







一切要从探讨指针的类型说起。
运行环境:Ubuntu 20.04.1 LTS 64-bit
预先准备:调整字节对齐单位为1,防止为4时因填充导致人脑判断失误
#pragma pack(1)
01
—
缘起:指针的类型
《深入探索C++对象模型》里面有提到不同类型的指针之间的不同。对于一个自定义的class,一个指向它的指针和一个指向int型整数的指针有何不同呢?
从内存的角度来看,没有什么不同!为什么?来看一个很简单的程序:
cout << "sizeof(int) = " << sizeof(int) << endl;
cout << "sizeof(size_t) = " << sizeof(size_t) << endl;
cout << "sizeof(ZooAnimal) = " << sizeof(ZooAnimal) << endl << endl;
cout << "sizeof(int *) = " << sizeof(int *) << endl;
cout << "sizeof(size_t *) = " << sizeof(size_t *) << endl;
cout << "sizeof(ZooAnimal *) = " << sizeof(ZooAnimal *) << endl;
//ZooAnimal自定义类,包含1个int型数据和1个std::string类对象
看一下运行结果:
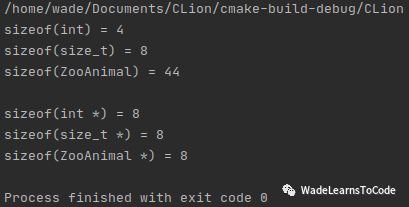
为什么三个数据类型占用内存的大小明显不同,但是指向他们的指针的大小却相同?
这是因为,指向不同类型的指针之间的差异,不在于表示法不同,也不在于所寻址内容不同,而是在于不同类型的指针的“类型”会教导编译器如何解释某个特定内存地址中的内存内容,同样的二进制数据,换种解释方式,将产生天壤之别的解释结果。

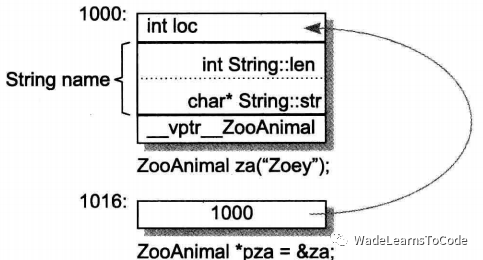
一个指向内存地址为 0x 00 00 7f fc 2e fb 40 e0 的ZooAnimal指针,将从这个地址(首地址)开始,涵盖一段大小为sizeof(ZooAnimal)的内存空间,来表示这个指针指向的对象在内存中的二进制存储:

为什么同一平台上不同类型的指针大小都是8bytes?
这是因为不同机器上的指针的寻址范围,必须涵盖当前运行环境的最大寻址范围。换句话说,一个指针的大小,取决于当前运行环境的字长(word)。对于32位的机器上,其4bytes大小的指针将涵盖可供寻址的4GB地址空间。
02
—
疑惑的源头:同一个对象,不同的成员
先来看一下我的ZooAnimal类是怎么实现的:
class ZooAnimal {
protected:
int loc = 0x67453412;
string name;
public:
ZooAnimal() { SelfDescription(); }
ZooAnimal(string str) : name(str) { SelfDescription(); }
~ZooAnimal() { SelfDescription(); }
};
当我在主函数里这样实例化时:
ZooAnimal za("Wade");
我们来查看下内存:
没问题,和上次一样。但是当我这样实例化时:
ZooAnimal za("WadeLearnsToCode");

存储结构都变了,原先在这个类的二进制存储里还能看见"Wade"的ASCII码表示,现在居然看不到了?
更惊奇的事还在后面:
ZooAnimal za("WadeLearnsToCode");ZooAnimal zb("Wade");cout <sizeof(za) ==
居然给我输出true.......
03
—
探究std::string有效数据存储结构
那好吧有问题来了就着手解决。从上文我们知道,ZooAnimal以如下的内存模型存储数据成员:

以za("HuazhongUniversityOfSci&Tech")为例,我们看其内存二进制存储,再结合先前得到的sizeof(int) == 4的结论,我们把loc设置为 0x 67 45 34 12,便不难印证上述模型。

那好,剩下的32字节就应该是其std::string数据成员的二进制存储了。
我们数一下
"HuazhongUniversityOfSci&Tech"
有多长:28个字符。
十进制的16怎么用16进制表示:0x 00 00 00 00 00 00 00 1c
看一下二进制内存部分字段表示:

标蓝的地方就是 0x 00 00 00 00 00 00 00 1c,说明std::string的内存模型中,存储着字符串实际的长度(size_t类型,sizeof(size_t) == 8)。
那它前面的是什么?za的地址为 0x 00 00 7f fe 05 77 6e f0,它前面的那8个字节是 0x 00 00 55 6f fe a2 52 f0,是不是和za的地址长得很像?!那这个也许是地址的地址里存储着啥呢?来瞅一眼哦:

事情很明白了,存储着std::string类型里的实际char []字符串的首地址。但是这个字符串的ASCII码并没有在za的存储空间里显式表示。
但是后面还有两个8字节的内容呢?紧邻着字符串实际长度的值和实际长度一样诶,我们先不管它。
再来看一下za("Wade")的情况:

很好,"Wade"在二进制内存中直接显示了,而本应该在长度前面的那个字符串首地址,变成了内存中"Wade"的存储位置:

