







Regularized logistic regression
一、题目再现
在这一部分的练习中,你将运用正则化的逻辑回归来预测制造工厂的微芯片是否通过质量保证(QA)。在质量保证过程中,每个微芯片都要经过各种测试,以确保其功能正常。
假设你是工厂的项目经理并且你拥有一些芯片关于两项不同测试的测试结果。根据这两项测试,你可以决定芯片应该被接受还是被拒绝。为了帮助你做出决定,你由一个有关过去芯片的测试结果集,从中可以构建逻辑回归模型。
二、数据集
0.051267,0.69956,1
-0.092742,0.68494,1
-0.21371,0.69225,1
-0.375,0.50219,1
-0.51325,0.46564,1
-0.52477,0.2098,1
-0.39804,0.034357,1
-0.30588,-0.19225,1
0.016705,-0.40424,1
0.13191,-0.51389,1
0.38537,-0.56506,1
0.52938,-0.5212,1
0.63882,-0.24342,1
0.73675,-0.18494,1
0.54666,0.48757,1
0.322,0.5826,1
0.16647,0.53874,1
-0.046659,0.81652,1
-0.17339,0.69956,1
-0.47869,0.63377,1
-0.60541,0.59722,1
-0.62846,0.33406,1
-0.59389,0.005117,1
-0.42108,-0.27266,1
-0.11578,-0.39693,1
0.20104,-0.60161,1
0.46601,-0.53582,1
0.67339,-0.53582,1
-0.13882,0.54605,1
-0.29435,0.77997,1
-0.26555,0.96272,1
-0.16187,0.8019,1
-0.17339,0.64839,1
-0.28283,0.47295,1
-0.36348,0.31213,1
-0.30012,0.027047,1
-0.23675,-0.21418,1
-0.06394,-0.18494,1
0.062788,-0.16301,1
0.22984,-0.41155,1
0.2932,-0.2288,1
0.48329,-0.18494,1
0.64459,-0.14108,1
0.46025,0.012427,1
0.6273,0.15863,1
0.57546,0.26827,1
0.72523,0.44371,1
0.22408,0.52412,1
0.44297,0.67032,1
0.322,0.69225,1
0.13767,0.57529,1
-0.0063364,0.39985,1
-0.092742,0.55336,1
-0.20795,0.35599,1
-0.20795,0.17325,1
-0.43836,0.21711,1
-0.21947,-0.016813,1
-0.13882,-0.27266,1
0.18376,0.93348,0
0.22408,0.77997,0
0.29896,0.61915,0
0.50634,0.75804,0
0.61578,0.7288,0
0.60426,0.59722,0
0.76555,0.50219,0
0.92684,0.3633,0
0.82316,0.27558,0
0.96141,0.085526,0
0.93836,0.012427,0
0.86348,-0.082602,0
0.89804,-0.20687,0
0.85196,-0.36769,0
0.82892,-0.5212,0
0.79435,-0.55775,0
0.59274,-0.7405,0
0.51786,-0.5943,0
0.46601,-0.41886,0
0.35081,-0.57968,0
0.28744,-0.76974,0
0.085829,-0.75512,0
0.14919,-0.57968,0
-0.13306,-0.4481,0
-0.40956,-0.41155,0
