






MySQL表的增删查改(三)
文章目录
1.新增
将select查询出来的结果数据插入到另一个表中
新建两张表student1 student2
create table student (id int, name varchar(20));
create table student2 (id int,name varchar(20));
insert into stduent values (1,'小明'),(2,'小红'),(3,'小黄');

将student中的数据加入student2
insert into student2 select * from student;

此处的select查询的结果,得和插入的表能对应上(列的数目,类型,约束)
2. 查询
2.1 聚合查询
查询的时候带表达式,本质上是用列和列之间进行运算
还有时候需要进行行和行之间的运算.
常见的统计总数,计算平均值等操作,可以使用聚合函数来实现,常见的聚合函数有:
| 函数 | 说明 |
|---|---|
| count([distinct] expr) | 返回查询到的数据的数量 |
| sum([distinct] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| avg([distinct] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| max([distinct] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| min([distinct] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
示例:
count
创建一个exam_result表
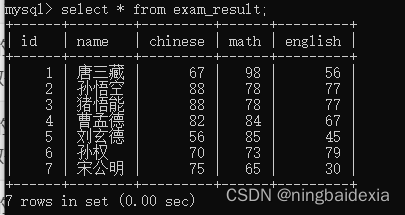
统计有多少行数据
select count(*) from exam_result;

统计有多少个同学
select count(name) from exam_result;
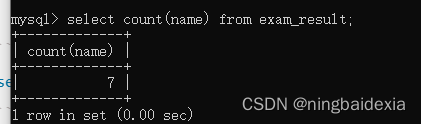
注意:
若是name为空的话就不会被统计到
我们插入一个null值再统计还是7
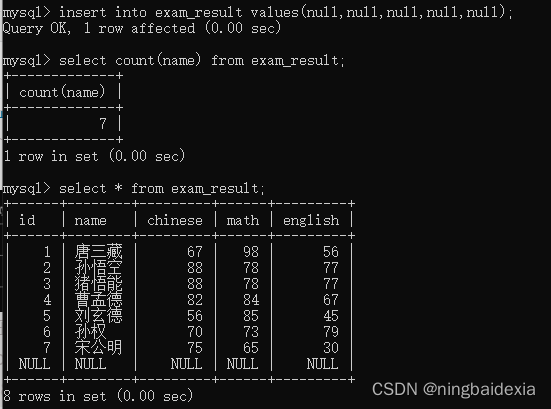
注意:
再sql中要求聚合函数和()必须是紧紧挨在一起

示例:
sum
将一列的数据相加
select sum(chinese) from exam_result;
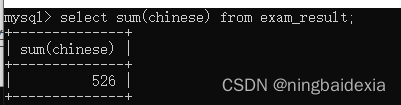
sun进行求和,会把这一列的若干行,按照double的方式进行累加.(会把这一列的数据先转成double)
当我们将一个数据类型为字符型相加时会有
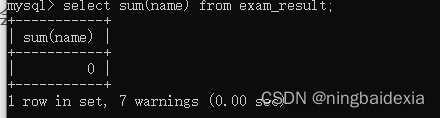
尝试把每一行的数据都转为double但是转失败,并没有直接中断求和操作,跳过,继续下一行,同时记录一个warning
show warnings 查看当前的警告
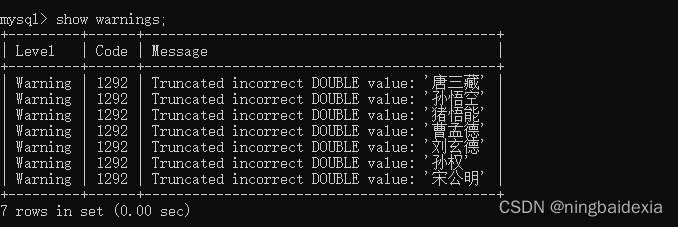
示例:
avg
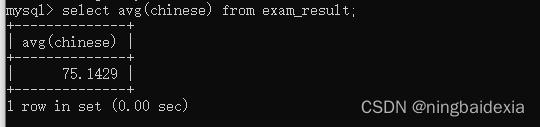
求语文的平均分
select avg(chinese) from exam_result;
求总分平均值
select avg(chinese + math + english) from exam_result;

