






在复现端到端的语音克隆代码时遇到了GE2E loss,想记录一下这个loss。
先大概知道Triplet loss和T2E2 loss。
Triplet loss:示意图如下:
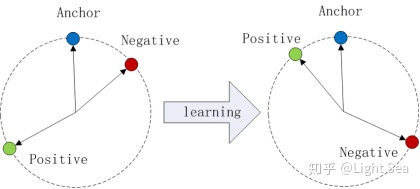
这种基于tuple的loss只考虑了一个tuple中anchor和其它data之间的关系。GE2E利用更少的数据考虑了更多的关系,从而同时实现了精度和训练效率两方面的提升。
T2E2 loss:和triplet loss非常相似,训练模型的时候每个batch都会有多个tuple,每个tuple包含一个anchor和多个positive或negative的data,TE2E中anchor和positive data可以理解为从同一个说话人的不同语音中得到的speaker embedding,而negative data则是不同于anchor的speaker的embedding。TE2E会使得anchor和positive data之间的相似度提升,同时降低anchor和negative data之间的相似度,从而区分了不同的speaker。
GE2E loss: 一种speaker verification (SV) 的通用的端到端损失函数 (generalized end-to-end loss, GE2E)。GE2E会使得网络在更新参数的时候注重于那些不容易被区分开的数据,且不需要在训练之前进行example selection。实验结果证明GE2E可以降低10%的EER和60%的训练时间。
speaker verification (SV) :验证输入的一段语音是否属于一个特定speaker的任务,这里有两个概念:1.enrollment utterance,可以理解为我们预留的“声纹”;2.verification utterance,是我们用于验证的语音。SV可以进一步细分为两种任务:text-dependent speaker verification (TD-SV)和text-independent verification (TI-SV)。TD-SV对用于验证的语音的内容有一定的限制,一个比较常见的例子是唤醒手机的语音助手,比如Siri,这个时候我们需要说出一个固定的句子“Hey, siri”。相反,TI-SV则不对语音的内容有任何限制。
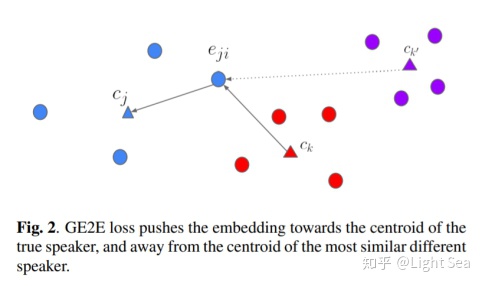
同一说话人(即同一类)内部距离为 ,不同类元素之间距离为
,
表示第j个说话人的第i个语段。这个loss的优化目标就是拉近同一类间的距离和增大不同类间的距离。
GE2E公式及代码:

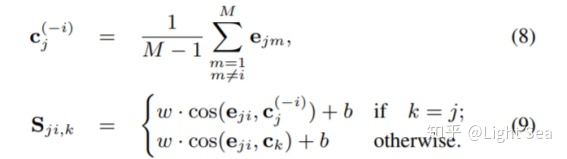
def ge2e(embeds):
speakers_per_batch, utterances_per_speak = embeds.shape[:2]
#公式(1)代码
#torch.norm()求范数,“+ 1e-5”避免分母为0
c_in = torch.mean(embeds, dim=1, keepdim=True)
c_in = c_in.clone() / (torch.norm(c_in, dim=2, keepdim=True) + 1e-5)
#公式(8)代码
c_ex = (torch.sum(embeds, dim=1, keepdim=True) - embeds)
c_ex /= (utterances_per_speak - 1)
c_ex = c_ex.clone() / (torch.norm(c_ex, dim=2, keepdim=True) + 1e-5)
sim_matrix = torch.zeros(speakers_per_batch, utterances_per_speaker,
speakers_per_batch).to(self.loss_device)
mask_matrix = 1 - np.eye(speakers_per_batch, dtype=np.int)
#公式(9)
for j in range(speakers_per_batch):
mask = np.where(mask_matrix[j])[0]
sim_matrix[mask, :, j] = (embeds[mask] * c_in[j]).sum(dim=2)
sim_matrix[j, :, j] = (embeds[j] * c_ex[j]).sum(dim=1)
sim_matrix = sim_matrix * self.similarity_weight + self.similarity_bias
return sim_matrixEER(Equal Error Rate),用于预先确定其错误接受率及其错误拒绝率的阈值,当速率相等时,公共值称为相等错误率。等错误率值越低,生物识别系统的准确度越高。

ground_truth = np.repeat(np.arange(speakers_per_batch), utterances_per_speaker)
inv_argmax = lambda i: np.eye(1, speakers_per_batch, i, dtype=np.int)[0]
labels = np.array([inv_argmax(i) for i in ground_truth])
preds = sim_matrix.detach().cpu().numpy()
# Snippet from https://yangcha.github.io/EER-ROC/
fpr, tpr, thresholds = roc_curve(labels.flatten(), preds.flatten())
eer = brentq(lambda x: 1. - x - interp1d(fpr, tpr)(x), 0., 1.)














 1590
1590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









