










文章目录
1.SVM的loss是啥?
SVM的损失函数是合页损失,合页损失函数不仅仅惩罚错误的预测,还惩罚不自信的成功预测。因此,我们在不过度关注准确性的实时决策时使用它。
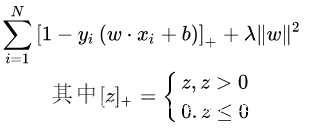
第一项是损失函数,第二项是正则化,防止过拟合。在损失函数零区域内的都是非支持向量,并不参与最终超平面的决定,这是支持向量最大的优势。对训练样本的依赖大大减少,训练效率高。
除此之外,损失函数还可以是指数损失y=exp(-x)和对率损失y=log(1+exp(-x))
2.kmeans聚类如何选择初始点?
kmeans是一种无监督算法。聚类需要确定两个点
- 如何选择聚类的类别数目
- 如何选择初始聚类的位置
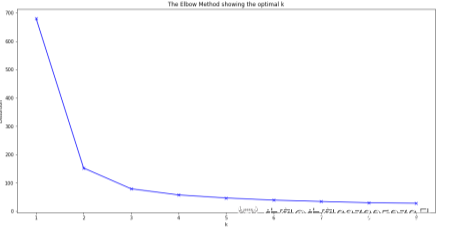
(1)确定聚类数目的方法是“手肘法”,即将所有可能聚类的类别数目都列举出来,寻找它们对应的损失函数。在损失函数产生拐点的地方就是我们需要确定的类别。如有100个样本,则可能的类别是2~100类,计算每个可能类别数目下的损失函数
(2)确定初始点的位置: - 随机选择n个类的初始点;
- 计算其他样本到这n个初始点的距离,将所有样本分成n类;
- 在n类的每一个类内作平均,确定新的聚类中心;
- 当聚类中心不再发生改变,聚类完成。
样本与聚类中心之间的距离计算
欧式距离:
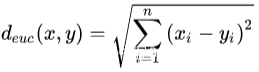
曼哈顿距离:
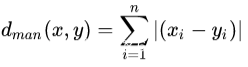
3. RF和GBDT谁更容易过拟合,偏差和方差
偏差:是反映学习算法期望预测的结果与真实结果之间的偏差,表征模型的准确度,算法的拟合能力
方差:方差是描述针对不同的数据集模型学习性能的变化,表征模型的稳定度,反映预测的波动情况
偏差和方差通常都是互相矛盾的。
GBDT:GBDT是为了解决决策树过拟合问题的算法。具体操作是训练每一棵树学到的是上一层所有树的结论和的残差。即采用的是上一轮训练后得到的预测结果与真实结果之间的残差。因此,随着树的个数增加,它的训练偏差会一直减小,甚至会为零。但是测试的时候误差反而很大,这就是过拟合。
RF:随机森林是将数据集分成多个部分,每个部分对应一棵根节点树进行训练,每棵树内根据某一属性判断上一节点数据该进入哪个子节点。最后将所有树的结论取众数(分类)或平均(回归)。
4. xgb的分类树也是用残差吗,不是的话是什么
xgb不同于GBDT,它采取的是回归树,返回的值也是回归值。它的本质也是在每一轮之后尽可能降低损失函数,它的做法是对每一轮训练完的损失函数作泰勒展开,然后直接求取决策树的最优叶子值。所以,给定一棵树,xgb能够给出它的最优叶子值,但是很难直接找到这棵树。要采取贪心算法逐级分裂,分裂的步骤和决策树几乎没有区别,区别就在于泰勒展开那部分。
损失函数:logloss = ylogp+(1-y)log(1-p),p = 1/(1+exp(-x))
5. 讲讲数据倾斜怎么处理
数据倾斜:在大数据场景中,MapReduce程序执行时,有一个或几个reduce节点里面由于包含了太多的key,因此执行这几个reduce就会浪费更多的时间。解决的办法是如何将数据均匀分配到每一个reduce中。
MapReduce流程
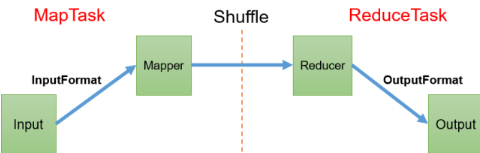
- 增加jvm的值,适用于唯一值比较少,极少数值非常多的情况,硬件增加jvm内存;
- 增加reduce个数,适用于唯一值比较多的情况,唯一值比较多的意思是有多个相同的key会被分到同一个reduce,因此需要增加reduce的个数;
- 重新设计key,在map阶段给key加上一个随机数,这样key就会被分到不同的reduce中,reduce后再把随机数去掉;
