










前言
想象一下这些惊悚场景:
-
• 凌晨3点,Broker突然宕机,而你只能对着黑屏的服务器发呆 😱
-
• 大促期间,消息积压像雪球一样越滚越大,却找不到问题根源 📈
-
• 客户投诉"订单状态没更新",你才发现Consumer已经悄悄罢工8小时 💀
本文将手把手教你搭建RocketMQ全景监控体系,让你拥有:
✅ 实时健康检测——像心电图一样掌握集群状态
✅ 智能预警系统——比运维小哥更早发现问题
✅ 全链路追踪——5分钟定位任意消息的下落
一、监控体系三维度CPU/内存/磁盘
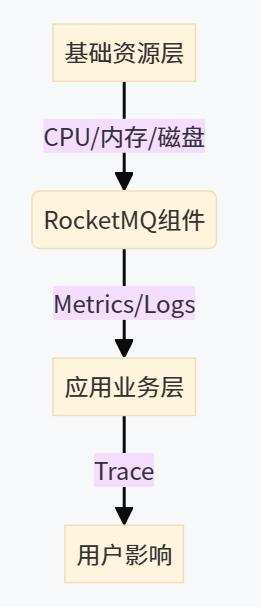
1. 基础资源监控
-
• 监控对象:NameServer/Broker所在服务器的CPU、内存、磁盘、网络
-
• 推荐工具:Prometheus + Node Exporter
2. RocketMQ组件监控
- • 核心指标:
# Broker关键指标 rocketmq_broker_tps_total # 每秒事务数 rocketmq_message_accumulation # 消息堆积量 rocketmq_dispatch_latency # 分发延迟 # Consumer关键指标 rocketmq_consumer_offset # 消费位点 rocketmq_consume_fail_count # 消费失败次数
3. 业务链路监控
-
• 核心需求:
-
• 某条消息是否被消费?
-
• 消费耗时多少?
-
• 失败原因是什么?
-
二、四大监控方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
| RocketMQ Console | 官方出品,开箱即用 | 无告警功能,指标较少 | 开发测试环境 |
| Prometheus+Grafana | 灵活强大,生态丰富 | 需要手动配置 | 生产环境通用方案 |
| ELK日志分析 | 日志追溯能力强 | 实时性较差 | 故障复盘 |
| 商业APM工具 | 全链路追踪 | 成本高 | 金融/电商核心业务 |
三、手把手搭建Prometheus监控
1. 数据采集层配置
# prometheus.yml 配置示例
scrape_configs:
- job_name: 'rocketmq_exporter'
static_configs:
- targets: ['broker1:5557', 'broker2:5557'] # RocketMQ Exporter地址
metrics_path: '/metrics'2. Grafana看板配置
# 导入官方Dashboard模板
grafana-cli --repo https://grafana.com/api/dashboards/10477/revisions/1/download \
rocketmq-dashboard.json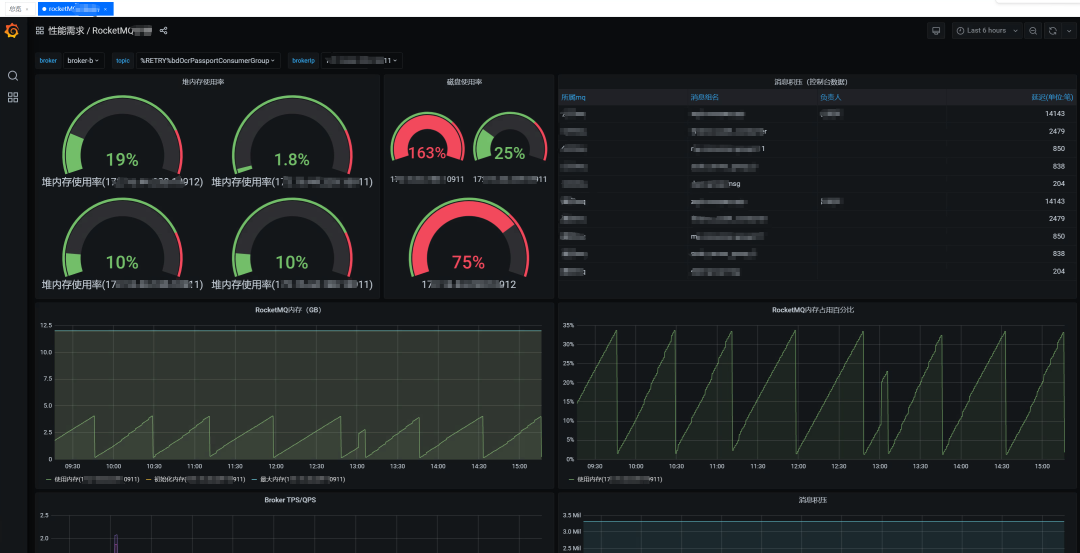
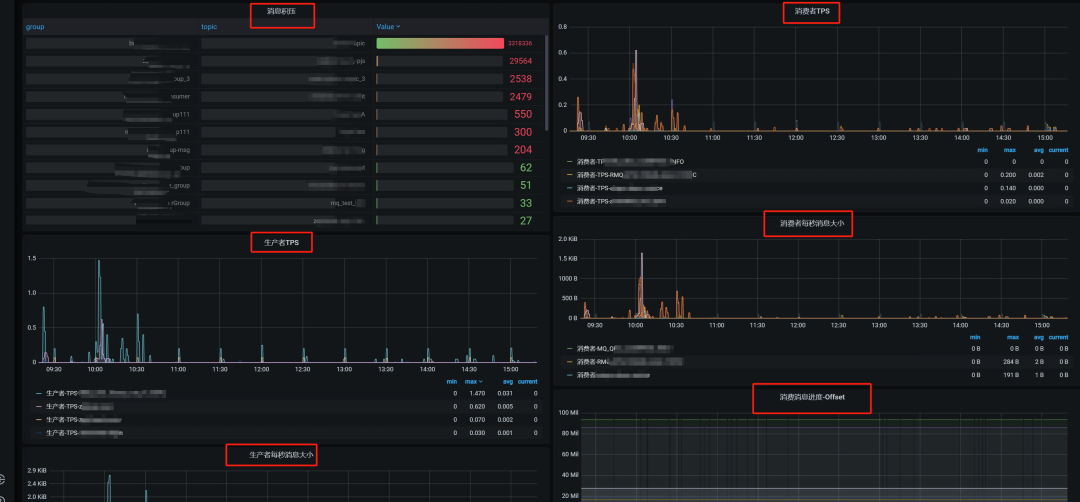
RocketMQ Grafana看板
核心面板说明:
-
• Broker TPS/堆积量:实时消息吞吐趋势
-
• 消费延迟热力图:按Topic展示P99延迟
-
• 线程池活跃度:识别线程阻塞问题
四、智能告警规则配置
1. 关键告警规则(PromQL示例)
# broker_down告警
-alert:BrokerDown
expr:up{job="rocketmq_exporter"}==0
for:1m
labels:
severity:critical
annotations:
summary:"Broker {{ $labels.instance }} 宕机"
# 消息积压告警
-alert:MessageBacklog
expr:rocketmq_message_accumulation>10000
for:5m
labels:
severity:warning
annotations:
summary: "Topic {{ $labels.topic }} 积压 {{ $value }} 条消息"2. 告警分级策略
