






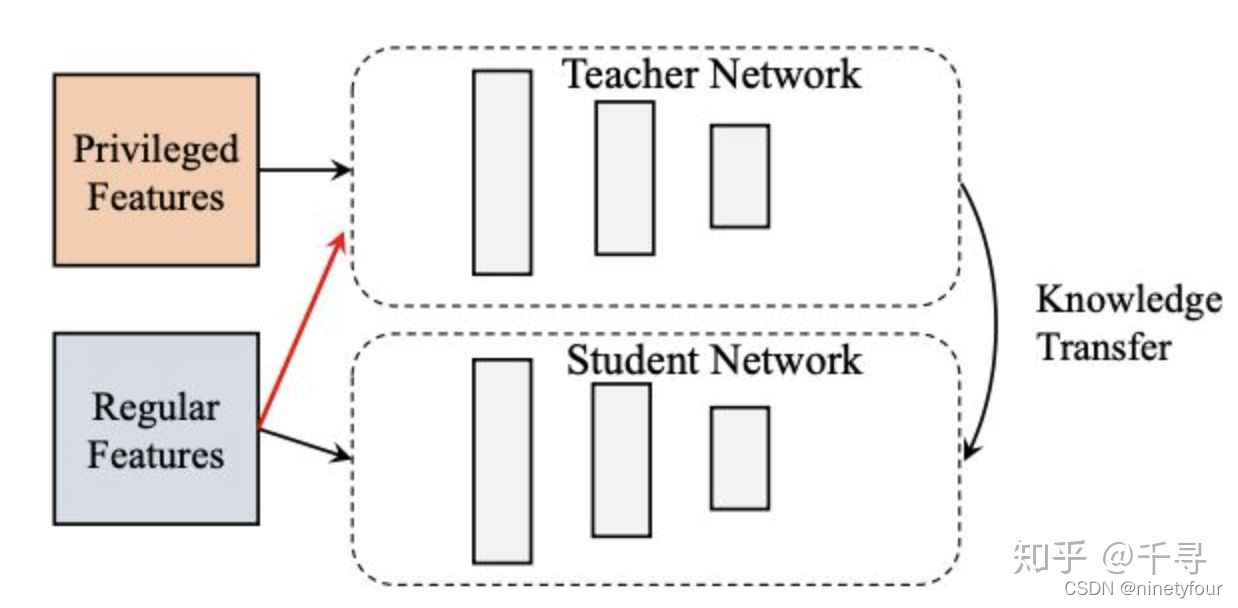
先说下什么是蒸馏,顾名思义,白酒蒸馏出来就是高度酒,水蒸馏出来就是蒸馏水(纯净),所以算法领域的蒸馏技术就是要把大的模型,大的知识,进行提纯,以达到小容量便可以解决大问题的效果。一般是压缩模型规模,后续演化也可以通过teacher&student方式提升算法准确度。
未完待续
class Distiller(keras.Model):
def __init__(self, student, teacher):
super().__init__()
self.teacher = teacher
self.student = student
def compile(
self,
optimizer,
metrics,
student_loss_fn,
distillation_loss_fn,
alpha=0.1,
temperature=3,
):
""" Configure the distiller.
Args:
optimizer: Keras optimizer for the student weights
metrics: Keras metrics for evaluation
student_loss_fn: Loss function of difference between student
predictions and ground-truth
distillation_loss_fn: Loss function of difference between soft
student predictions and soft teacher predictions
alpha: weight to student_loss_fn and 1-alpha to distillation_loss_fn
temperature: Temperature for softening probability distributions.
Larger temperature gives softer distributions.
"""
super().compile(optimizer=optimizer, metrics=metrics)
self.student_loss_fn = student_loss_fn
self.distillation_loss_fn = distillation_loss_fn
self.alpha = alpha
self.temperature = temperature
def train_step(self, data):
# Unpack data
x, y = data
# Forward pass of teacher
teacher_predictions = self.teacher(x, training=False)
with tf.GradientTape() as tape:
# Forward pass of student
student_predictions = self.student(x, training=True)
# Compute losses
student_loss = self.student_loss_fn(y, student_predictions)
# Compute scaled distillation loss from https://arxiv.org/abs/1503.02531
# The magnitudes of the gradients produced by the soft targets scale
# as 1/T^2, multiply them by T^2 when using both hard and soft targets.
distillation_loss = (
self.distillation_loss_fn(
tf.nn.softmax(teacher_predictions / self.temperature, axis=1),
tf.nn.softmax(student_predictions / self.temperature, axis=1),
)
* self.temperature**2
)
loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss
# Compute gradients
trainable_vars = self.student.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update the metrics configured in `compile()`.
self.compiled_metrics.update_state(y, student_predictions)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update(
{"student_loss": student_loss, "distillation_loss": distillation_loss}
)
return results
def test_step(self, data):
# Unpack the data
x, y = data
# Compute predictions
y_prediction = self.student(x, training=False)
# Calculate the loss
student_loss = self.student_loss_fn(y, y_prediction)
# Update the metrics.
self.compiled_metrics.update_state(y, y_prediction)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update({"student_loss": student_loss})
return results
实现代码从官方文档copyKnowledge Distillation


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









