







文章目录
一、闭包
1、问题
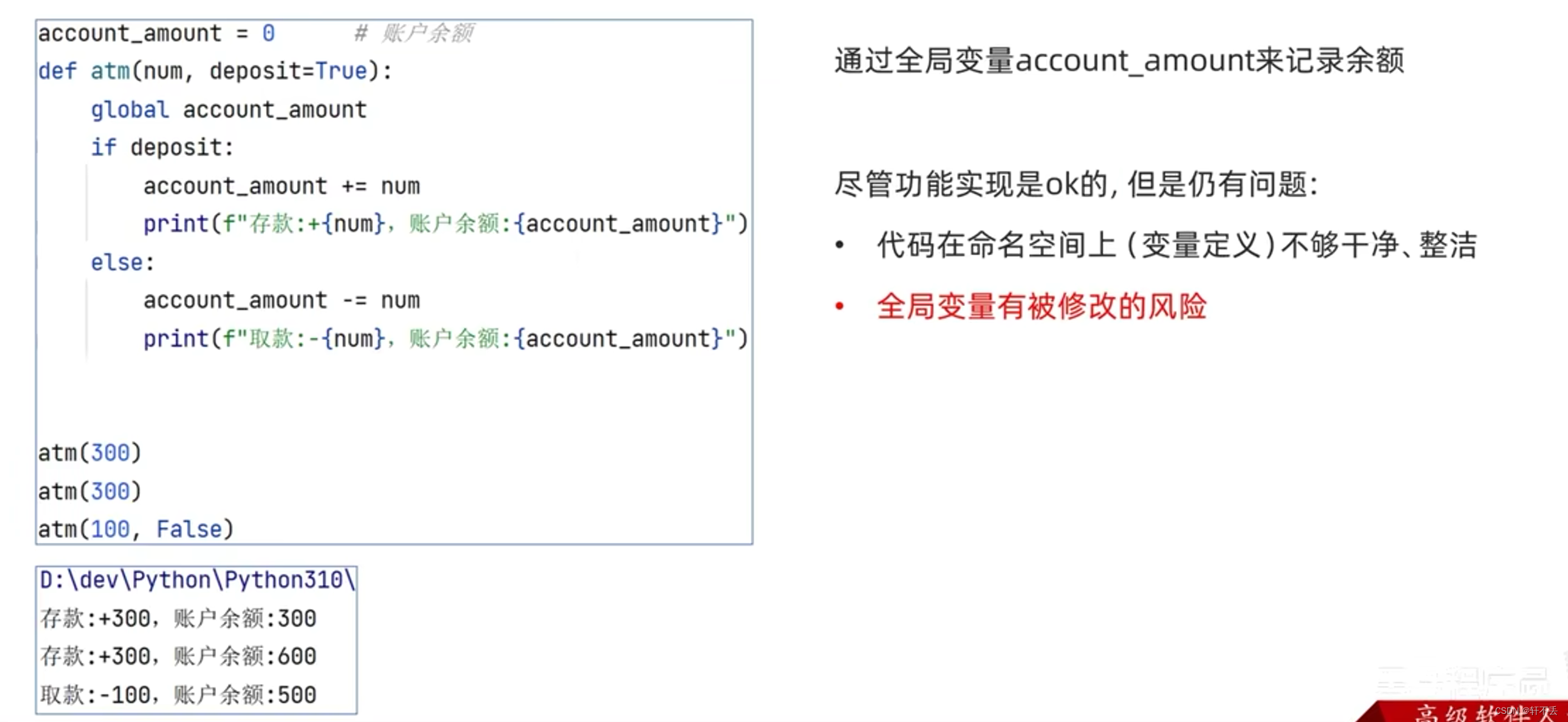
2、实现
需要使用nonlocal关键字修饰外部函数的变量才可在内部函数中修改它

3、装饰器
装饰器其实也是一种闭包,其功能就是在不破坏目标函数原有的代码和功能的前提下,为目标函数增加新功能。
- 写法1

- 语法糖写法

二、设计模式
1、概念
- 设计模式是一种编程套路,可以极大的方便程序的开发。
- 最常见、最经典的设计模式,就是我们所学习的面向对象了。
- 除了面向对象外,在编程中也有很多既定的套路可以方便开发,我们称之为设计模式:
- 单例、工厂模式
- 建造者、责任链、状态、备忘录、解释器、访问者、观察者、中介、模板、代理模式
2、单例模式
- 定义:保证一个类只有一个具体的实例,并提供一个访问它的全局访问点