| 级别 | 条件 | 通知方式 |
| P0紧急 | Broker宕机/积压>10万 | 电话+短信+企业微信 |
| P1重要 | 消费失败率>5% | 企业微信+邮件 |
| P2提示 | CPU持续>80% | 邮件 |
五、消息轨迹追踪实战
1. 开启消息轨迹
// 生产者配置
DefaultMQProducer producer = new DefaultMQProducer("PG_Order");
producer.setNamesrvAddr("name-server:9876");
producer.setTraceDispatcher(new AsyncTraceDispatcher()); // 启用轨迹
// 消费者配置
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("CG_Stock");
consumer.setTraceDispatcher(newAsyncTraceDispatcher());2. 查询消息轨迹
# 通过MessageID查询(控制台或API)
./mqadmin queryMsgById -n name-server:9876 -i "0A123B456C"输出示例:
MessageID: 0A123B456C
轨迹记录:
1. 2023-08-20 14:00:00 Producer发送成功 (耗时2ms)
2. 2023-08-20 14:00:01 Broker存储完成 (耗时15ms)
3. 2023-08-20 14:00:03 Consumer消费失败 (错误: NullPointerException)
4. 2023-08-20 14:00:05 进入重试队列六、生产环境监控最佳实践
1. 多租户隔离监控
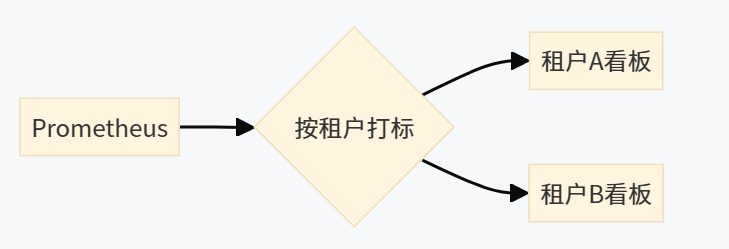
2. 容量规划预警
# 基于历史数据的预测脚本(示例)
def predict_storage_need():
daily_growth = get_metric('rocketmq_storage_usage[7d]')
required_disk = daily_growth * 30 * 1.5 # 保留30天+50%缓冲
if current_disk < required_disk:
trigger_alert()3. 故障自愈方案
# 自动处理Consumer积压的脚本
#!/bin/bash
if [ $(rocketmq_consumer_offset -g CG_Order) -gt 100000 ]; then
kubectl scale deploy order-consumer --replicas=10
send_alert "已自动扩容OrderConsumer"
fi七、避坑指南
1. Exporter性能问题
-
• 症状:监控采集导致Broker CPU飙升
- • 解法:调整采集间隔
# prometheus.yml scrape_interval: 30s # 默认15s改为30s
2. 消息轨迹丢失
-
• 症状:部分消息查不到轨迹
- • 解法:检查轨迹Topic配置
# broker.conf traceTopicEnable=true traceTopicName=RMQ_TRACE_DATA
3. 告警风暴
-
• 症状:半夜被数百条短信轰炸
- • 解法:配置告警聚合
# alertmanager.yml group_by: [alertname, cluster] group_wait: 30s
结语
通过本文你已掌握:
✅ 三层监控体系:从硬件到业务的立体观测
✅ 四大方案选型:开源与商业工具的优劣对比
✅ 智能告警设计:分级预警+自动故障处理
✅ 消息全链路追踪:5分钟定位任意消息异常
终极建议:
-
• 开发环境用RocketMQ Console快速验证
-
• 生产环境必上Prometheus+Grafana
-
• 核心业务补充全链路追踪

















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