示例:
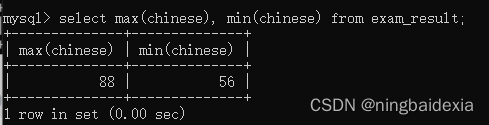
最大最小值
select max(chinese), min(chinese) from exam_result;
2.2 分组查询 GROUP BY子句
指定一个列,按照这一列进行分组,这一列中,数值相同的行会被分到一组
创建一个emp表
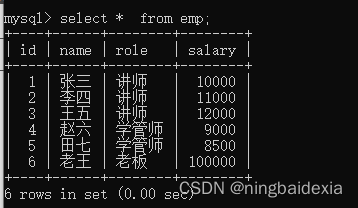
示例:
查询每个岗位的平均薪资
此处可以通过role进行分组
select role, avg(salary) from emp group by role;
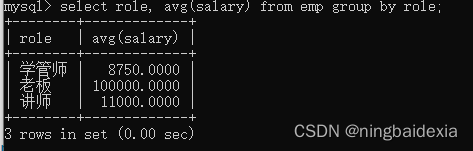
注意:
在分组查询中,select 中指定的列,必须是当前gruop by指定的列
如果select 中想用到其他的列,其他列必须放到聚合函数中,否则,直接写此时的查询结果无意义!

role其实只有三种情况但是name则有6个
此时name并没有意义
分组查询,也可以搭配条件使用
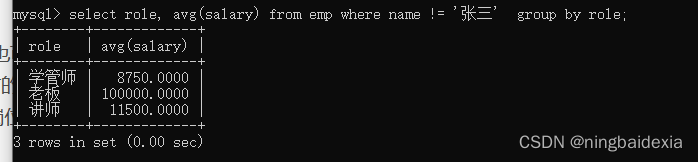
1.分组之前的条件where
求每一个岗位的平均工资,但是除去张三
select role, avg(salary) from emp where name != '张三' group by role;
2. 分组之后的条件having
求每个岗位的平均薪资,但是出去平均值薪资超过2w的
select role, avg(salary) from emp group by role having avg(salary) < 20000;

两者结合
select role, avg(salary) from emp where name != '张三' group by role having avg(salary) <20000;

注意:
where写在group by 前面
having写再group by 后面
2.3 联合查询
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积
2.3.1笛卡尔积:

