






数据库查询的实现
对内存中的元素进行查询(query)十分快速,因为内存的速度十分快,所以可以随意I/O内存,当然这里的”上家”指的是CPU的缓存。至于缓存(Cache),那速度就更快了。但是互联网的发展,已经不仅仅需要内存查询,而是需要大型数据库查询。要把一个数据库放在内存里运行代价很昂贵,虽然有人那么做,但毕竟不是主流。很多巨型库的数据量非常大。
1. 文件存储在低速硬盘上
所以首先是结合一下实际情况:文件是存储在硬盘上面的。当下硬盘的读取速度十分有限,与RAM相比差了好多个数量级,当下最快的SSD可能是intel 900P ,这个是基于新技术3D Xpoint的寿命超长、速度超快的SSD。尽管它的I/O都是2GBps-3GBps,但是这个速度与RAM比起来还是显得可怜。
所以在进行查询定位某个数据的时候,应该尽可能地减少磁盘I/O次数。这里必须要明确一点:一个文件里面写有相当多的数据,而我们要定位的数据就在一个或者多个文件里。当我们要定位文件里的数据时,首先要进行读文件(read file),但是一个文件可能相当大,大文件很难进行一次性内存读入,甚至在很多情况下不能把一个文件读入内存!如果有Linux运维经验的同学可能知道,查看一个.log日志可能无法完成,log日志可以无限制扩大,从而产生一个庞大无比的纯文本文件。网络web日志更是如此,在数据量级上,web服务器日志所处位置很高。能打开好多个GB大小的文本已经成为了此一种技术优势,常见的Notepad++做不到,EmEditor却可以。
2. 磁盘的地址划分
磁盘与内存一样,都是有地址的,至于为什么会有地址,那是因为组织文件的需要。
不用特别了解组织文件的具体形式,只需要记得,磁盘是有存储结构的,每一个区块,都有自己的编号。具体说来,就是所在盘号(这可不是C盘D盘之类的号,而是一块物理硬盘上,具体的第几块盘片)、上下面、哪个单元,这一系列数据通过一定格式,就被定义为了磁盘地址,这个地址是真正的物理地址,而不是逻辑地址。
磁盘可以被划分为不同大小的簇,一个簇可以存放几十KB到几MB不等大小的数据。而与之相比,磁盘簇的编码所用字符实在是微不足道。

