







前言
理解神经网络中的向前传播和向后传播计算对于理解神经网络工作机制是很重要的。吴恩达老师的视频是通过列举具体的公式和数据,还原向前传播和向后传播计算过程,来让我们理解他们的。
总之这个地方对于导数的知识是有要求的,但是由于我们老师已经开始讲数据挖掘预测了,我这博客更新的内容还处于初级阶段,所以导数的内容我不再赘述,需要补数学的同学去哔哩哔哩搜索宋浩老师,看有关导数的几节视频就可以了,其他的像贝叶斯以后会用到,现在看也行,以后看也行。
废话不多说,我们开讲。
向前传播和向后传播
深度学习指的是数以百千层的层数很深的神经网络,每层又有数以百千个神经元。那么深度学习是否也可以使用这种形式的梯度下降来进行调节权重呢?答:很难。为什么?主要原因是太深了。为何“深”用梯度下降解会有问题呢?主要是因为链式法则导致计算损失函数对前面层权重的导数时,损失函数对后面层权重的导数总是被重复计算,反向传播就是将那些计算的值保存减少重复计算。不明白?那这篇文章就看对了。接下来将解释这个重复计算过程。反向传播就是梯度下降中的求导环节,它从后往前计算导数重复利用计算过的导数而已。
可以说,一个神经网络的计算,都是按照前向或反向传播过程组织的。
首先我们计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。
后者我们用来计算出对应的梯度或导数。计算图解释了为什么我们用这种方式组织这些计算过程。在这篇笔记中中,我们将举一个例子说明计算图是什么。让我们举一个比逻辑回归更加简单的,或者说不那么正式的神经网络的例子。

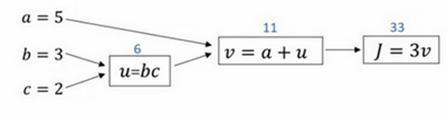
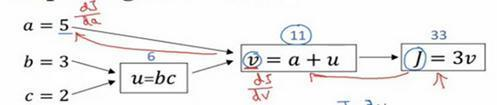
我们尝试计算函数J,J是由三个变量a,b,c组成的函数,这个函数是3(a+bc) 。计算这个函数实际上有三个不同的步骤,首先是计算 b 乘以 c,我们把它储存在变量u中,因此u=bc; 然后计算v=a+u;最后输出J=3v,这就是要计算的函数J。
我们可以把这三步画成如下的计算图,我先在这画三个变量a,b,c,第一步就是计算u=bc,我在这周围放个矩形框,它的输入是b,c,接着第二步v=a+u,最后一步J=3v。
举个例子: a=5,b=3,c=2 ,u=bc就是6,就是5+6=11。J是3倍的 ,因此。即3×(5+3×2)。如果你把它算出来,实际上得到33就是J的值。 当有不同的或者一些特殊的输出变量时,例如本例中的J和逻辑回归中你想优化的代价函数J,因此计算图用来处理这些计算会很方便。从这个小例子中我们可以看出,通过一个从左向右的过程,你可以计算出J的值。为了计算导数,从右到左(红色箭头,和蓝色箭头的过程相反)的过程是用于计算导数最自然的方式。
概括一下:计算图组织计算的形式是用蓝色箭头从左到右的计算,让我们看看如何进行反向红色箭头(也就是从右到左)的导数计算
计算图的导数计算(Derivatives with a Computation Graph)
在上一个视频中,我们看了一个例子使用流程计算图来计算函数J。现在我们清理一下流程图的描述,看看你如何利用它计算出函数J的导数。
下面用到的公式:
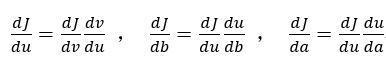
这是一个流程图:
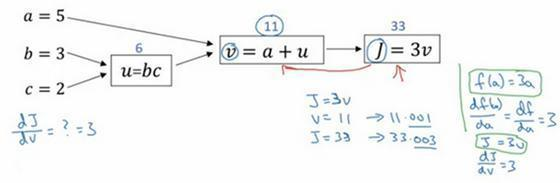
假设你要计算dJ/dv,那要怎么算呢?
