




 本文介绍了贝叶斯统计的核心概念,包括先验概率、后验概率、似然度和边际概率,以及它们在实际问题中的应用,如垃圾邮件过滤。通过贝叶斯定理,可以更新我们对事件的认知,做出更准确的预测和决策。此外,还讨论了贝叶斯学习和最大后验概率假设在模型选择中的作用。
本文介绍了贝叶斯统计的核心概念,包括先验概率、后验概率、似然度和边际概率,以及它们在实际问题中的应用,如垃圾邮件过滤。通过贝叶斯定理,可以更新我们对事件的认知,做出更准确的预测和决策。此外,还讨论了贝叶斯学习和最大后验概率假设在模型选择中的作用。
Bayesian Learning
前言
本文将基于UoA的课件介绍机器学习中的贝叶斯。
涉及的英语比较基础,所以为节省时间(不是full-time,还有其他三门课程,所以时间还是比较紧的),只在我以为需要解释的地方进行解释。
此文不用于任何商业用途,仅仅是个人学习过程笔记以及心得体会,侵必删。
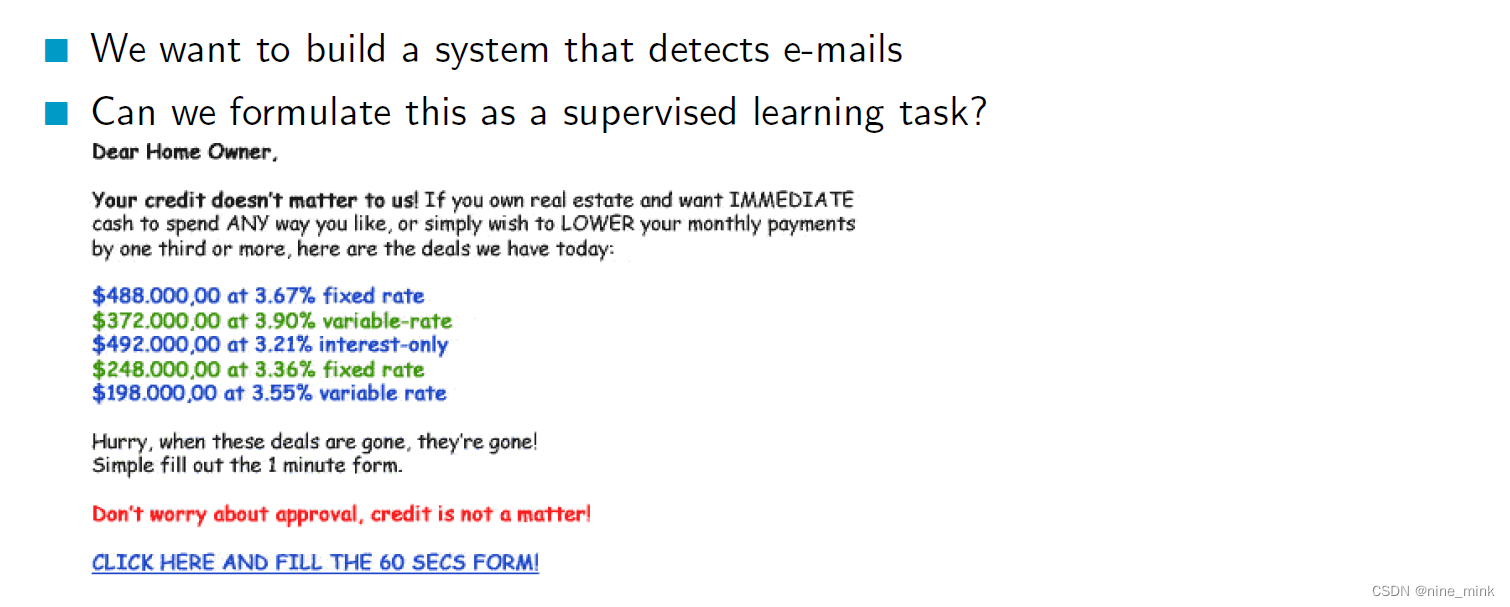
Motivation and Introduction
Think about Spam Filtering.
Lead in, 比较简单,不多说了。




 P ( Y ) P(Y) P(Y)是事件Y的先验概率,即在考虑观测数据之前我们对事件Y发生的概率的估计。 P ( X ∣ Y ) P(X|Y) P(X∣Y)是在事件Y发生的条件下观测到数据X的概率,称为事件Y的似然度。 P ( X ) P(X) P(X)是数据X发生的边际概率,也称为证据。
P ( Y ) P(Y) P(Y)是事件Y的先验概率,即在考虑观测数据之前我们对事件Y发生的概率的估计。 P ( X ∣ Y ) P(X|Y) P(X∣Y)是在事件Y发生的条件下观测到数据X的概率,称为事件Y的似然度。 P ( X ) P(X) P(X)是数据X发生的边际概率,也称为证据。
贝叶斯公式的含义可以用以下步骤概括:
-
先根据我们的先验知识( P ( Y ) P(Y) P(Y))对事件Y的发生概率进行估计。
-
观测到数据X之后,根据我们对数据的了解,计算出在事件Y发生的条件下,数据X出现的概率( P ( X ∣ Y ) P(X|Y) P(X∣Y))。
-
通过计算边缘概率 P ( X ) P(X) P(X),将 P ( Y ) P(Y) P(Y)和 P ( X ∣ Y ) P(X|Y) P(X∣Y)结合起来,计算出事件A在观测到数据B之后的后验概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)。
-
根据计算出的后验概率 P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