笛卡尔积的列数是原来两个表的列数之和
笛卡尔积的行数是原来两个表的行数之积
针对任意两张表都可以计算笛卡尔积,但是一般来说,两个表没有
任何关系,计算的结果也是无意义的
示例:
创建四个表
create table classes(id int primary key auto_increment, name varchar(20),`desc` varchar(100));
create table student(id int primary key auto_increment, sn varchar(20), name varchar(20),qq_mail varchar(20), classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3,1), student_id int, course_id int);
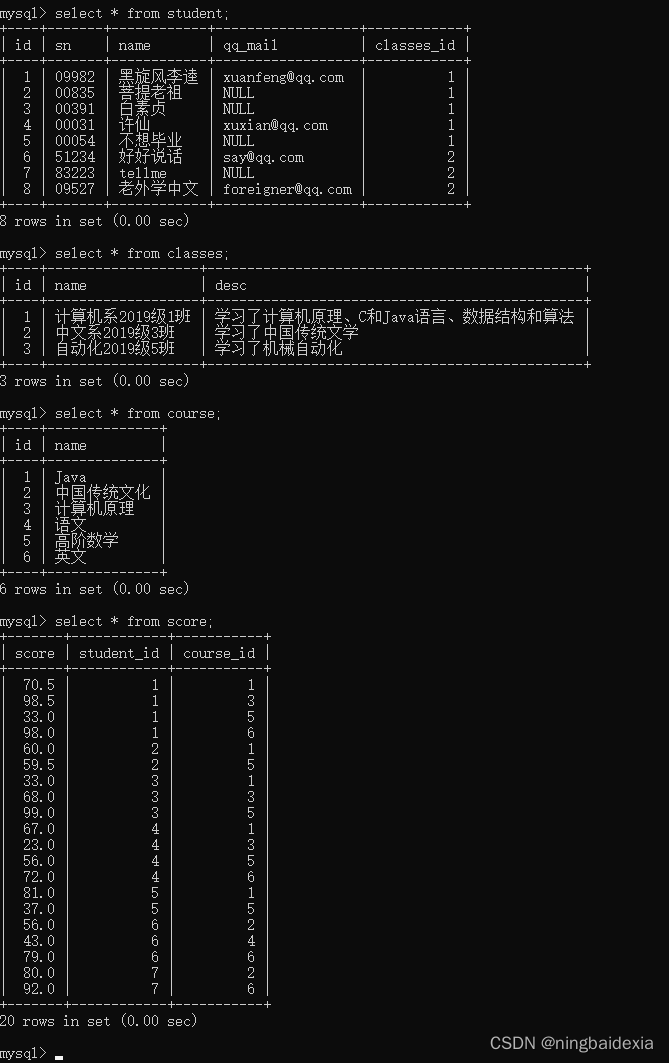
学生 班级 课程
学生和班级: 一对多
学生和课程: 多对多
分数表,就相当于学生和课程之间的关联表
使用学生表和班级表进行笛卡尔积
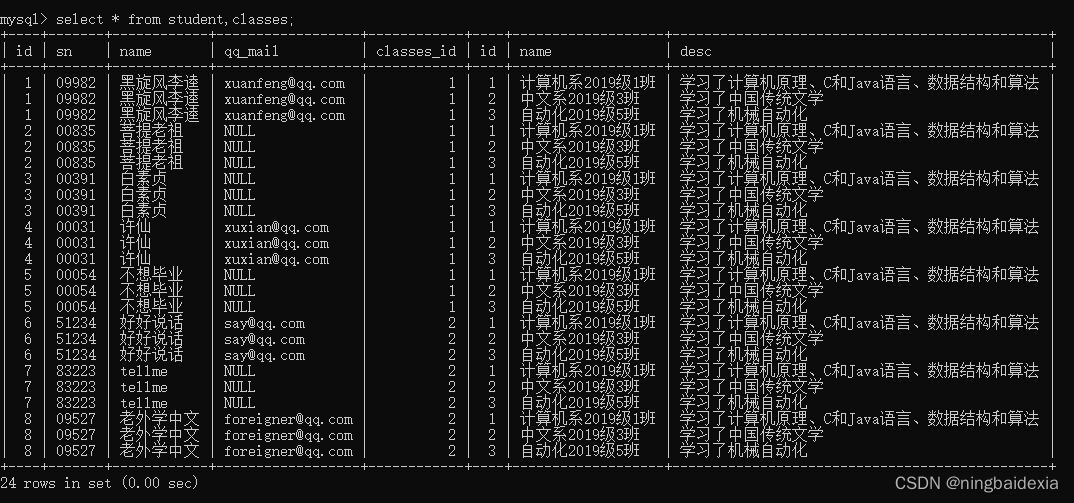
其中大部分都是无效数据例如班级id对应不上
所以我们需要筛选数据
select * from student,classes where student.classes_id = classes.id;
注意:
如果是单个表进行查询,条件中直接写列名即可.
如果是多个表进行查询,条件中最好要写作"表名.列名"的形式
因为进行联合查询的这两个表里,有些列名可能是一样的
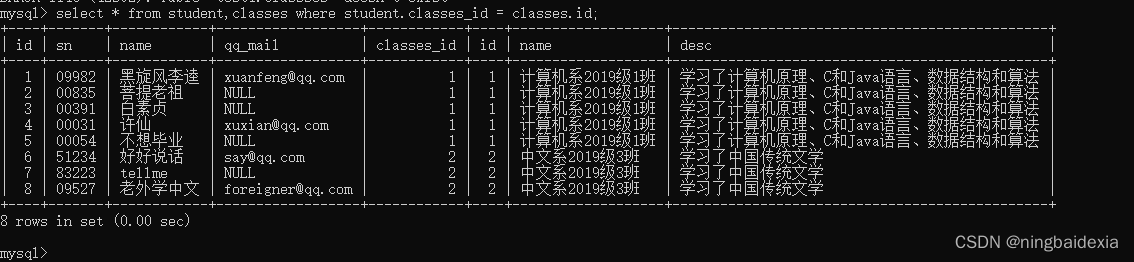
笛卡尔积 + 必要条件 = 多表联合查询
示例:
查询"许仙"同学的成绩
许仙来自student表
成绩来自score表
- 先把student 和 score 笛卡尔积
select * from student, score;
得到一个很大的数据集,大部分都是无意义的,有160条记录