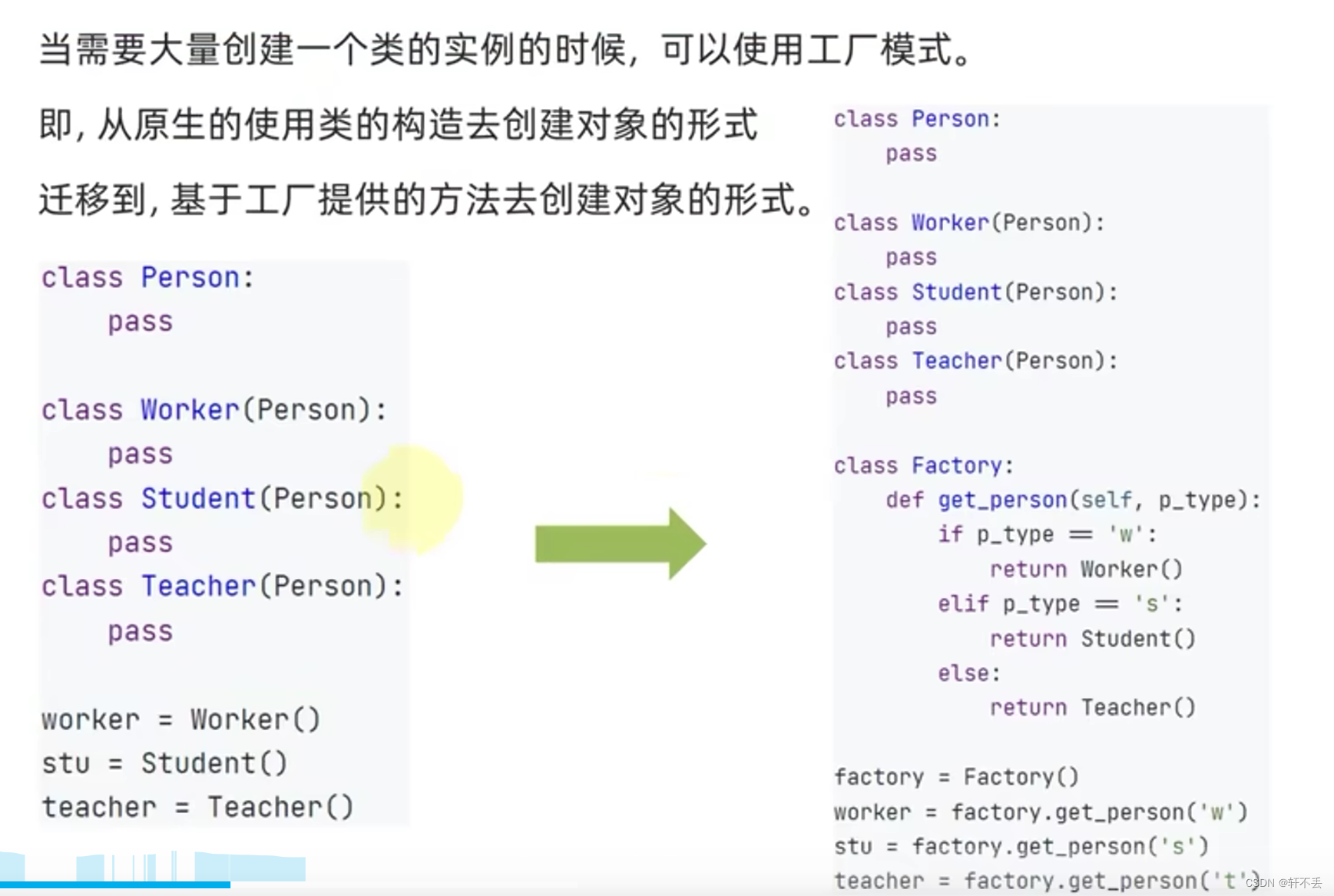
3、工厂模式
- 当需要大量创建一个类的实例的时候,可以使用工厂模式。
- 即,从原生的使用类的构造去创建对象的形式迁移到,基于工厂提供的方法去创建对象的形式。
三、多线程
- 绝大多数编程语言,都允许多线程编程,Pyhton也不例外。
- Python的多线程可以通过threading模块来实现。
import threading
thread_obj = threading.Thread([group,target [,name [,args [, kwargs]]]]])
-group:暂时无用,未来功能的预留参数
-target:执行的目标任务名
-args:以元组的方式给执行任务传参
-kwarqs:以字典方式给执行任务传参
-name:线程名,一般不用设置
#启动线程,让线程开始工作
thread_obj.start()