上图是磁盘结构。看完这个结构图,就可以明白希捷(Seagate)的单碟1TB技术是什么意思了。搞软件、搞算法必然要懂点硬件。这样才能知道很多东西是为什么要被制造出来的! 话不多说,明白了磁盘的地址标定,就可以进行算法设计了。
3. 查询函数的设计
要问算法与数据结构谁重要,我认为是数据结构。因为结构设计存储结构,所以与硬件水平相关;同时算法是依赖于数据结构的,基本上数据结构定下来了,算法也就确定了。所以数据结构应该更重要。
弄明白了磁盘存储的形式,就可以有针对性地进行查询函数的设计了。比如,我们建立了一个存储体积相当大的学生名单,学生名单表的主键之类的数据都是完善的(这里有必要提及一下关系型数据的基本表)。我们要在这个表中查询一个叫吉米的学生的相关信息。这时候如果按照一个一个地比姓名的方法,就非常低效。如果有N个数据元组,CPU一次读取可以读
k
个元组,那么我们要进行
一次比一个效率不高,那么能否一次比一批数据呢?这个时候我们可以参考一下二叉搜索树的设计。二叉搜索树十分简单,就是针对一个有序的树进行的查询,对于一个非子节点的节点,其左子树的所有数据都小于该子节点的数,右子树中的所有数据都大于该子节点的数值。
如果用一棵二叉搜索树保存这个文件,那么查询起来就非常简单了!因为在每一层进行一次比较就可以抛弃一棵子树的数据,所以I/O复杂度为 O(log(Height)) ,比较简单吧。
接下来的第一个问题是二叉搜索树好不好?很显然它还不够好,因为二叉搜索树有可能很高,这样进行查询的复杂度还是有点大。这里要特别注意I/O复杂度这个概念,这个概念不是CPU复杂度,而是说,目前制约速度的主要因素是I/O而不是其他的。二叉树要是很高,定位一个数据就可能要一层一层地走下去,走一层就进行一次I/O,至于为什么这么说,我们要结合算法进行说明。
二叉搜索树可能很不平衡,所谓的平衡是左右大小一致。如果root的左子树很茂盛,而右子树基本没有纸业,那这就不是平衡树。考虑不平衡的一个极端情况:任意一个非叶节点,仅有左子树(右子树也一样)。这种极端情况,与那种线性表无区别。而且它的高度还是 N <script type="math/tex" id="MathJax-Element-1808">N</script> ,基本没什么用。
知道不好,那么能否把这棵树做平衡了呢?当然可以,亲爱的数据结构与算法课早就给出了平衡算法。但是平衡算法也不好,大医治未病,出了问题再找医生不好。有一种树叫做平衡树,如AVL树、(2, 4)树,红黑树。这样的树可以保证在建树过程中,一直是平衡的。这可以很好地避免一些问题。
树做平了,是不是就够了?当然没有。如果能让树变矮一点就更好了。B树横空出世。
把一棵树存在硬盘上,通过链式结构的形式进行存放。
- 根节点(root)
- 子节点(offspring)
节点上面存放一些结构化的线性数据。
节点单纯存放数据不行,为了方便查询还需要有一定的冗余存储。这一部分冗余存储就是磁盘簇的地址。在初始化这棵树的时候,这棵树必然是存放在内存中,这样我们就可以按照链式结构进行存放。
当内存中的初始化工作已经结束,可以先申请几块磁盘簇(这里的数量是有严格规定的,具体与磁盘簇的大小有关),第一个磁盘簇,存放这棵树的根节点的数值,同时存放下面几个节点的磁盘地址。同理,存放其他的元素亦如是,直到存放完所有的树。
这时候,先不论如何更新这棵树,先看如何查询:2中很明显地体现了这个过程。每一个节点中的红色,是元素,黄色是地址。红色的数目不超过2,说明一个磁盘簇不能存放超过两个元素。当然实际过程中远比2要大。有了这棵树,就可以对文件进行检索。所以从中可以看到,巨型文本文件被分成了好多个簇存储在了硬盘上。而这也正是磁盘存储的实质,千万不要以为文件在光滑的盘片上是连续的一整个区段!
链式存储带来的好处,显而易见,那就是Insert的时候,不需要搬移很多数据,直接申请地址就可以了。就像C中的malloc函数。
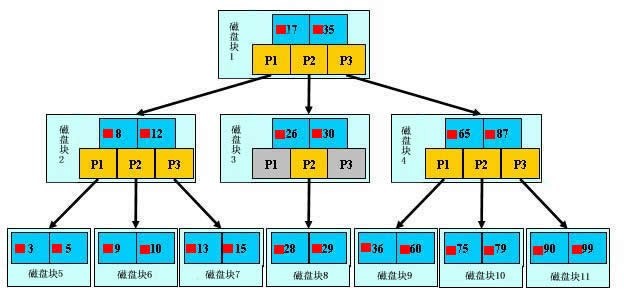
关于B树,这里就不详细介绍了,他与红黑树、2-4树类似,也是一种平衡树,而且随着每个“簇”中文件的变多,一层之下可以存放相当可观的数据,从而遍历极少数的数据,就可以定位。当然,这样造成的I/O次数也比较少。更适合文件系统的B+树,下次介绍。
[1]: http://www.elimu.net/Secondary/Kenya/KCSE_Past_Papers/KCSE%202010/Computer%20Studies/KCSE_2010_COMP_P1/Images/Hard_Disk.png
[2]: http://hi.csdn.net/attachment/201106/7/8394323_13074405906V6Q.jpg














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