而且长度后面的那8bytes表示的数据也并不是像上一种类存储长字符串时,其值和字符串长度一样。
04
—
他山之石:std::string的成员
对于标准库和STL的问题,悬而不决就看源代码,看一下成员:

也侧面证实了自己的猜想。
指针刚才说过了,没什么可说的,来看一下_String_val这个成员:
enum {
// length of internal buffer, [1, 16]
_BUF_SIZE = 16 / sizeof(value_type) < 1 ? 1 : 16 / sizeof (value_type) };
union _Bxty { // storage for small buffer or pointer to larger one
value_type _Buf[_BUF_SIZE];
pointer _Ptr;
char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;
size_type _Mysize; // current length of string
size_type _Myres; // current storage reserved for string
很好,_BUF_SIZE定义了缓冲区的长度:
1. 如果value_type类型小于1byte,那么_BUF_SIZE = 16
2. 否则,_BUF_SIZE = 16 / sizeof(value_type)从标准草案看一下value_type是个啥:
typedef typename traits::char_type value_type;X::char_type -> charTcharT -> char
就是个char。
也就是说,如果std::string的字符串长度小于16个字符,那么
1. 联合将直接存储该字符串
2. 指针指向std::string的联合数据成员的char数组地址
3. 长度成员将存储字符串长度
如果std::string的字符串长度大于16个字符,那么
1. 指针指向那个真正包含内容的char数组的首地址
2 长度成员将存储字符串长度
05
—
std::string的内存分配
一、栈中std::string的内存分配
我们首先进行全局重载new和delete运算符,在于当进行堆内存分配时,显式告知用户
#include
using namespace std;
void *operator new(std::size_t count) {
cout << "分配堆内存" << count << "字节" << endl;
return malloc(count);
}
void operator delete(void *p) {
cout << "分配堆内存" << p << endl;
free(p);}
void show_str(const string &str) {
cout << endl;
cout << __func__ << "() 临时变量初始化" << endl;
string tmp = str;
printf("str的副本地址: %p\n", str.c_str());
printf("tmp的副本地址: %p\n", tmp.c_str());
}
int main() {
cout << endl; cout << "-------初始化string对象-------" << endl;
string you = "Hello World!";
cout << endl;
cout << "-------show_str-------" << endl;
printf("main函数: you副本中的字符串地址: %p\n", you.c_str());
show_str(you);
cout << endl;
cout << "字符串字面量直接传参方式" << endl;
show_str("Hello World!");
cout << endl;
cout << "字符数组传参方式" << endl;
const char mes[] = "Hello World!";
printf("main函数: mes副本中的字符串地址: %p\n", mes);
show_str(mes);
cout << endl;
return 0;}/*Hello World!Hello World!Hello World!*/
可以看到三种方式下tmp副本的地址都是相同的,因为如果std::string的长度较小,那么它直接用std::string里的char数组成员存储,所以三个tmp副本的地址都是相同的,都存储在栈上,在这种情况下它们三个tmp临时变量都是字符数组
二、堆上std::string的内存分配
我们把字符串改的长一点,让它大于16bytes,运行一下:
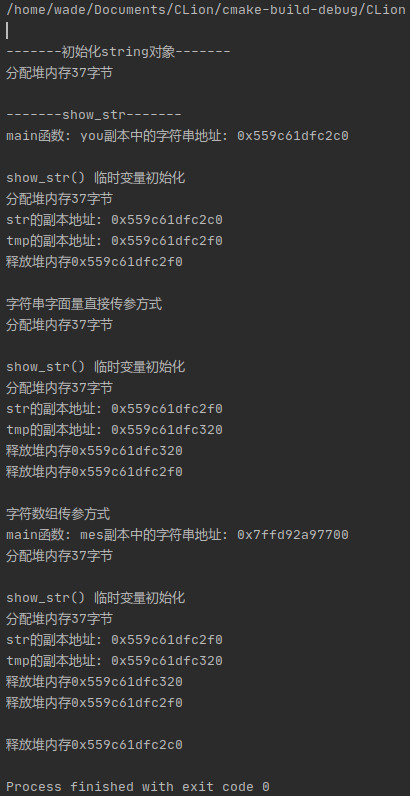
这时std::string的内存分配已经发生了变化,它们的内部数据成员分别指向了各自堆中分配的内存块上图输出都调用了void* operator new(size_t)的重载版本。
这时我们就要思考两个问题
为什么处理"Hello World!"只在栈中进行内存分配?
为什么处理"Hello World!Hello World!Hello World!"就会在堆中进行内存分配?
答案就是因为字符串的字面长度决定的。具体是在栈上分配还是在堆上分配内存,触发阈值如下表:
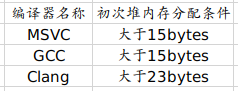
std::string内部约定
1. 只要传入的字符串长度小于上表阈值,就在栈上分配内存,即小型字符串优化(Small String Optimisation)
2. 在堆上分配内存时,std::string内部进行隐式执行new操作
3. 根据RAII的约定,编译器会对std::string生命周期结束时自动garbage collect
相关资源:用c++比较两个字符串的大小_c++字符串比较,c++字符串比较大小-C++...
————————————————
版权声明:本文为CSDN博主「Rubix-Kai」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_42234168/article/details/113048328















 2336
2336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