四、网络变成
1、socket
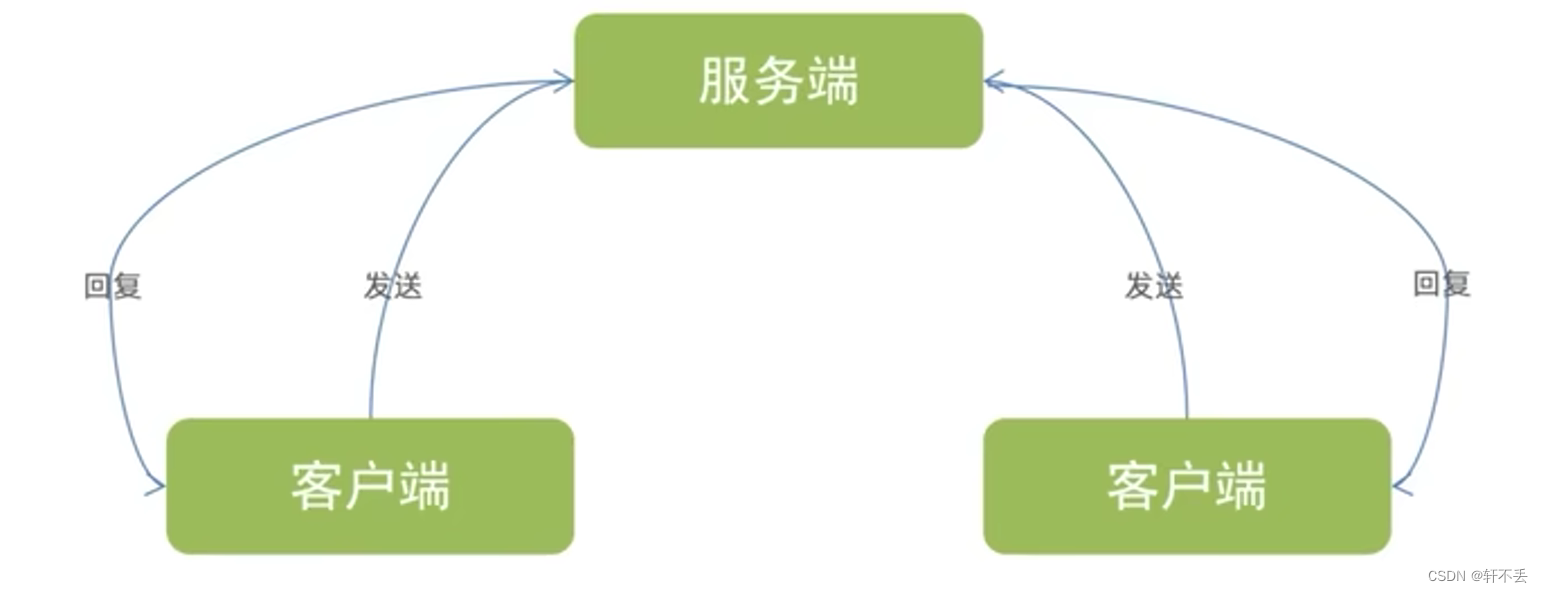
- socket(简称 套接字)是进程之间通信一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行进程之间想要进行网络通信需要socket
- Socket负责进程之间的网络数据传输,好比数据的搬运工

