







学习提示
第二门课的知识点比较分散,开始展示每周的笔记之前,我会先梳理一下每周涉及的知识。
这一周会先介绍改进机器学习模型的基本方法。为了介绍这项知识,我们会学习两个新的概念:数据集的划分、偏差与方差问题。知道这两个概念后,我们就能够诊断当前机器学习模型存在的问题,进而找出改进的方法。
之后,我们会针对“高方差问题”,学习一系列解决此问题的方法。这些方法成为“正则化方法”。这周介绍的正则化方法有:添加正则化项、dropout、数据增强、提前停止。
最后,我们会学习几项和神经网络相关的技术。我们会学习用于加速训练的输入归一化,用于防止梯度计算出现问题的参数带权初始化,以及用于程序调试的梯度检查。
课堂笔记
数据集的划分:训练集/开发集/测试集
在使用机器学习的数据集时,我们一般把数据集分成三份:训练集、开发集、测试集。
机器学习是比深度学习的父集,表示一个更大的人工智能算法的集合。
开发集(Development Set)另一种常见的称呼是验证集(Validation Set),即保留交叉验证(Hold-out Cross Validation)。
三种数据集的定义
它们三者的区别如下:
| 训练集 | 开发集 | 测试集 | |
|---|---|---|---|
| 用于优化参数 | 是 | 否 | 否 |
| 训练时可见? | 是 | 是 | 否 |
| 最终测试时可见? | 是 | 是 | 是 |
训练集就是令模型去拟合的数据。对于神经网络来说,我们把某类数据集输入进网络,之后用反向传播来优化网络的参数。这个过程中用的数据集就是训练集。
开发集是我们在训练时调整超参数时用到的数据集。我们会测试不同的超参数,看看模型在开发集上的性能,并选择令模型在开发集上最优的一组超参数。
测试集是我们最终用来评估模型的数据集。当模型在测试集上评测时,我们的模型已经不允许修改了。我们一般把模型在测试集上的评测结果作为模型的性能评估标准。
在我们之前实现的小猫分类项目中,准确来说,我们使用的不叫测试集,而叫做开发集,因为我们是根据那个"testing set"优化网络超参数的。
有人把训练集比作上课,开发集比作作业,测试集比作考试。如果你理解了这三个数据集的原理,会发现这个比喻还是挺贴切的。事实上,由于测试集不参与训练,一个机器学习项目可以没有测试集,就像我们哪怕不经过考试,也可以学到知识一样。
人们很容易混淆开发集/测试集。很多论文甚至把开发集作为最终的性能评估结果。但是很多时候审稿人对这些细节并不在意。作为有操守的研究者,应该严肃地区分开发集与测试集。
通过划分数据得到训练/测试集
在前一个机器学习纪元,人们通常会拿到一批数据,按7:3的比例划分训练集/测试集(对于没有超参数要调的模型),或者按6:2:2的比例划分训练集/开发集/测试集。
而在深度学习时代,数据量大大增加。实际上,开发集和测试集的目的都是评估模型,而评估模型所需的数据没有训练需要得那么多。所以,当整体的数据规模达到百万级,甚至更多时,我们只需要各取10000组数据作为开发集和测试集即可。
收集来自不同分布的数据集
除了从同一批数据中划分出不同的数据集,还有另一种得到训练集、测试集的方式——从不同分布中收集数据集。
分布是统计学里的概念,这里可以理解成不同来源,内容的“平均值”差别很大的数据。