好,比如说,我们要把这个v值拿过来,改变一下,那么J的值会怎么变呢?
所以定义上J=3v,现在v=11,所以如果你让v增加一点点,比如到11.001,那么J=3v=33.003,所以我这里v增加了0.001,然后最终结果是J上升到原来的3倍,所以dJ/dv=3,因为对于任何 v 的增量J都会有3倍增量,而且这类似于我们在上一个视频中的例子,我们有f(a)=3a,然后我们推导出(df(a))/da=3,所以这里我们有J=3v,所以dJ/dv=3,这里J扮演了f的角色,在之前的视频里的例子。
在反向传播算法中的术语,我们看到,如果你想计算最后输出变量的导数,使用你最关心的变量对v的导数,那么我们就做完了一步反向传播,在这个流程图中是一个反向步。
我们来看另一个例子,dJ/da是多少呢?换句话说,如果我们提高a的数值,对J的数值有什么影响?
好,我们看看这个例子。变量a=5,我们让它增加到5.001,那么对v的影响就是a+u,之前v=11,现在变成11.001,我们从上面看到现在J就变成33.003了,所以我们看到的是,如果你让a增加0.001,J增加0.003。那么增加a,我是说如果你把这个5换成某个新值,那么a的改变量就会传播到流程图的最右,所以J最后是33.003。所以J的增量是3乘以a的增量,意味着这个导数是3。

要解释这个计算过程,其中一种方式是:如果你改变了a,那么也会改变v,通过改变v,也会改变J,所以J值的净变化量,当你提升这个值(0.001),当你把a值提高一点点,这就是J的变化量(0.003)。
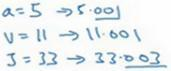
首先a增加了,v也会增加,v增加多少呢?这取决于dv/da,然后v的变化导致J也在增加,所以这在微积分里实际上叫链式法则,如果a影响到v,v影响到J,那么当你让a变大时,J的变化量就是当你改变a时,v的变化量乘以改变v时J的变化量,在微积分里这叫链式法则(其实就是高中学的的复合函数求导)。
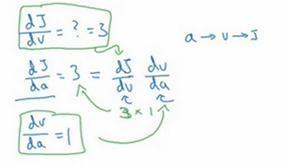
我们从这个计算中看到,如果你让a增加0.001,v也会变化相同的大小,所以dv/da=1。事实上,如果你代入进去,我们之前算过dJ/dv=3,dv/da=1,所以这个乘积3×1,实际上就给出了正确答案,dJ/da=3。
这张小图表示了如何计算,dJ/dv就是J对变量v的导数,它可以帮助你计算dJ/da,所以这是另一步反向传播计算。
现在我想介绍一个新的符号约定,当你编程实现反向传播时,通常会有一个最终输出值是你要关心的,最终的输出变量,你真正想要关心或者说优化的。在这种情况下最终的输出变量是J,就是流程图里最后一个符号,所以有很多计算尝试计算输出变量的导数,所以输出变量对某个变量的导数,我们就用dvar命名,所以在很多计算中你需要计算最终输出结果的导数,在这个例子里是J,还有各种中间变量,比如a、b、c、u、v。
当你在软件里实现的时候,变量名叫什么?