-0.39228,-0.25804,0
-0.74366,-0.25804,0
-0.69758,0.041667,0
-0.75518,0.2902,0
-0.69758,0.68494,0
-0.4038,0.70687,0
-0.38076,0.91886,0
-0.50749,0.90424,0
-0.54781,0.70687,0
0.10311,0.77997,0
0.057028,0.91886,0
-0.10426,0.99196,0
-0.081221,1.1089,0
0.28744,1.087,0
0.39689,0.82383,0
0.63882,0.88962,0
0.82316,0.66301,0
0.67339,0.64108,0
1.0709,0.10015,0
-0.046659,-0.57968,0
-0.23675,-0.63816,0
-0.15035,-0.36769,0
-0.49021,-0.3019,0
-0.46717,-0.13377,0
-0.28859,-0.060673,0
-0.61118,-0.067982,0
-0.66302,-0.21418,0
-0.59965,-0.41886,0
-0.72638,-0.082602,0
-0.83007,0.31213,0
-0.72062,0.53874,0
-0.59389,0.49488,0
-0.48445,0.99927,0
-0.0063364,0.99927,0
0.63265,-0.030612,0
三、Python实现思路
1. 引入数据(简单方式)
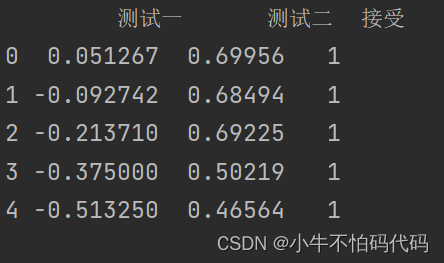
data = pd.read_csv("D:\BaiduNetdiskDownload\ex2\ex2data2.txt", header=None, names=['测试一', '测试二', '接受'])
print(data.head())这一步可以打印出初始数据结果,如下图所示:
2. 数据可视化——绘制散点图
positive = data[data['接受'].isin([1])] # 取Admitted这一行,用isin函数查看是否存在1,若存在返回布尔值true1
negetive = data[data['接受'].isin([0])]
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(positive['测试一'], positive['测试二'], s=50, c='b', label='接受')
ax.scatter(negetive['测试一'], negetive['测试二'], s=50, c='r', marker='x', label='未接受')
ax.legend()
ax.set_xlabel('测试一')
ax.set_ylabel('测试二')
plt.show()这一步将绘制散点图,如下图所示:
 3. 特征映射
3. 特征映射
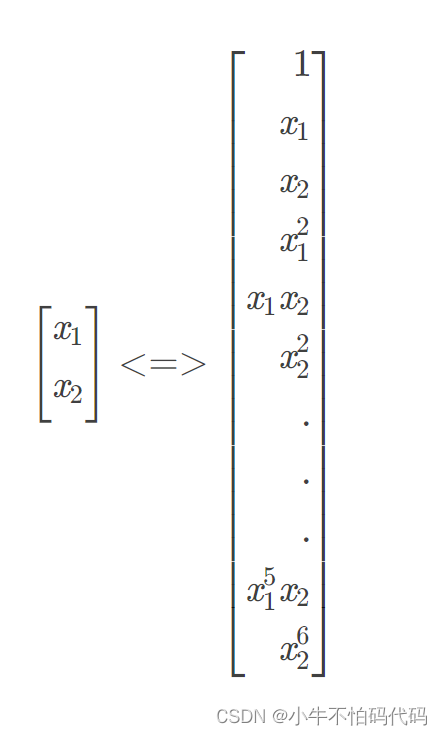
为了能很好的拟合,所以我们要进行特征映射,从而得到非线性的决策边界。特征映射将低维特征向量(本例中为二维)转化为高维特征向量(本例中为28维),因为特征向量的个数变多,所以需要用正则化,否则容易出现过拟合。映射的关系图如下图所示:
#1.定义特征映射函数
def feature_mapping(x1,x2,power):
data={}
for i in np.arange(power+1):
for p in np.arange(i+1):
data["f{}{}".format(i-p,p)]=np.power(x1,i-p)*np.power(x2,p)
return pd.DataFrame(data)
#2、将特征变量进行特征映射
x1=df['测试一']
x1=x1.values
x2=df['测试二']
x2=x2.values
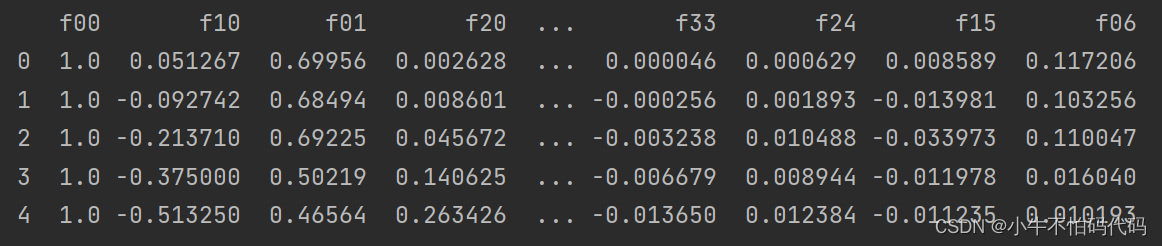
df2=feature_mapping(x1,x2,6)
