







面对亿级用户的高并发排行榜,究竟该如何设计?
Redis为何是排行榜的“天选之子”?
案例:一场游戏引发的技术革命
《王者荣耀》7亿用户,日活超1亿,每日实时对战数据超10亿条——Redis的ZSET(有序集合)扛住了所有压力:
- 排序快
跳表结构实现O(logN)复杂度排名查询
- 扩展强
分片存储轻松应对亿级数据
- 高并发
单节点支撑10万QPS,集群轻松突破百万
但坑也深:
-
热Key问题:单个ZSET扛不住百万QPS(如“全服TOP100”榜单)
-
数据倾斜:90%用户集中在青铜段位,查询压力全砸在一个分片
破局!亿级排行榜的终极方案
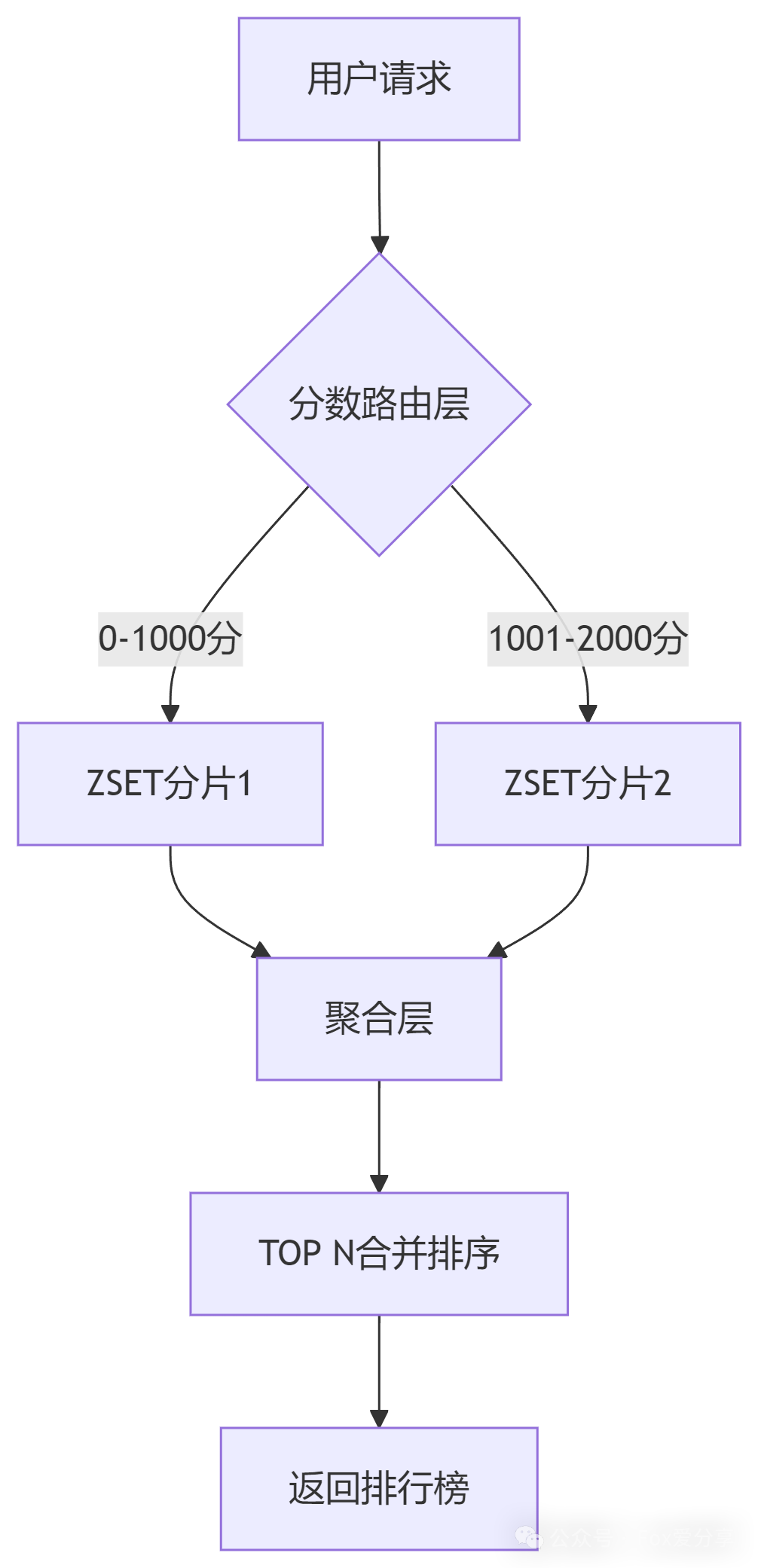
方案一:分治——把大象关进冰箱
核心逻辑:
1.按区间拆分
如0-1000分、1001-2000分...