比如,假如我们要为某个小猫分类器收集小猫的图片,我们的训练图片可以是来自互联网,而开发和验证的数据来自用户用收集拍摄的图片。
注意,由于开发集和验证集都是用来评估的,它们应该来自同一个分布。
偏差与方差
机器学习中,我们的模型会出现高偏差或/和高误差的问题。我们需要设法判断我们的模型是否有这些问题。
偏差(bias)与方差(variance)是统计学里的概念,前者表示一组数据离期待的平均值的差距,后者表示数据的离散程度。
试想一个射击运动员在打靶。偏差与打靶的总分数有关,因为总分越高,意味着每次射击都很靠近靶心;方差与选手的发挥稳定性有关,比如一个不稳定的选手可能一次9环,一次6环。
高偏差意味着模型总是不能得到很好的结果,高方差意味着模型不能很好地在所有数据集上取得好的结果(即只能在某些特定数据集上表现较好,在其他数据集上都表现较差)。
我们把高偏差的情况叫做“欠拟合”(可能模型还没有训练完,所以表现不够好),把高方差的情况叫做“过拟合”(模型在训练集上训练过头了,结果模型只能在训练集上有很好的表现,在其他数据集上表现偶读不好)。
让我们看课件里的一个点集分类的例子:
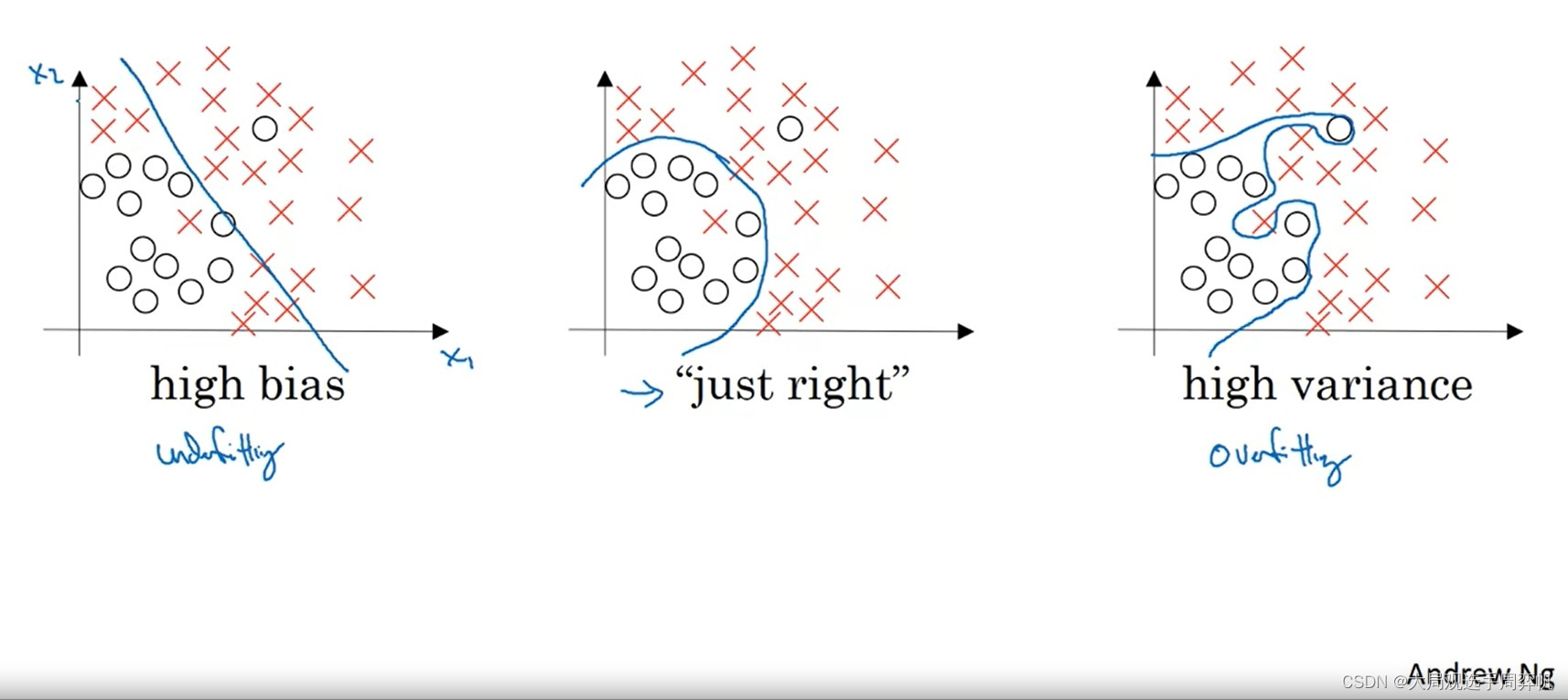
上图显示了欠拟合、“恰好”、过拟合这三种情况。
对于欠拟合的情况来说,一条直线并不足以把两类点分开,这个模型的整体表现较差。
对于过拟合的情况来说,模型过分追求训练集上的正确,结果产生了一条很奇怪的曲线。由于训练数据是有噪声(数据的标签不完全正确)的,这样的模型在真正的测试上可能表现不佳。
让我们人类来划分的话,最有可能给出的是中间那种划分结果。在这个模型中,虽然有些训练集中的点划分错了,但我们会认为这个模型在绝大多数数据上更合适。当我们用更多的测试数据来测试这个模型时,中间那幅图的测试结果肯定是这三种中最好的。
要判断机器学习模型是否存在高偏差或高方差的现象,可以去观察模型的训练集误差和开发集误差。以下是一个判断示例:
| 情况 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 训练集误差 | 1% | 15% | 0.5% | 15% |
| 开发集误差 | 11% | 16% | 1% | 30% |
| 诊断结果 | 高方差 | 高偏差 | 低误差、低方差 | 高误差、高方差 |
也就是说,如果开发集和训练集的表现差很多,就说明是高方差;如果训练集上的表现都很差,就是高偏差。
上面这些结论建立在最优误差——贝叶斯误差(Beyas Error)是0%的基础上下的判断。很多时候,仅通过输入数据中的信息,是不足以下判断的。比如告诉一个人是长头发,虽然这个人大概率是女生,但我们没有100%的把握说这是女生。如果我们知道人群中留长发的90%是女生,10%是男生,那么在这个“长头发分辨性别”的任务里的贝叶斯误差就是10%。
假如上面那个任务的贝叶斯误差是15%,那么我们认为情况2也是一个低误差的情况,因为它几乎做到了最优的准确率。
改进机器学习的基本方法
通过上一节介绍的看训练误差、测试误差的方式,我们能够诊断出我们的模型当前是否存在高偏差或高误差的问题。这一节我们来讨论如何解决这些问题。