你可以做的一件事是,在python中,你可以写一个很长的变量名,比如dFinalOutputvar_dvar,但这个变量名有点长,我们就用dJ_dvar,但因为你一直对dJ求导,对这个最终输出变量求导。我这里要介绍一个新符号,在程序里,当你编程的时候,在代码里,我们就使用变量名dvar,来表示那个量。

好,所以在程序里是dvar表示导数,你关心的最终变量J的导数,有时最后是L,对代码中各种中间量的导数,所以代码里这个东西,你用dv表示这个值,所以dv=3,你的代码表示就是da=3。
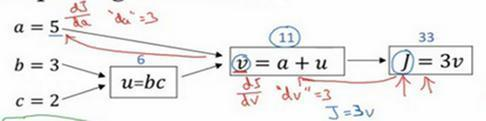
好,所以我们通过这个流程图完成部分的后向传播算法。我们在下一张幻灯片看看这个例子剩下的部分。
我们清理出一张新的流程图,我们回顾一下,到目前为止,我们一直在往回传播,并计算dv=3,再次,dv是代码里的变量名,其真正的定义是dJ/dv。我发现da=3,再次,da是代码里的变量名,其实代表dJ/da的值。
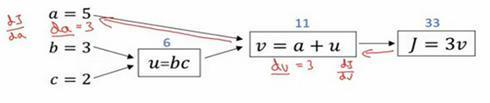
大概手算了一下,两条直线怎么计算反向传播。
好,我们继续计算导数,我们看看这个值u,那么dJ/du是多少呢?通过和之前类似的计算,现在我们从u=6出发,如果你令u增加到6.001,那么v之前是11,现在变成11.001了,J 就从33变成33.003,所以J 增量是3倍,所以dJ/du=3。对u的分析很类似对a的分析,实际上这计算起来就是dJ/dv⋅dv/du,有了这个,我们可以算出dJ/dv=3,dv/du=1,最终算出结果是3×1=3。
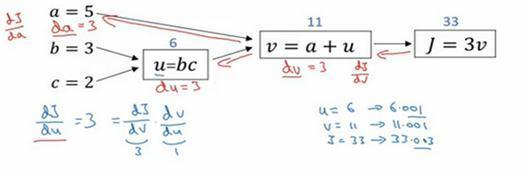
所以我们还有一步反向传播,我们最终计算出du=3,这里的du当然了,就是dJ/du。
现在,我们仔细看看最后一个例子,那么dJ/db呢?想象一下,如果你改变了b的值,你想要然后变化一点,让J值到达最大或最小,那么导数是什么呢?这个J函数的斜率,当你稍微改变b值之后。事实上,使用微积分链式法则,这可以写成两者的乘积,就是dJ/du⋅du/db,理由是,如果你改变b一点点,所以b变化比如说3.001,它影响J的方式是,首先会影响u,它对u的影响有多大?好,u的定义是b⋅c,所以b=3时这是6,现在就变成6.002了,对吧,因为在我们的例子中c=2,所以这告诉我们du/db=2当你让b增加0.001时,u就增加两倍。所以du/db=2,现在我想u的增加量已经是b的两倍,那么dJ/du是多少呢?我们已经弄清楚了,这等于3,所以让这两部分相乘,我们发现dJ/db=6。
好,这就是第二部分的推导,其中我们想知道 u 增加0.002,会对J有什么影响。实际上dJ/du=3,这告诉我们u增加0.002之后,J上升了3倍,那么J应该上升0.006,对吧。这可以从dJ/du=3推导出来。
如果你仔细看看这些数学内容,你会发现,如果b变成3.001,那么u就变成6.002,v变成11.002,然后J=3v=33.006,对吧?这就是如何得到dJ/db=6。
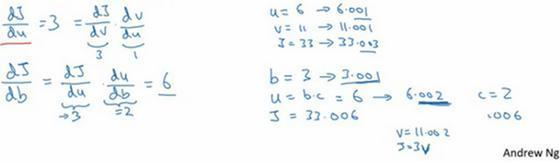
为了填进去,如果我们反向走的话,db=6,而db其实是Python代码中的变量名,表示dJ/db。

我不会很详细地介绍最后一个例子,但事实上,如果你计算dJ/dc=dJ/du⋅du/dc=3×3,这个结果是9。
我不会详细说明这个例子,在最后一步,我们可以推出dc=9。
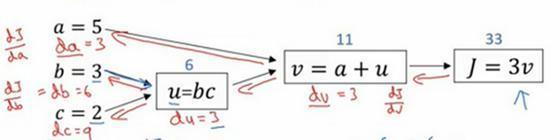
所以这个知识的要点是,对于那个例子,当计算所有这些导数时,最有效率的办法是从右到左计算,跟着这个红色箭头走。特别是当我们第一次计算对v的导数时,之后在计算对a导数就可以用到。然后对u的导数,比如说这个项和这里这个项:
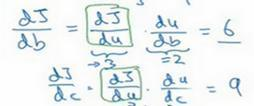
可以帮助计算对b的导数,然后对c的导数。
知乎上一位大佬实现的框架化反向传播
看了代码会更好理解
反向传播就是梯度下降中的求导环节,它重复利用计算过的导数而已。
import random
class Layer(object):
'''
本文中,一层只有一个神经元,一个神经元只有一个输入一个输出
'''
def __init__(self,layer_index):
'''
layer_index: 第几层
'''
self.layer_index = layer_index
# 初始化权重[0,1] - 0.5 = [-0.5,0.5]保证初始化有正有负
self.w = random.random() - 0.5
# 当前层的输出
self.output = 0
def forward(self,input_var):
'''
前向传播:对输入进行运算,并将结果保存
input_var: 当前层的输入
'''
self.input = input_var
self.output = self.w * self.input
def backward(self, public_value):
'''
反向传播:计算上层也会使用的导数值并保存
假设当前层的计算规则是这样output = f(input),
而 input == 前一层的输出,