- 使用combinner,在map和reduce之间加上一个combinner,这个combinner可以将数据中key相同的先打包在一起,再交给reduce来处理。
6. 请你说说SVM的优缺点
优点:
- 解决小样本下机器学习问题;
- 可以解决高维问题,借助核函数映射到高维特征空间;
- 泛化能力较强;
- 无需依赖整个数据;
- 没有局部最小值问题;
- 能够处理非线性特征;
- 最终决策函数只需要支持向量决定,计算复杂度取决于支持向量数目,降低了维数灾难;
- 理论基础扎实,分类问题可以从原理上解释。
缺点:
- 常规SVM只支持二分类;
- 对缺失数据敏感;
- 对非线性问题没有通用解决方案,有时候很难找到合适的核函数;
- 样本很多时,效率不是很高;
- 对于核函数的高维映射可解释性不强。
7.LR和SVM的联系与区别
LR作为线性回归,它是通过预测一个线性函数y=a*x+b的参数。它的优化目标是让估计值尽可能接近真实值。
LR和SVM常规下都是作为二分类的线性模型,都可以经过核函数用来做非线性的预测。LR使用的是所有样本来计算,而SVM仅仅使用支持向量来决定几何超平面;LR的回归结果是一个处于[0,1]之间的概率值,而SVM给出的是0或1。
8.请你说说RNN的原理
RNN是递归神经网络,是以序列数据作为输入,所有节点按照链式连接的。它能够挖掘数据中的时序信息和语义信息。
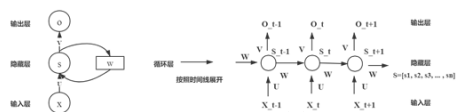
RNN的每一层权重是不变的,它的某一个隐藏层的数据不仅仅于当前时刻的输入有关,还与上一时刻的隐藏层输出有关。即它能够记住每一时刻的信息。
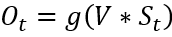
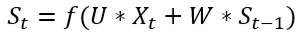
9. xgb的boosting如何体现,有什么特殊含义
XGboosting是将多个弱分类器集成在一起,形成一个强分类器。它是一种集成学习方法,每个弱分类器叫做基学习器,每个基学习器的学习算法可以相同,也可以不同。
XGboosting与GBDT一样,是一棵树一棵树进行学习,下一棵树的训练数据是上一棵树的残差,也就是上一轮训练的预测值和真实值之间的残差。当训练完成所有的树后,预测一个样本的分数,这个分数就是将每棵树对应的最后一个叶子节点分数相加起来即可。
它的目标函数为
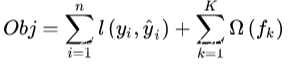
第一项是损失函数,第二项是正则化。
它使用的树模型是CART回归模型。
10. 过拟合有哪些,你会从哪方面调节
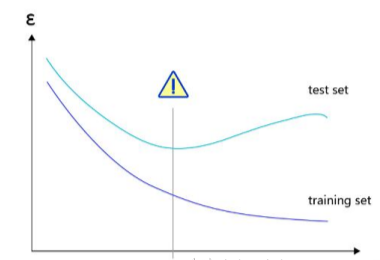
过拟合产生的原因是数据太简单,而模型太复杂,导致训练的结果很好,但是测试的结果很差。表现差的原因是学习模型能力太强,从数据中学到了统计噪声。
改进的方法可以从数据上、模型上以及训练方式上优化:
数据上:
- 增加数据量
- 数据增强(mix up, fix up等方式增强)
理论上只要数据量足够大就不会出现过拟合和欠拟合,但是无疑增加了计算复杂度,并且数据获取和制作难度很大
模型上:
- 使用小模型
- L1和L2正则化
- Dropout
- BathNormalization(BN)
- 使用残差结构(ResNet中提出)
如果数据不好增强,那么可以考虑减少模型的复杂度,如减少神经元个数,网络层数,减少网络参数等
训练方式上:
采取early stopping形式,在模型训练过程中时刻关注测试误差和训练误差,在过拟合之前停止训练。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