- 2个进程之间通过Socket进行相互通讯就必须有服务端和客户端
- Socket服务端:等待其它进程的连接、可接受发来的消息、可以回复消息
- Socket客户端:主动连接服务端、可以发送消息、可以接收回复
2、服务端编程
1.创建socket对象
import socket
socket_server = socket.socket() //未确定是服务端还是客户端
2.绑定socket_server到指定IP和地址
socket_server.bind(host,port) //绑定bind确定是服务端
3.服务端开始监听端口
socket_server.listen(backlog)
# backlog为int整数,表示允许的连接数量,超出的会等待,可以不填,不填会自动设置一个合理值
4.接收客户端连接,获得连接对象
conn,address=socket_server.accept()
print(f"接收到客户端连接,连接来自:{address}")
#accept方法是阻塞方法,如果没有连接,会卡再当前这一行不向下执行代码
#accept返回的是一个二元元组,可以使用上述形式,用两个变量接收二元元组的2个元素
5.客户端连接后,通过recv方法,接收客户端发送的消息
while True:
data = conn.recv(1024).decode("UTF-8")
#recv方法的返回值是字节数组(Bytes),可以通过decode使用UTF-8解码为字符串
#recv方法的传参是buffsize,缓冲区大小,一般设置为1024即可
if data == 'exit':
break
print("接收到发送来的数据:",data)
#可以通过while True无限循环来持续和客户端进行数据交互
#可以通过判定客户端发来的特殊标记,如exit,来退出无限循环
6.通过conn(客户端当次连接对象)调用send方法可以回复消息
while True:
data = conn.recv(1024).decode("uTF-8")
if data == 'exit':
break
print("接收到发送来的数据:",data)
conn.send("你好".encode("UTF-8"))
7.conn(客户端当次连接对象)和socket server对象调用close方法,关闭连接
conn.close()
socket_server.close()
3、客户端开发
1.创建socket对象
import socket
socket_client = socket.socket()
2.连接到服务端
socket_server.connnect(host,port) //绑定connect确定是服务端
3.发送/接收消息
while True:
send_msg = input()
if data == 'exit':
break
socket_client.send(send_msg.encode("utf-8"))
recv = socket_client.recv(1024)
#recv是阻塞式的,即不接收就返回,卡在这里等待
4.关闭链接
socket_client.close()
五、正则表达式
1、方法
- Python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配。
- 分别是: match、search、findall 三个基础方法
- re.match(匹配规则,被匹配字符串)
- 从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空
s ='python itheima python itheima python itheima'
result =re.match('python',s)
print(result) #<re.Match object;span=(0,6),match='python'>
print(result.span()) #(0,6)
print(result.group()) #python
s ='1python itheima python itheima python itheima'
result = re.match('python',s)
print(result) #None
- search(匹配规则,被匹配字符串)
- 搜索整个字符串,找出匹配的。从前向后,找到第一个后,就停止,不会继续向后
s ='1python666itheima666python666'
result = re.search('python',s)
print(result) #<re.Match object;span=(1,7),match='python'>
print(result.span()) #(1,7)
print(result.group()) #python
s ='itheima666'
result =re.search('python',s)
print(result)# None
- findall(匹配规则,被匹配字符串)
- 匹配整个字符串,找出全部匹配项
s =1python666itheima666python666'
result = re.findall('python',s)
print(result) #['python','python']
s=1python666itheima666python666'
result =re.findall('itcast's)
print(result) #[ ]
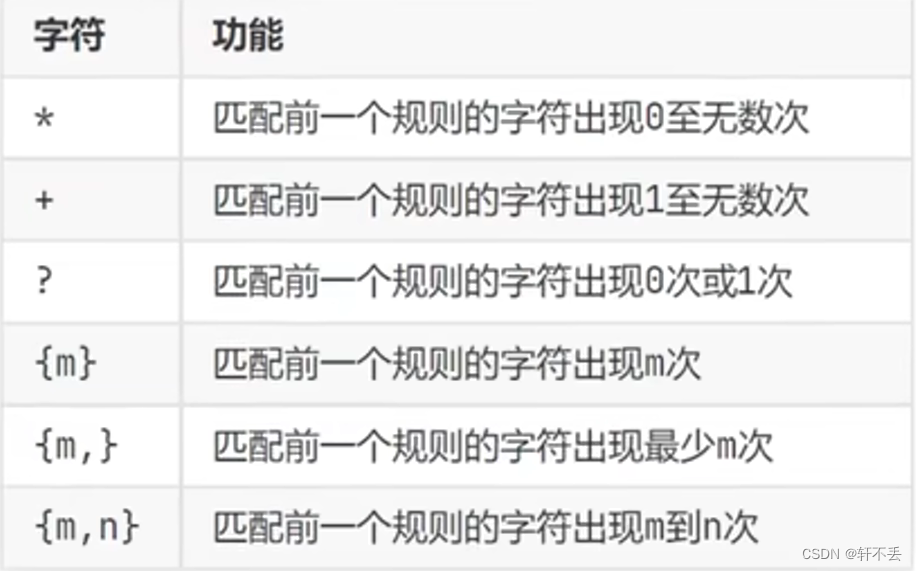
2、元字符匹配
-
单字符匹配