print(df2.head())
#3、重新选取变量
X=df2.values # 将特征映射后得到的变量定义为X
y=df['接受'].values
theta=np.zeros(X.shape[1])
这一步输出的结果,如下所示:
4. 正则化代价函数
为了防止过拟合,采用L2正则化方法,代价函数为:
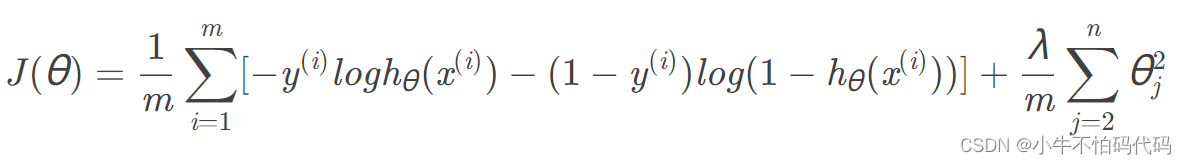
注意:第一项θ1 不参与正则化
梯度为:

#1、定义sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#2、定义代价函数
def cost(theta,X,y):
first=y@np.log(sigmoid(X@theta)) # @表示矩阵乘法
second=(1-y)@np.log(1-sigmoid(X@theta))
return (first+second)/(-len(X))
#3、定义正则化代价函数
def costReg(theta,X,y,lam=1):
_theta=theta[1:]
reg=(lam/(2*len(X)))*(_theta@_theta)
return cost(theta,X,y)+reg
#4、代价函数初始值
costReg(theta,X,y)5. 高级优化算法求theta
#1、定义正则化后的梯度函数(偏导数)
def gradient(theta,X,y):
return (X.T@(sigmoid(X@theta)-y))/(len(X))
def gradientReg(theta,X,y,lam=1):
reg=(lam/len(X))*theta
reg[0]=0 # 第一项没有惩罚因子
return gradient(theta,X,y)+reg
#2、使用高级优化算法求theta
result=opt.fmin_tnc(func=costReg,x0=theta,fprime=gradientReg,args=(X,y,2))
6. 求预测准确率(进行评估)
#定义预测函数,将求得的参数theta(result) 和X(特征映射后)带入预测函数,并计算预测精度
def predict(theta,X):
probability=sigmoid(X@theta)
return [1 if x>=0.5 else 0 for x in probability ]
finally_theta=result[0]
predictions=predict(finally_theta,X)
correct=[1 if a==b else 0 for (a,b) in zip(predictions,y)]
accuracy=sum(correct)/len(X)
print(accuracy)
输出的预测准确率为:0.8305084745762712
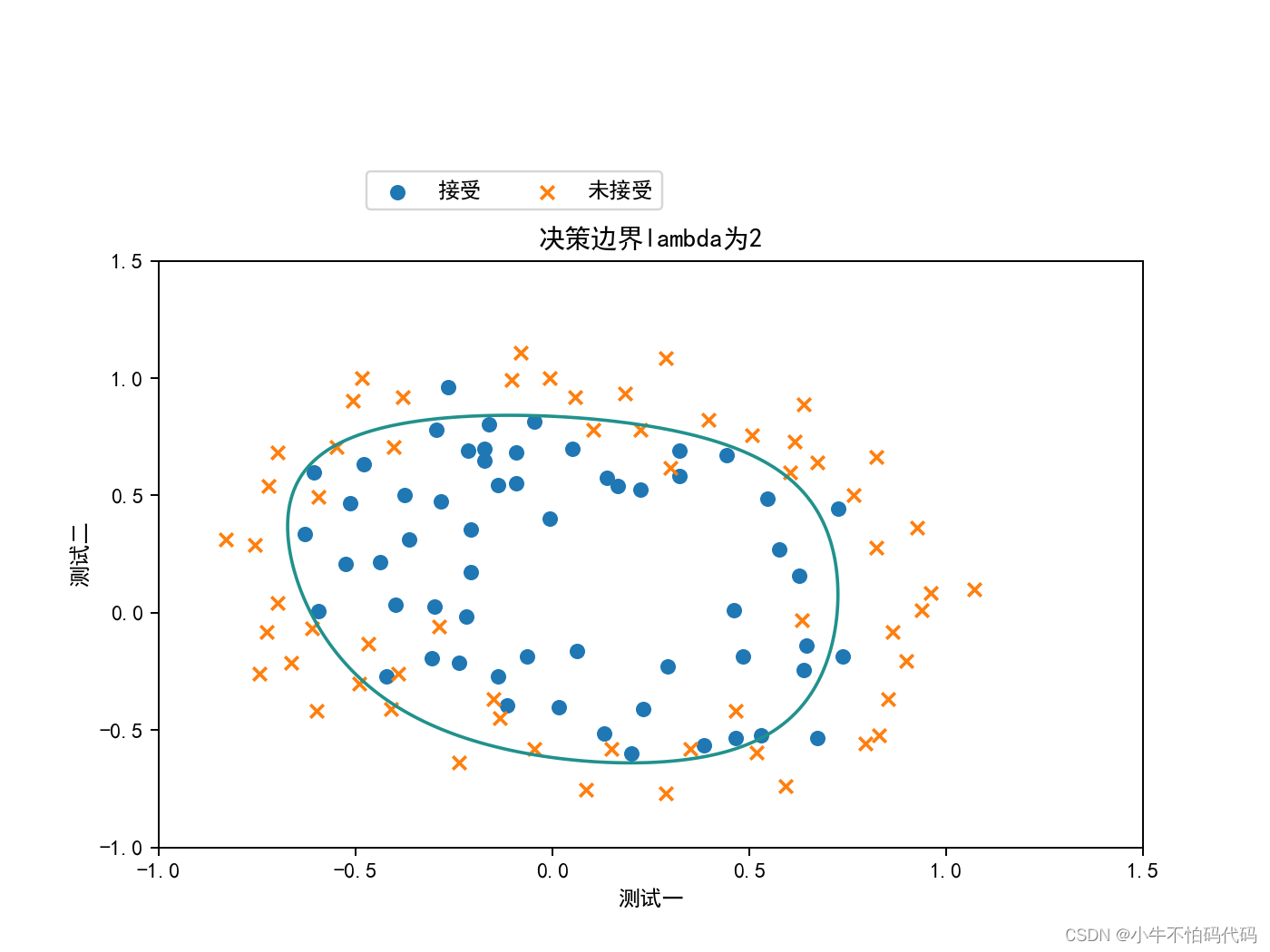
7. 绘制决策边界
x = np.linspace(-1, 1.5, 250)
xx, yy = np.meshgrid(x, x) #生成网格点坐标矩阵
# 得到的xx,yy是array形式,维度为(250,250)
z = feature_mapping(xx.ravel(), yy.ravel(), 6).values # xx.ravel()将xx一维化(62500,)
z = z @ finally_theta #z.shape (62500,)
z = z.reshape(xx.shape)
fig,ax=plt.subplots(figsize=(8,6))
ax.scatter(positive['测试一'],positive['测试二'],label='接受')
ax.scatter(negetive['测试一'],negetive['测试二'],marker='x',label='未接受')
# 设置图例显示在图的上方
box = ax.get_position() #获取轴
