







大型语言模型(Large Language Models,简称LLMs)是一类使用深度学习技术训练的自然语言处理(NLP)模型,它们在大量的文本数据上进行训练,以理解和生成人类语言。这些模型通常具有数亿甚至数千亿个参数,使它们能够捕捉到语言的复杂性和细微差别。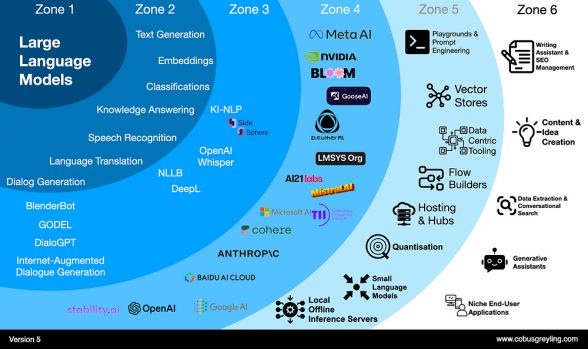
上图显示了大型语言模型的出现引起的涟漪,可以分为六个带或区。随着这些涟漪的扩大,对产品和服务的要求和机会也随之而来。
其中一些机会已经被发现,一些还有待发现。我认为,与5区相比,6区作为产品被取代的危险更大。
第5区提供了更大的差异化机会、大量的内置知识产权和一流的用户体验,使企业能够利用LLM的力量。5区令人兴奋的发展包括量化、小语言模型、模型花园/中心和以数据为中心的工具。
区域 1 — 可用的大型语言模型
就LLM而言,本质上LLM是语言绑定的,然而,在图像、音频等方面已经引入了多模态模型或多模态。这种转变催生了一个更通用的术语,即基础模型。
除了模式的增加之外,大型商业提供商还实现了模型多样化,提供了更针对特定任务的多种模型。还提供了大量开源模型。开源模型的可用性和性能带来了简单的无代码托管选项,用户可以通过无代
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











