







下载java环境
第一步、下载
下载Linux环境下的jdk1.8,请去(www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html)中下载jdk的安装文件;

第二步、解压安装包
将我们下载好的JDK安装包上传到服务器,进行解压
$ tar -zxvf jdk-8u271-linux-aarch64.tar.gz在这里修改一下文件名,将jdk1.8.0_181改成java,方便我们后面配置环境变量,在这也可以不修改,在配置环境变量时要注意文件名不能写错,修改文件名命令如下:
mv /home/java/jdk1.8.0_271 /home/java/jdk4、修改配置文件,配置环境变量,在命令行输入:
vi /etc/profile输入“G”定位到最后一行,按“i”进入编辑模式,在最下面添加如下几行信息:
第二个版本
export JAVA_HOME=/home/java/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}5、让配置文件生效,可以输入如下命令或者是重启系统
让环境变量立即生效需要执行如下命令
source /etc/profile6、查看安装情况
java -version安装前准备
检查系统是否已经有JDK,输入如下命令查看是否系统中是否已安装,部分人在安装CentOS 7时系统会自动安装JDK:
java -version如果系统没有安装,输入命令后提示如下(中文版和英文版在语言上会有些区别,但是提示的意思都一样),没有安装的可以直接跳过这里看下面的安装方法了:
-
[root@master100 ~]# java -version -
-bash: java: 未找到命令
如果显示如下版本信息说明已经安装,可以直接使用系统的JDK,不需要自己安装了
-
[root@master100 ~]# java -version -
java version "1.8.0_181" -
Java(TM) SE Runtime Environment (build 1.8.0_181-b13) -
Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
如果想使用其他版本的JDK,需要先卸载后再安装,卸载方法可以参考下文各种包的卸载方法。
1、简介
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
像天猫、京东这样的商城,用户访问商城的首页,一般都会直接搜索来寻找自己想要购买的商品。而商品的数量非常多,而且分类繁杂。
如果能正确的显示出用户想要的商品,并进行合理的过滤,尽快促成交易,是搜索系统要研究的核心。
面对这样复杂的搜索业务和数据量,使用传统数据库搜索就显得力不从心,一般我们都会使用全文检索技术,比如Solr,Elasticsearch。Elastic官网:https://www.elastic.co/cn/
Elastic有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash等,前面说的三个就是大家常说的ELK技术栈。
Elasticsearch(官网:https://www.elastic.co/cn/products/elasticsearch )是Elastic Stack 的核心技术。详细介绍参考官网
Elasticsearch具备以下特点:
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
2、安装
为了模拟真实场景,我们将在linux下安装Elasticsearch。 虚拟机(需要JDK1.8以上)
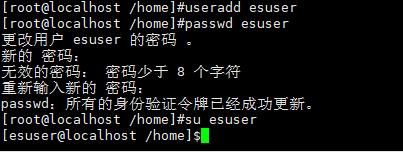
2.1:先新建一个用户(出于安全考虑,elasticsearch默认不允许以root账号运行。)
创建用户:useradd esuser
设置密码:passwd esuser
2.2:下载安装包
官网下载,选择linux版本:https://www.elastic.co/cn/products/elasticsearch 翻墙下载比较快
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.3-linux-x86_64.tar.gz
选择亦可下载,选择linux版本

2.3:上传安装包并解压
新建文件夹:mkdir es
我们将安装包上传到:/home/es目录
解压:tar -zxvf elasticsearch-7.9.3-linux-x86_64.tar.gz
目录重命名:mv elasticsearch-7.9.3 elasticsearch完成后,查看下目录结构:

2.4:修改配置文件
cd config需要修改的配置文件有两个:

Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数。编辑jvm.options
vi jvm.options修改默认配置:-Xms1g -Xmx1g为
编辑elasticsearch.yml修改数据和日志目录
vi elasticsearch.ymlnode.name: node-1 #配置当前es节点名称(默认是被注释的,并且默认有一个节点名)
cluster.name: my-application #默认是被注释的,并且默认有一个集群名
path.data: /home/es/data # 数据目录位置
path.logs: /home/es/logs # 日志目录位置network.host: 0.0.0.0 #绑定的ip:默认只允许本机访问,修改为0.0.0.0后则可以远程访问
cluster.initial_master_nodes: "node-1" #默认是被注释的 设置master节点列表 用逗号分隔
#cluster.initial_master_nodes: ["node-1", "node-2"] #默认是被注释的 设置master节点列表 用逗号分隔 ###############两个节点怎么用的,目前不清楚,备注一下
进入es的根目录,然后创建logs data
mkdir data
mkdir logs
elasticsearch.yml的其它可配置信息:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
2.5:修改/etc/security/limits.conf文件 增加配置
vi /etc/security/limits.conf 在文件最后,增加如下配置:
* soft nofile 65536
* hard nofile 65536在/etc/sysctl.conf文件最后添加一行 vm.max_map_count=655360 添加完毕之后,执行命令: sysctl -p
vi /etc/sysctl.conf
sysctl -p2.6:启动
先将es文件夹下的所有目录的所有权限迭代给esuser用户
进入home目录运行
chgrp -R esuser ./es
chown -R esuser ./es
chmod 777 es

启动:
先切换到esuser用户启动
su esuser
进入home/es目录运行
elasticsearch/bin/elasticsearch
nohup elasticsearch/bin/elasticsearch & 后台运行
可以看到绑定了两个端口:
-
9300:集群节点间通讯接口
-
9200:客户端访问接口

要开放9200的端口
我们在浏览器中访问

1.查找ES进程
ps -ef | grep elastic
2.杀掉ES进程
kill -9 2382(进程号)
3.重启ES
elasticsearch -d (常驻)
然后使用./bin/elasticsearch -d 后台启动elasticsearch,去掉-d则是前端启动elasticsearch
看看有没有es的进程:
| 1 |
|
- 在 es
elasticsearch.yml配置文件中添加配置启动 xpack
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true- 配置用户密码
./elasticsearch-setup-passwords auto
./elasticsearch-setup-passwords interactiveauto- Uses randomly generated passwords(自动生成密码)
interactive- Uses passwords entered by a user(交互式给每个用户设置密码)
配置默认用户的密码:(有如下的交互),可以使用auto自动生成。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