ax.set_position([box.x0,box.y0,box.width,box.height*0.8]) #.set_position()功能用于设置轴位置
ax.legend(loc='center left',bbox_to_anchor=(0.2,1.12),ncol=3)
ax.set_xlabel('测试一')
ax.set_ylabel('测试二')
ax.set_title('决策边界lambda为2')
plt.contour(xx,yy,z,0) # 生成等高线,0是指图像一分为二
plt.show()这一步绘制出的结果,如下图所示:
四、完整代码
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import scipy.optimize as opt
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 用黑体显示中文
matplotlib.rcParams['axes.unicode_minus'] = False # 可以显示负号
# 第一步 引入数据
data = pd.read_csv("D:\BaiduNetdiskDownload\ex2\ex2data2.txt", header=None, names=['测试一', '测试二', '接受'])
print(data.head())
# 第一部分 数据可视化 绘制散点图
positive = data[data['接受'].isin([1])] # 取Admitted这一行,用isin函数查看是否存在1,若存在返回布尔值true1
negetive = data[data['接受'].isin([0])]
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(positive['测试一'], positive['测试二'], s=50, c='b', label='接受')
ax.scatter(negetive['测试一'], negetive['测试二'], s=50, c='r', marker='x', label='未接受')
ax.legend()
ax.set_xlabel('测试一')
ax.set_ylabel('测试二')
plt.show()
# 第二部分——特征映射(为了能很好地拟合,所以我们要进行特征映射,从而得到非线性的决策边界)
# 特征映射将低维特征向量(本例中为二维)转化为高维特征向量(本例中为28维),因为特征向量的个数变多,所以需要正则化,否则容易出现过拟合。
#1.定义特征映射函数
def feature_mapping(x1,x2,power):
data={}
for i in np.arange(power+1):
for p in np.arange(i+1):
data["f{}{}".format(i-p,p)]=np.power(x1,i-p)*np.power(x2,p)
return pd.DataFrame(data)
#2、将特征变量进行特征映射
x1=data['测试一']
x1=x1.values
x2=data['测试二']
x2=x2.values
data2=feature_mapping(x1,x2,6)
print(data2.head())
#3、重新选取变量
X=data2.values # 将特征映射后得到的变量定义为X
y=data['接受'].values
theta=np.zeros(X.shape[1])
#第三部分 正则化代价函数
#1、定义sigmoid函数
def sigmoid(z):
return 1/(1+np.exp(-z))
#2、定义代价函数
def cost(theta,X,y):
first=y@np.log(sigmoid(X@theta)) # @表示矩阵乘法
second=(1-y)@np.log(1-sigmoid(X@theta))
return (first+second)/(-len(X))
#3、定义正则化代价函数
def costReg(theta,X,y,lam=1):
_theta=theta[1:]