2. 指定连接条件,此处按照学生id来筛选
select * from student, score where student.id = score.student_id;
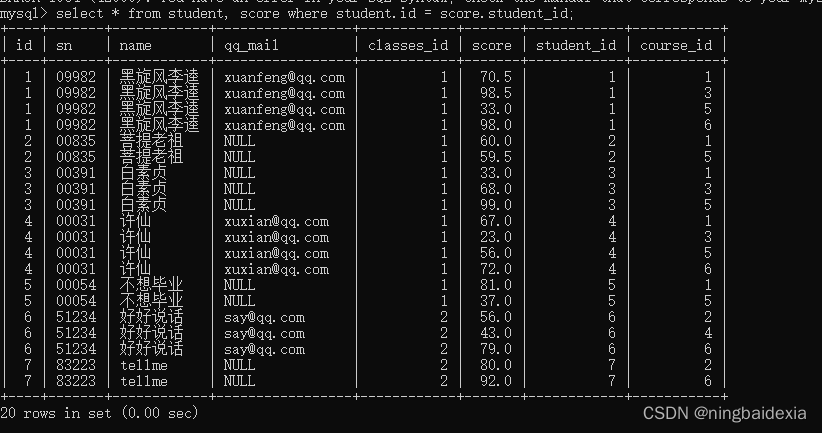
3. 根据需求,进一步的添加条件,此处按照名字为许仙在来筛选

4. 针对查询的结果的列,进行精简
select student.name, score.score from student, score where student.id = score.student_id and student.name = '许仙';
编写一个多表查询的基本的步骤
示例:
查询全部同学的总成绩,及同学的个人信息
- 指定连接条件,此处按照学生id来筛选
select * from student, score where student.id = score.student_id;
- 要求每个同学的总成绩,就需要按照学生维度进行group by
select * from student, score where student.id = score.student_id group by student.name;

此处的score 和 course_id 并不是有意义的
- 加上聚合函数把列进行精准
select name, sum(score.score) from student, score where student.id = score.student_id group by student.name;

同理,看看每个同学选了几门课
select name, count(score.score) from student,score where student.id = score.student_id group by student.name;

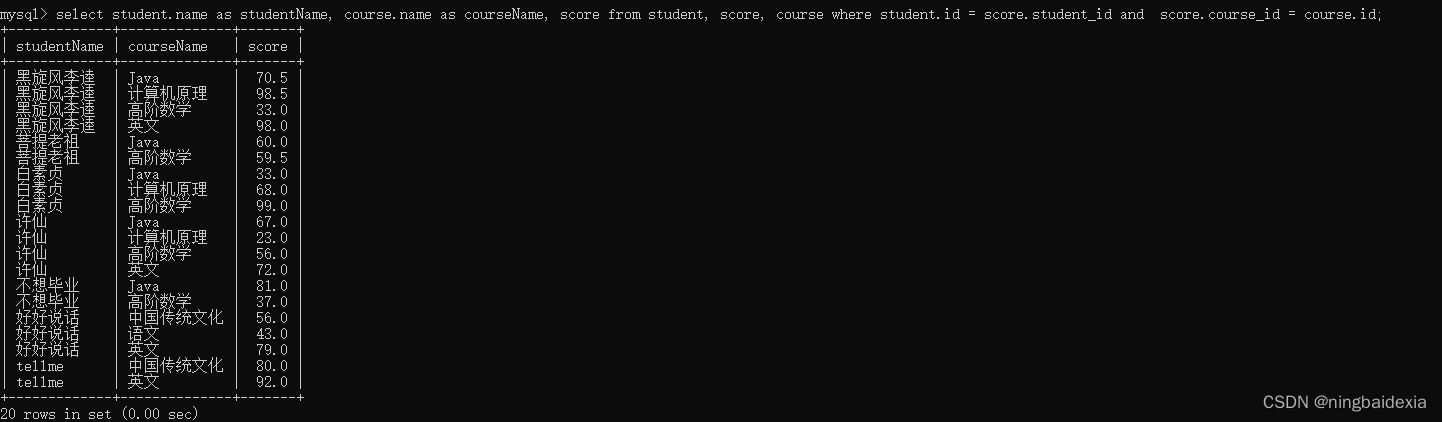
查询所有同学的名字 及其个人信息
列出同学的名字 课程名字 分数
- 三张表进行笛卡尔积
select * from student, score, course