-
数量匹配
{}里面一定不能有空格
-
边界匹配

-
分组匹配

六、PySpark
1、Spark
- 定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎

- 简单来说,Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据

- Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。
- 而Python语言,则是Spark重点支持的方向。
2、Pyspark
- Spark对Python语言的支持,重点体现在,Python第三方库:PySpark之上
- PySpark是由Spark官方开发的Python语言第三方库
- Python开发者可以使用pip程序快速的安装PySpark并像其它三方库那样直接使用

3、Pyspark使用
1.安装
pip install Pyspark
- 想要使用PySpark库完成数据处理,首先需要构建一个执行环境入口对象。
- PySpark的执行环境入口对象是:类Sparkcontext的类对象
# 导包
from pyspark import Sparkconf, sparkcontext
# 创建sparkconf类对象
conf = Sparkconf().setMaster("local[*]").setAppName("test_spark_app")
# 基于Sparkconf类对象创建Sparkcontext类对象
sc =Sparkcontext(conf=conf)
#打印PySpark的运行版本
print(sc.version)
# 停止sparkcontext对象的运行(停止PySpark程序)
sc.stop()
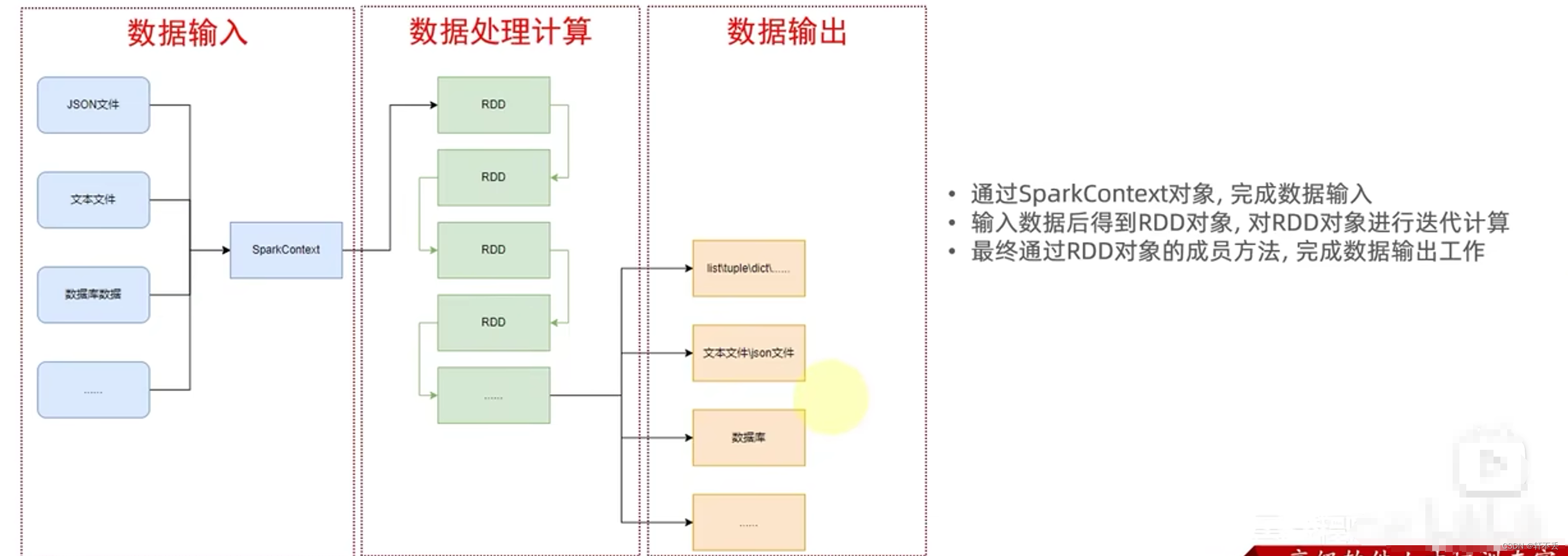
编程模型
- SparkContext类对象,是PySpark编程中一切功能的入口。
- PySpark的编程,主要分为如下三大步骤















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