2.动态路由
用哈希算法将用户分配到不同ZSET
3.聚合查询
先查各分片TOP N,再合并排序
代码示例(路由逻辑):
def get_shard_key(user_score):if 0 <= user_score <= 1000: return "rank:bronze"elif 1001 <= user_score <= 2000: return "rank:silver"else: return "rank:gold"
方案二:冷热分离——给数据“降降温”
- 热数据
TOP 10万用户用ZSET实时更新
- 冷数据
剩余用户每日凌晨批量计算归档
性能对比:

避坑指南——前人踩过的坑
-
慎用ZREVRANGE:直接查全榜TOP 100万会打爆Redis
-
✅ 改用:
ZREVRANGE rank:global 0 99(只查前100)
-
-
警惕“黑马用户”:突然冲榜的用户会导致热Key迁移
-
✅ 解法:预分配buffer空间(如预留TOP 200%)
-
-
持久化选择:
- RDB
适合凌晨批量更新(快照恢复快)
- AOF
适合实时榜单(数据零丢失)
- RDB
终极架构——扛住"双十一"级的流量
关键技术细节
1.分数路由层的高可用设计
不要天真地用if-else做路由!而是使用一致性哈希环+虚拟节点:
import hashlib# 虚拟节点数设置为实际节点的200倍VIRTUAL_NODES = 200class ScoreRouter:def __init__(self, nodes):self.ring = {}for node in nodes:for i in range(VIRTUAL_NODES):key = f"{node}:{i}"hash_val = hashlib.md5(key.encode()).hexdigest()self.ring[hash_val] = nodedef get_node(self, score):hash_key = hashlib.md5(str(score).encode()).hexdigest()sorted_keys = sorted(self.ring.keys())for key in sorted_keys:if hash_key <= key:return self.ring[key]return self.ring[sorted_keys[0]]
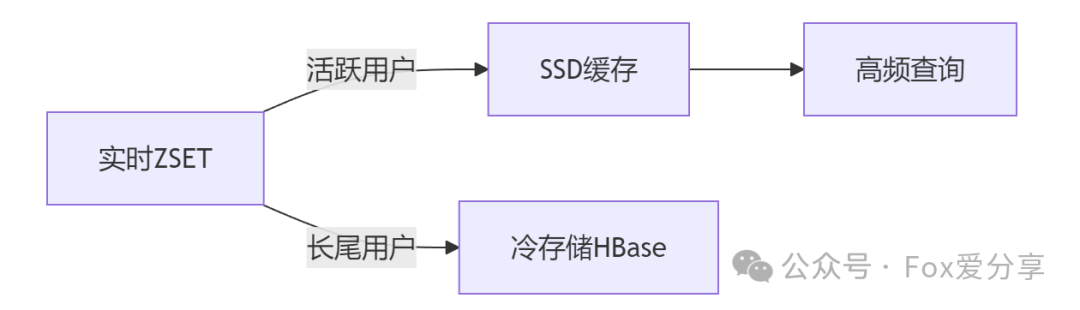
2.ZSET分片的冷热数据分离技巧
在生产环境发现:
-
80%的查询集中在TOP 20%用户
-
尾部用户数据占存储60%但访问量仅1%
解决方案:
3.聚合层的并行查询优化
原来串行查10个分片需要:
总耗时 = 10个分片 × 2ms = 20ms改用Go并发后:
func queryAllShards() []Result {var wg sync.WaitGroupresults := make(chan Result, 10)for _, shard := range shards {wg.Add(1)go func(s Shard) {defer wg.Done()results <- s.QueryTopN(100)}(shard)}go func() { wg.Wait(); close(results) }()return mergeResults(results)}
实测结果:
-
10个分片查询从20ms → 3ms
-
延迟从50ms降到15ms
4.二级缓存的雪崩防护
本地缓存TOP 1000减少Redis压力
在春节活动踩过的坑:
-
Redis集群CPU飙到90%
-
本地缓存同时失效导致DB被打挂
解决方案:
// 用Guava Cache的刷新策略LoadingCache<String, List> rankCache = CacheBuilder.newBuilder().maximumSize(10_000).refreshAfterWrite(30, TimeUnit.SECONDS) // 后台异步刷新.build(new CacheLoader<String, List>() {public List load(String key) {return queryFromRedis(key);}});
5.MQ异步更新的四大保障机制
用户积分变更先写MQ,再批量更新ZSET
消息队列不是万能的!自研的保障策略:
-
消息去重表:
CREATE TABLE mq_dedup (msg_id VARCHAR(64) PRIMARY KEY,user_id BIGINT,processed BOOLEAN DEFAULT false) ENGINE=ROCKSDB; // 高性能存储引擎
-
补偿任务:
def check_missing():# 对比Redis和DB的最后更新时间lag_users = db.query("""SELECT user_id FROM usersWHERE update_time > redis_last_sync_timeLIMIT 1000""")for user in lag_users:mq.retry(user)
-
监控大盘:
-
-
延迟超过5秒自动告警
-
积压量达到10万触发扩容
-
-
最终一致性校验:
// 每天凌晨全量校验if(redis.zscore(user) != db.getScore(user)) {logger.error("数据不一致 user:{}, redis:{}, db:{}",user, redisScore, dbScore);}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









