







局域网抓取
bin/nutch crawl urls -dir 20090519 -depth 1 -topN 50 -threads 2 >& nutch.log
互联网抓取命令(注:1.0版本的命令和以前版本有许多不一样)
1.读取urls目录下的站点添加到crawldb里
bin/nutch inject 20090519/crawldb urls
2.创建一个segments,存放到20090519目录下
bin/nutch generate 20090519/crawldb 20090519/segments
3.根据文件夹20090519102635下生成的下载列表获取页面内容
bin/nutch fetch 20090519/segments/20090519102635/
4.从已下载的的段数据列表里获取URL链接,更新crawldb内容
bin/nutch updatedb 20090519/crawldb 20090519/segments/20090519102635
5.分析链接关系,生成反向链接
bin/nutch invertlinks 20090519/linkdb -dir 20090519/segments
6.创建页面内容索引
bin/nutch index 20090519/indexes 20090519/crawldb 20090519/linkdb 20090519/segments/20090519102635
7.删除重复数据
bin/nutch dedup 20090519/indexes
8.合并索引文件
bin/nutch merge 20090519/index 20090519/indexes
读取命令
1.查看crawldb数据库:bin/nutch readdb 20090519/crawldb/ -stats 这个命令可以查看url地址总数和它的状态及评分。
导出权重和相关的url信息:bin/nutch readdb 20090519/crawldb/ -topN 20 urldb(out_dir)
查看每个url地址的详细内容,导出数据:bin/nutch readdb 20090519/crawldb/ -dump crawldb(out_dir)
查看具体的url,以163为例:bin/nutch readdb 20090519/crawldb/ -url http://www.163.com/
2.查看linkdb数据库的链接情况:bin/nutch readlinkdb 20090519/linkdb/ -url http://www.163.com/
导出linkdb数据库文件:bin/nutch readlinkdb 20090519/linkdb/ -dump linkdb(out_dir)
3.查看segments:bin/nutch readseg -list -dir 20090519/segments/ 可以看到每一个segments的名称,产生的页面数,抓取的开始时间和结束时间,抓取数和解析数。
导出segments:bin/nutch readseg -dump 20090519/segments/20090309103156 segdb(out_dir)
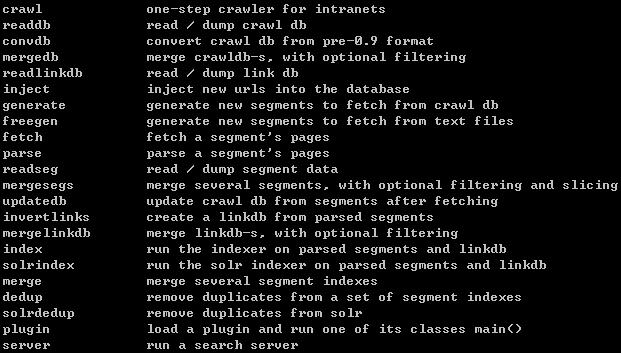
其他相关命令,可输入bin/nutch查看 各自具体用法自行参考
转载请注明















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