2. 指定连接条件筛选合理的数据
select student.name as studentName, course.name as courseName, score from student, score, course where student.id = score.student_id and score.course_id = course.id;
2.3.2 内连接
同样查询 许仙的成绩
前面多个表使用 逗号 来分割,现在使用join来分割
前面连接条件通过where指定现在使用on来指定
内连接产生的结果 一定是两个表中都存在的数据(公共的部分)
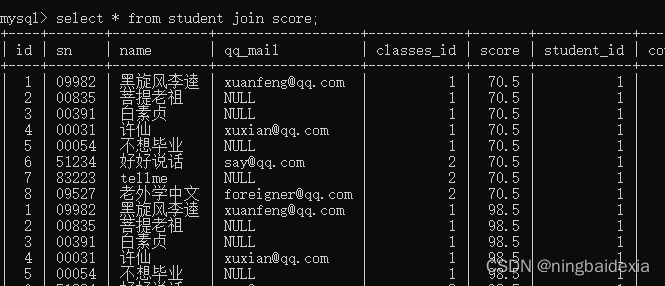
- 只写join 没有on,则是完整的笛卡尔积
select * from student join score;
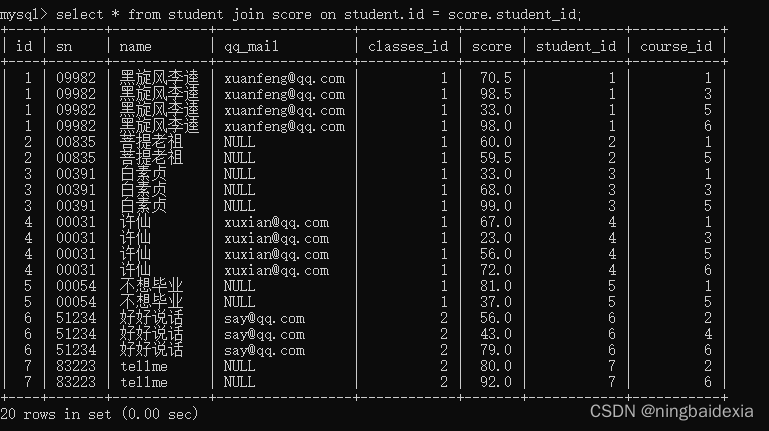
- 使用on作为连接条件
select * from student join score on student.id = score.student_id;
3. 结合需求,加上其他的条件
select * from student join score on student.id = score.student_id and student.name = '许仙';

4. 针对列进行精简
select student.name, score.score from student join score on student.id = score.student_id and student.name = '许仙';

