







一、控制已经打开页面的浏览器(已登录状态)
1、简述:
自动化执行时,一些页面操作需要用户是登录状态才能进行访问。如果每次运行自动化脚本都需要重新登录、输入短信验证码,不利于自动化快速运行。因此,需要自动化脚本,需要控制已经打开的页面对应的浏览器,进行自动化操作。
2、一般操作步骤:
1> 运行cmd,启动浏览器
2> 在打开的浏览器中手工进行登录
3> 运行python脚本,控制已经打开的浏览器,再进行后续操作
3、具体操作运行:
1)先在windows的cmd模式下运行以下代码,或者保存为.bat脚本点击运行;
运行成功后,会启动浏览器,打开一个标签页
start_chrome.bat脚本:
cd /d C:\Users\nikey\AppData\Local\Google\Chrome\Application
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\selenum\AutomationProfile"
pause- C:\Users\nikey\AppData\Local\Google\Chrome\Application
改为自己本地chrome安装目录
- remote-debugging-port=9222
指定的端口号(在后续python脚本中会使用,需指定未占用的端口号)
- user-data-dir="C:\selenum\AutomationProfile"
自动化运行时指定的配置文件,这样不会覆盖用户的默认配置文件
2)通过指定端口号,控制已经打开的浏览器
from selenium import webdriver
import time
# 控制已经打开的浏览器,端口号使用cmd运行时指定的端口号
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
bro = webdriver.Chrome(options=chrome_options)
bro.maximize_window()
# 访问一个网页
url = 'https://www.baidu.com/'
bro.get(url)
time.sleep(1)二、浏览器相关操作
1、自动化脚本运行完毕后,不自动关闭浏览器
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True) #不自动关闭浏览器
options.add_argument('--start-maximized')#浏览器窗口最大化
bro = webdriver.Chrome(options=options)
bro.get('https://www.baidu.com')
2、关闭浏览器标签页、退出浏览器
from selenium import webdriver
# 启动浏览器, 打开百度页面
bro = webdriver.Chrome()
url = 'https://www.baidu.com/'
bro.get(url)
# 关闭当前标签页
bro.close()
# 退出浏览器
bro.quit()3、浏览器多个操作功能
1)打开新的标签页
2)切换到新的标签页
3)模拟鼠标滚轮滑动至页面底部
4)获取当前页面源码,通过关键字定位到需要截取的字段
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True) #不自动关闭浏览器
options.add_argument('--start-maximized') #浏览器窗口最大化
bro = webdriver.Chrome(options=options)
url = 'https://www.baidu.com'
bro.get(url)
print(bro.title)
new_url = 'http://news.baidu.com/'
# 打开新的标签页
new_window = 'window.open("{}")'.format(new_url) # js函数,此方法适用于所有的浏览器