因此,根据链式法则损失函数对上一层权重的导数 = 后面层传过来的公共导数* f'(input) * 前一层的导数
也就是说,后面层传过来的公共导数值* f'(input) 是需要往前传的公用的导数值。
由于本层中对输入做的运算为:output = f(input) = w*input
所以, f'(input) = w.
public_value: 后面传过来的公共导数值
'''
# 当前层要传给前面层的公共导数值 = 后面传过来的公共导数值 * f'(input)
self.public_value = public_value * self.w
# 损失函数对当前层参数w的导数 = 后面传过来的公共导数值 * f'(input) * doutput/dw
self.w_grad = self.public_value * self.input
def upate(self, learning_rate):
'''
利用梯度下降更新参数w
参数迭代更新规则(梯度下降): w = w - 学习率*损失函数对w的导数
learning_rate: 学习率
'''
self.w = self.w - learning_rate * self.w_grad
def display(self):
print('layer',self.layer_index,'w:',self.w)
class Network(object):
def __init__(self,layers_num):
'''
构造网络
layers_num: 网络层数
'''
self.layers = []
# 向网络添加层
for i in range(layers_num):
self.layers.append(Layer(i+1))#层编号从1开始
def predict(self, sample):
'''
sample: 样本输入
return 最后一层的输出
'''
output = sample
for layer in self.layers:
layer.forward(output)
output = layer.output
return 1 if output>0 else -1
def calc_gradient(self, label):
'''
从后往前计算损失函数对各层的导数
'''
# 计算最后一层的导数
last_layer = self.layers[-1]
# 由于损失函数=0.5*(last_layer.output - label)^2
# 由于backward中的public_value = 输出对输入的导数
# 对于损失函数其输入是last_layer.output,损失函数对该输入的导数=last_layer.output - label
# 所以 最后一层的backward的public_value = last_layer.output - label
last_layer.backward(last_layer.output - label)
public_value = last_layer.public_value
for layer in self.layers:
layer.backward(public_value) # 计算损失函数对该层参数的导数
public_value= layer.public_value
def update_weights(self, learning_rate):
'''
更新各层权重
'''
for layer in self.layers:
layer.upate(learning_rate)
def train_one_sample(self, label, sample, learning_rate):
self.predict(sample) # 前向传播,使得各层的输入都有值
self.calc_gradient(label) # 计算各层导数
self.update_weights(learning_rate) # 更新各层参数
def train(self, labels, data_set, learning_rate, epoch):
'''
训练神经网络
labels: 样本标签
data_set: 输入样本们
learning_rate: 学习率
epoch: 同样的样本反复训练的次数
'''
for _ in range(epoch):# 同样数据反复训练epoch次保证权重收敛
for i in range(len(labels)):#逐样本更新权重
self.train_one_sample(labels[i], data_set[i], learning_rate)
nn = Network(3)
data_set = [1,-1]
labels = [-1,1]
learning_rate = 0.05
epoch = 160
nn.train(labels,data_set,learning_rate,epoch)
print(nn.predict(1)) # 输出 -1
print(nn.predict(-1)) # 输出 1
















 327
327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