reg=(lam/(2*len(X)))*(_theta@_theta)
return cost(theta,X,y)+reg
#4、代价函数初始值
costReg(theta,X,y)
#第四部分 高级优化算法求theta
#1、定义正则化后的梯度函数(偏导数)
def gradient(theta,X,y):
return (X.T@(sigmoid(X@theta)-y))/(len(X))
def gradientReg(theta,X,y,lam=1):
reg=(lam/len(X))*theta
reg[0]=0 # 第一项没有惩罚因子
return gradient(theta,X,y)+reg
#2、使用高级优化算法求theta
result=opt.fmin_tnc(func=costReg,x0=theta,fprime=gradientReg,args=(X,y,2))
#第五部分 求预测准确率(进行评估)
#1、定义预测函数,将求得的参数theta(result) 和X(特征映射后)带入预测函数,并计算预测精度
def predict(theta,X):
probability=sigmoid(X@theta)
return [1 if x>=0.5 else 0 for x in probability ]
finally_theta=result[0]
predictions=predict(finally_theta,X)
correct=[1 if a==b else 0 for (a,b) in zip(predictions,y)]
accuracy=sum(correct)/len(X)
print(accuracy)
#或者用sklearn中的方法进行评估
'''
from sklearn.metrics import classification_report
print(classification_report(predictions,y))
'''
#第六部分 绘制决策边界
x = np.linspace(-1, 1.5, 250)
xx, yy = np.meshgrid(x, x) #生成网格点坐标矩阵
# 得到的xx,yy是array形式,维度为(250,250)
z = feature_mapping(xx.ravel(), yy.ravel(), 6).values # xx.ravel()将xx一维化(62500,)
z = z @ finally_theta #z.shape (62500,)
z = z.reshape(xx.shape)
fig,ax=plt.subplots(figsize=(8,6))
ax.scatter(positive['测试一'],positive['测试二'],label='接受')
ax.scatter(negetive['测试一'],negetive['测试二'],marker='x',label='未接受')
# 设置图例显示在图的上方
box = ax.get_position() #获取轴
ax.set_position([box.x0,box.y0,box.width,box.height*0.8]) #.set_position()功能用于设置轴位置
ax.legend(loc='center left',bbox_to_anchor=(0.2,1.12),ncol=3)
ax.set_xlabel('测试一')
ax.set_ylabel('测试二')
ax.set_title('决策边界lambda为2')
plt.contour(xx,yy,z,0) # 生成等高线,0是指图像一分为二
plt.show()
本文是我个人的学习记录,由于本人才疏学浅,在学习的过程中是边参考着别人的知识总结边学习的,以下是我参考的链接:
若大家发现本文有任何不当或不正确之处,请在评论区批评指正,我会及时查看并加以修正!若对大家有所启发请多多点赞,支持一下!谢谢!
















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











