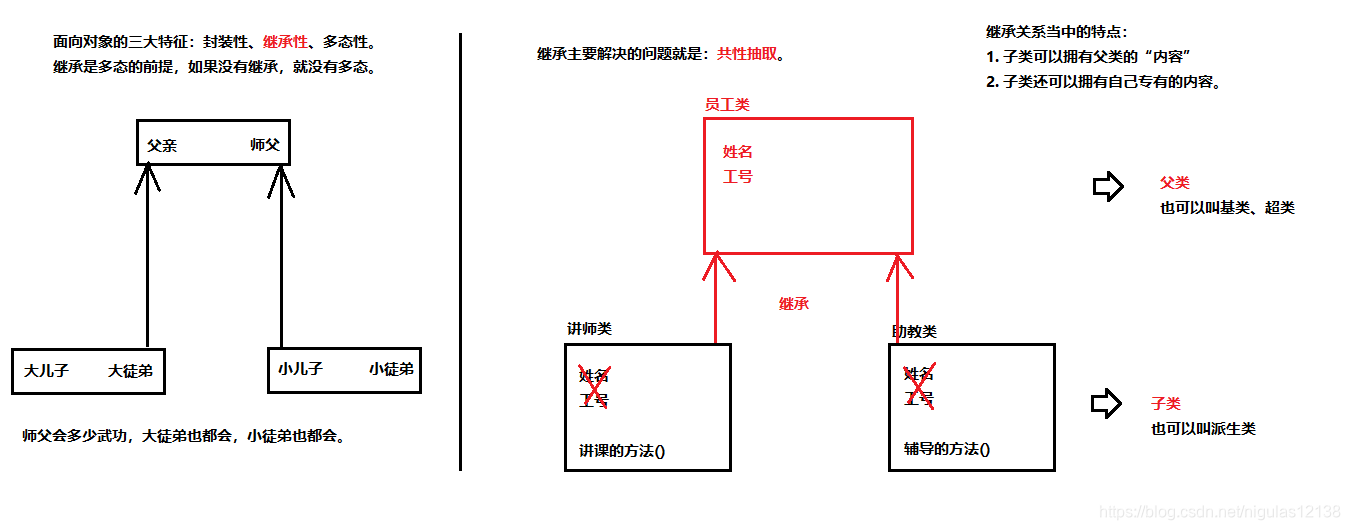
在继承的关系中,“子类就是一个父类”。也就是说,子类可以被当做父类看待。
例如父类是员工,子类是讲师,那么“讲师就是一个员工”。关系:is-a。
定义父类的格式:(一个普通的类定义)
public class 父类名称 {
// …
}
定义子类的格式:
public class 子类名称 extends 父类名称 {
// …
}
main主方法
public class Demo01Extends {
public static void main(String[] args) {
Employee one = new Employee();
one.method();
Teacher two = new Teacher();
two.method();
}
}父类
public class Extends {
public void method(){
System.out.println("方法执行啦");
}
}子类
public class Employee extends Extends{
}public class Teacher extends Extends {
}在父子类的继承关系当中,如果成员变量重名,则创建子类对象时,访问有两种方式:
直接通过子类对象访问成员变量:
等号左边是谁,就优先用谁,没有则向上找。
间接通过成员方法访问成员变量:
该方法属于谁,就优先用谁,没有则向上找。
总结一句话就是:就近原则
在调用不同类的重名变量时:
局部变量: 直接写成员变量名
本类的成员变量: this.成员变量名
父类的成员变量: super.成员变量名
System.out.println(num);//本类成员变量
System.out.println(this.num);//本类方法成员变量
System.out.println(super.num);//父类重写(override):方法名字一样 参数列表一样 继承关系中 (覆盖,覆写)
重载(overload):方法名字一样 参数列表不一样
super this 内存图!