2.3.3 外连接
外连接 在mysql里有两种情况左外连接 和 右外连接
left join / right join
左外连接,就是以左侧的表为主,左侧表的每个记录 都会存在于结果 如果遇到了左侧表中存在 右侧表中不存在的数据 此时就会把对应的列填成空值
示例:
创建两张表 student score
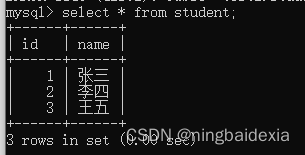

select * from student left join score on student.id = score.id;
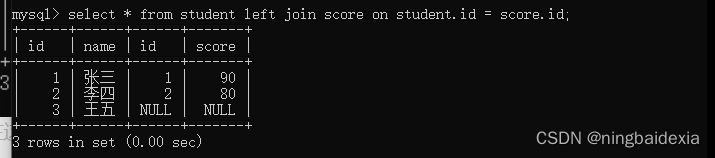
select * from student right join score on student.id = score.id;
2.3.4全外连接 .outer join
mysql不支持
2.3.5 自连接
自连接是指在同一张表连接自身进行查询
示例:
显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
1.先将score表自连接 由于sql语句不能有两个表名相同 可以将score表另命名为s1,s2
select * from score as s1, score as s2;
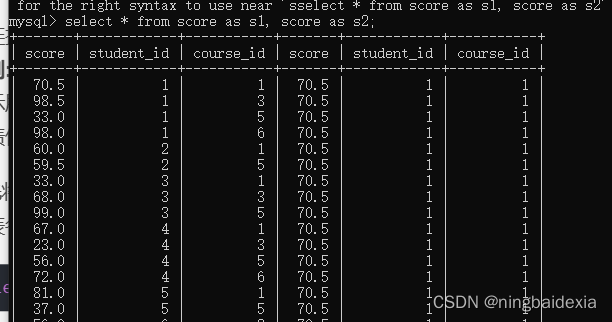
这样我们就将行与行之间的比较转化为列与列之间的比较
- 以学生的id作为连接条件
select * from score as s1, score as s2 where s1.student_id = s2.student_id;
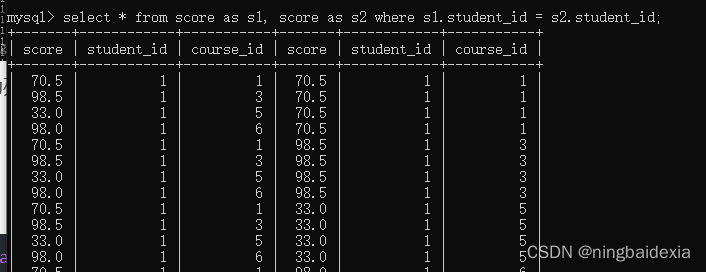
3. 由课程表可知

筛选出course_id = 3 和 1的条件并s1.score > s2.score
select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;

4. 最后对列进行精简 还可以和student进行连接显示学生名字
不过并不推荐多个表进行笛卡尔积(会大大降低查询效率)

2.4 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
本质上就是把多个sql合并成一个sql
示例:
查询"不想毕业"的同班同学
正常分两步完成
第一步先查询出’不想毕业’同学的班级id
select classes_id from student where name = '不想毕业';

第二步查询班级等于1 和名字不是 '不想毕业’的同学的名字
select name from student where classes_id = 1 and name != '不想毕业';
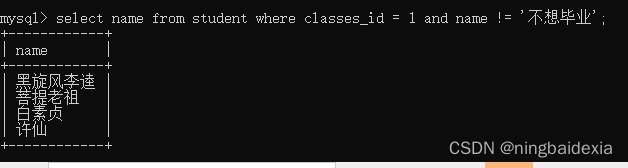
推荐两步完成的做法
子查询的做法
select name from student where classes_id = (select classes_id from student where name = '不想毕业') and name != '不想毕业';

这种操作和平时的开发理念背道而驰
不满足可读性高和效率高的思想
2.5 合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
创建两张表
create table student5 (id int,name varchar(10));
create table student6 (id int,name varchar(10));

select * from student5 union select * from student6;
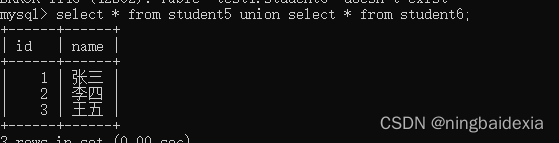
要求列类型和个数匹配
列名取决与前面的一个表















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