bro.execute_script(new_window)
# 获取所有的句柄(打开新标签后,要重新获取窗口句柄)
windows = bro.window_handles
# 切换到 新打开的标签页
bro.switch_to.window(windows[1])
print(bro.title)
# 模拟鼠标滚轮,滑动页面至底部
js = "window.scrollTo(0, document.body.scrollHeight)"
bro.execute_script(js) # 模拟鼠标滚轮,滑动页面至底部
# 获取当前页面的源码
page_text = bro.page_source
# print(page_text)
# 查找HTML页面中的关键字(页面中有多个,查找最后一个):upload_list_tr
key_str = 'upload_list_tr'
key_str_pos = page_text.rfind(key_str)
# print(key_str_pos)
# 通过字符串截取,找到fdId编号,通过fdId打开新的标签页
fdId = page_text[key_str_pos-41:key_str_pos-9]
# print(fdId)
new_file_url = 'http://news.baidu.com/view.jsp?fdId=' + fdId
print(new_file_url)
# 打开新的标签页
new_window = 'window.open("{}")'.format(new_file_url) # js函数,此方法适用于所有的浏览器
bro.execute_script(new_window)
time.sleep(1)
# 关闭当前页面
# bro.close()
# 切换到 第一个打开的标签页
bro.switch_to.window(windows[0])
print(bro.title)
4、页面中内嵌iframe,定位iframe中的xpath
from selenium import webdriver
from selenium.webdriver.common.by import By
url = 'https://www.XXXXXX.com'
bro = webdriver.Chrome()
bro.get(url)
# 切换到iframe中,才能识别数据的xpath标签
# 获取iframe的xpath
iframe_xpath = '/html/body/div[4]/div[1]/div/div/div[3]/div/div/div[2]/div/div[1]/div/div/iframe'
iframe = bro.find_element(By.XPATH, iframe_xpath)
# 获取iframe标签中的属性值
attr_value = iframe.get_attribute("kmss_fdid")
print(attr_value)
# 切换进入iframe中
bro.switch_to.frame(iframe)
# 定位到iframe中记录的xpath,点击记录
xpath = '/html/body/div[4]/div/div[4]/div[1]/div/div/table/tbody/tr[1]'
bro.find_element(By.XPATH, xpath).click()常见问题解决方法:
1、Debugger Console 出现乱码
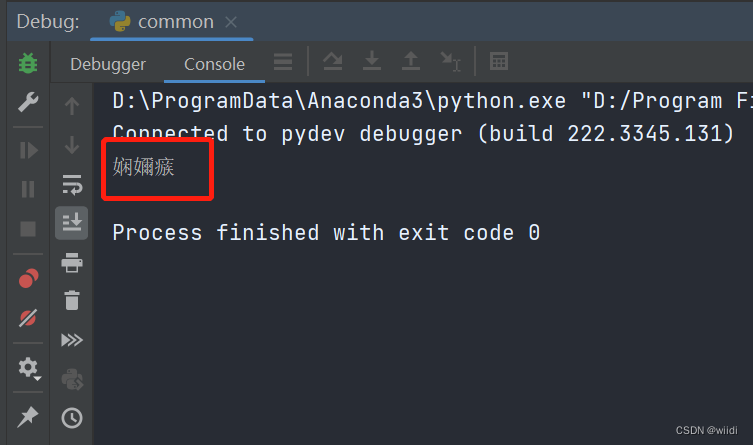
File Encoding 修改Project Encoding为GBK即可。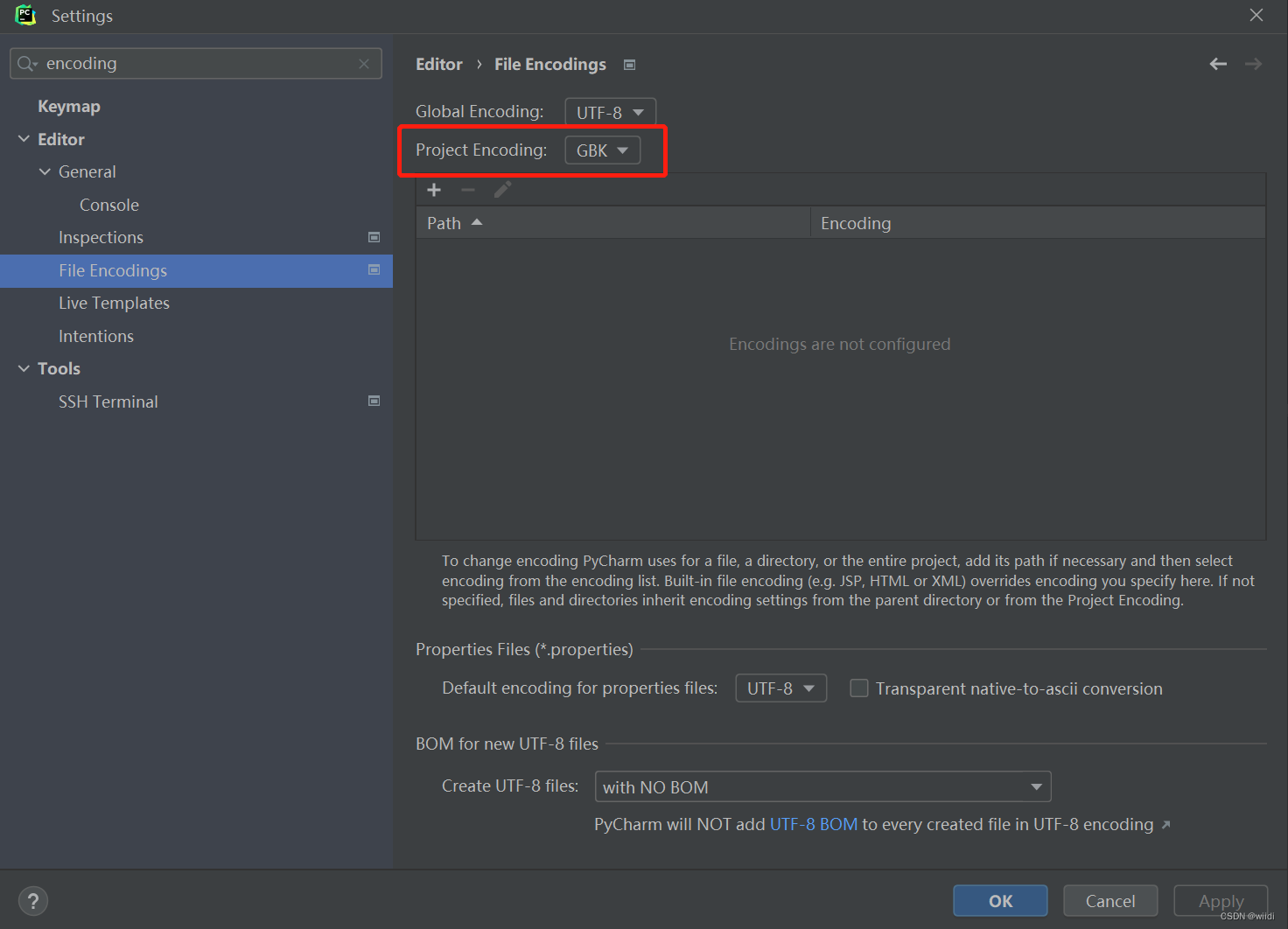















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