1.new出来的东西都在堆(Heap)当中
2.能写override就写override
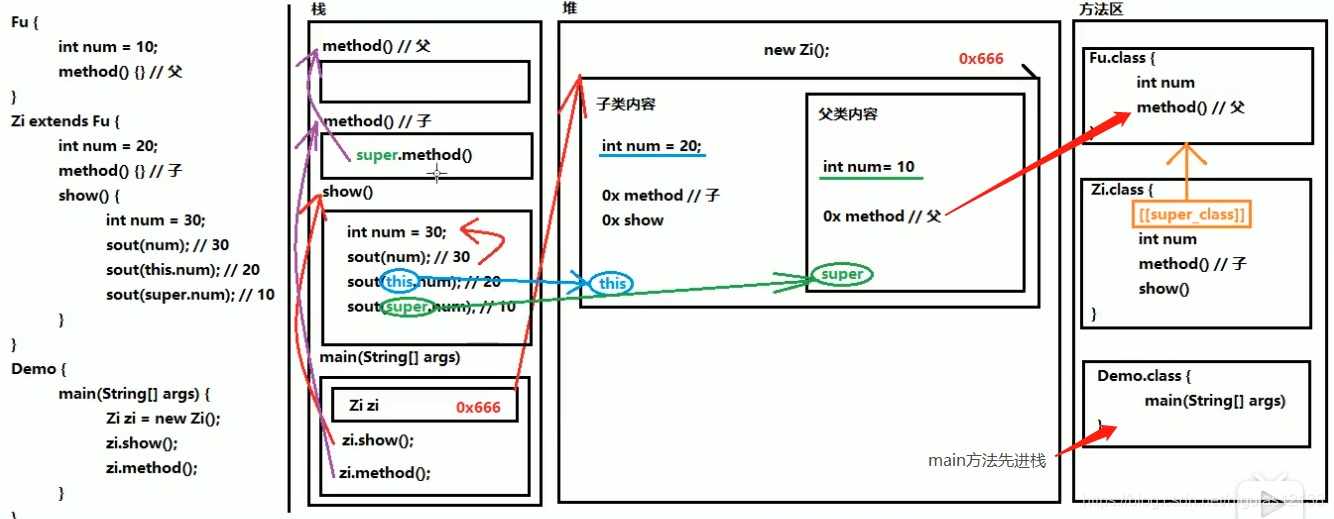
public class Zi extends Fu {
int num = 10;
public void show(){
int num = 20;
System.out.println(num);
System.out.println(this.num);
System.out.println(super.num);
}
public void method(){
System.out.println("子类方法");
super.mothod(); //调用父类方法
}
}***继承的三个重要特征 ***
1.Jvav语言** 是单继承的!**
2.jvavav语言可以多级继承 爷爷 孙子
3.可以有亲兄弟亲姐妹
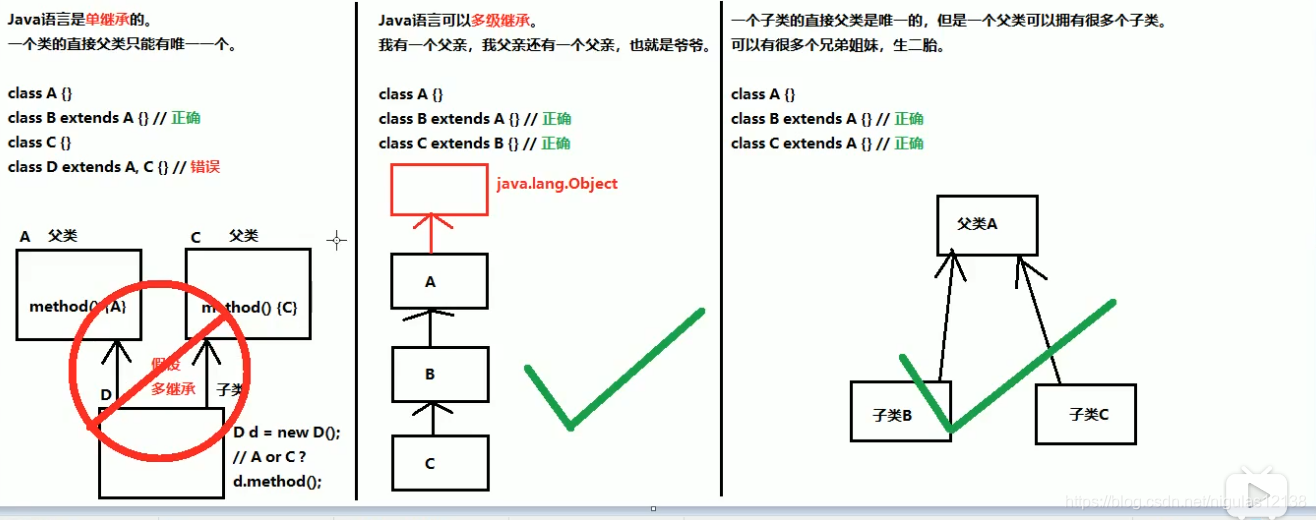 java.lang,Object是亚当最屌所有人的爷
java.lang,Object是亚当最屌所有人的爷
** “品”** 字形的可

















 35
35

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