首先检查高偏差问题。如果模型存在高偏差,则应该尝试使用更复杂的网络、更多增加训练时间。
确保模型没有高偏差问题后,才应该开始检查模型的方差。如果模型存在高方差,则应该增加数据或使用正则化。
此外,使用更合理的网络架构,往往对降低误差和方差都有效。
正则化 (Regularization)
其实正则化的意思就是“为防止过拟合而添加额外信息的过程”。在机器学习中,一种正则化方法是给损失函数添加一些与参数有关的额外项,以调整参数在梯度下降中的更新过程。正则化的数学原理我们会在下一节里学习,这一节先认识一下正则化是怎么操作的。
先看一下,对于简单的逻辑回归,我们应该怎么加正则化项。
原来,逻辑回归的损失函数是:
J ( w , b ) = 1 m Σ i = 1 m L ( y ^ , y ) J(w, b) = \frac{1}{m}\Sigma_{i=1}^{m}L(\hat{y}, y) J(w,b)=m1Σi=1mL(y^,y)
现在我们给它加一个和参数 w w w有关的项
J ( w , b ) = 1 m Σ i = 1 m L ( y ^ , y ) + λ 2 m ∣ ∣ w 2 ∣ ∣ 2 J(w, b) = \frac{1}{m}\Sigma_{i=1}^{m}L(\hat{y}, y) + \frac{\lambda}{2m}||w^2||_2 J(w,b)=m1Σi=1mL(y^,y)+2mλ∣∣w2∣∣2
最右边那个 λ 2 m ∣ ∣ w ∣ ∣ 2 2 \frac{\lambda}{2m}||w||^2_2 2mλ∣∣w∣∣22 就是额外加进来的正则项。其中 λ \lambda λ是一个可调的超参数, ∣ ∣ w ∣ ∣ 2 2 ||w||^2_2 ∣∣w∣∣22表示计算向量 w w w的l2范数,即:
∣ ∣ w ∣ ∣ 2 2 = Σ j = 1 n x w j 2 ||w||^2_2 = \Sigma_{j=1}^{n_x}w_j^2 ∣∣w∣∣22=Σj=1nxwj2
也就是说,某向量的l2范数就是它所有分量平方再求和。
类似地,其实向量也有1范数,也可以用来做正则化:
∣ ∣ w ∣ ∣ 1 = Σ j = 1 n x ∣ w j ∣ ||w||_1 = \Sigma_{j=1}^{n_x}|w_j| ∣∣w∣∣1=Σj=1nx∣wj∣
1范数就是向量所有分量取绝对值再求和。
使用1范数做正则化会导致参数中出现很多0。人们还是倾向使用l2范数做正则化。
看到这里,大家或许会有问题: b b b也是逻辑回归的参数,为什么 w w w有正则项, b b b就没有?实际上,要给 b b b加正则项也可以。但是在大多数情况下,参数 w w w的数量远多于 b b b, 和 b b b相关的正则项几乎不会影响到最终的损失函数。为了让整个过程更简洁一些, b b b的正则项就被省略了。(其实就是程序员们偷懒了,顺便让计算机也偷个懒)
当情况推广到神经网络时,添加正则项的方法是类似的,只不过参数 W W W变成了矩阵而已。对应的正则项如下:
λ 2 m Σ l = 1 L ∣ ∣ W [ l
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









