











H20算力秘密: GPU算力评估
一、从H20谈起
NVIDIA国内热销H20显卡,TFLOPS达标,却声称能媲美A800/A100,究竟凭何底气?揭秘其背后的性能奥秘。
看下表:
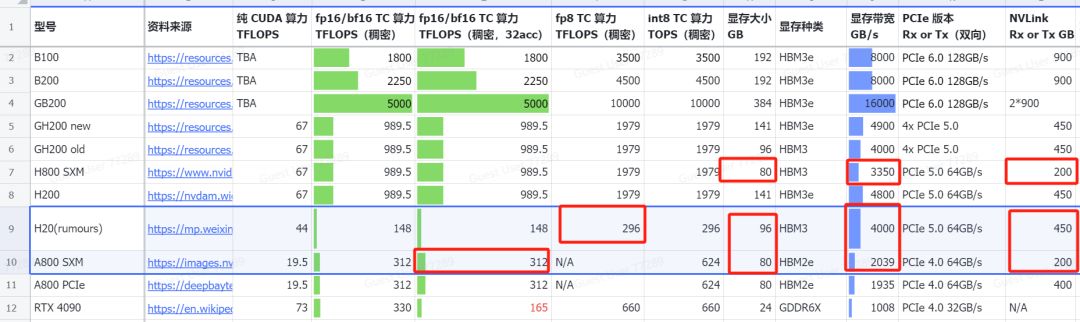
H20的FP16 TFLOPS为148,虽不及A800的312,但其在FP8 TFLOPS上表现优异,高达296,远超A800,因为A800并未设计FP8功能。
H20显存高达96G,远超A800的80G,其NVL速率更是A800的两倍多,显存带宽也近乎翻倍,性能卓越。
根据上一篇文章中的方法:
GPU算力评估-上
H20展现卓越性能,FP16峰值计算能力高达148Tflops,NVLink双向带宽达900GB/s。在H20配置中,最多可支持148个张量并行GPU,确保通信畅通无阻,满足高性能计算需求。
A800的FP16峰值计算能力高达312Tflops,NVLink双向带宽达400GB/s。在H20配置中,张量并行GPU数量可达31个,确保通信无阻,性能卓越。
但我们知道,一个H20服务器最多是8个卡。也就是说,相对于算力来说,NVL通讯量剩余。那么,训练中什么数值会影响NVL通讯量呢?影响大小分别为:MicroBS, gradient accumulate >TP>Global BS。也就是说,我们在训练的时候。如果NVL不是限制,可以增加MicroBS,MicroBS越大,训练步数越少,相对训练速度越快。但有个前提是不能出现内存溢出。而H20的显存比A800多20%。
也就是说,在相同的训练环境下,当GPU算力没有到上限前,增加BS,A800会先比H20出现OOM。但前面也提到了A800的FP16算力是H20的两倍多。但如果H20用FP8和A800的FP16比呢?是不是两者GPU算力就接近了,而H20的内存速率和NVL更高,BS就能更大些。
FP8在推理中的应用/FP8 in Inference
二、训练和推理对AI算力的要求
训练过程
训练过程需存储模型参数、梯度、优化器状态及每层中间状态,大幅增加内存需求。训练涉及正向与反向传播两阶段,确保模型学习效果的同时,对计算资源提出更高要求。
- 正向传播(Forward Pass):
- 反向传播(Backward Pass):
- 反向传播是训练核心,计算损失函数对参数的梯度并更新,涉及复杂矩阵运算与微分,是计算密集型任务,对计算性能要求极高。
- 存储需求:需要存储梯度和优化器状态,这些存储需求通常比模型参数本身更大。
- 通信需求:
- 梯度同步优化:数据并行时,各GPU独立计算梯度,再同步。这一流程虽高效但通信需求大,确保数据传输流畅成为关键。
- 模型并行显著提升了训练过程的算力需求,因正向与反向传播均需在GPU间传输数据与梯度,导致通信量激增。其中,梯度计算和参数更新作为计算密集型任务,成为训练的核心依赖。尽管通信带宽对梯度同步至关重要,但算力仍是训练过程中的关键因素。
推理过程
- 正向传播(Forward Pass):
- 推理主要依赖正向传播,计算量大但相对训练中的反向传播,算力需求较低,实现高效推理的关键在于优化正向传播计算。
- 推理过程简化存储需求:无需保留梯度和优化器状态,仅存储正向传播的激活值。因输入数据独立,各层中间状态无需持久化,极大降低存储压力,高效满足推理需求。
- 通信需求:
- KV Cache:
- 通过KV Cache缓存token的K和V矩阵,能大幅提升推理效率,无需重复计算。此策略虽增加存储需求,但显著减少计算量,实现内存与计算的高效交换,是优化推理性能的关键策略。
- KV Cache显著减少计算量,每字节存储大幅减轻计算负担。推理过程更侧重通信带宽,模型并行时GPU间数据交互频繁。尽管计算需求不高,但存储容量不可或缺,用于缓存中间结果与KV Cache,确保高效推理。
总结
- 训练过程高度依赖算力,因梯度计算和参数更新均为计算密集型任务。尽管通信带宽对梯度同步不可或缺,但算力需求仍为核心要素。
- 推理过程高度依赖通信带宽,特别是在模型并行时,GPU间数据传递频繁。虽然计算需求不高,但存储容量不可或缺,用于缓存中间结果和KV Cache,确保推理的高效进行。
在训练中,H20采用FP8而A800使用FP16,H20训练性能至少与A800相当。而在推理环节(H20支持8位推理),H20凭借更大的显存、更高的内存及NVL带宽,展现出更优越的性价比,超越A800。
三、KV cache都和什么有关
如前文所述,推理中会用到KV cache,那么KV cache都和什么有关?
KV Cache 是一种用于优化生成模型推理过程的技术。对于每个输入的 prompt,在计算第一个 token 的输出时,每个 token 的 attention 都需要从头计算。然而,在后续 token 的生成过程中,需要计算 self-attention,即输入 prompt 和前面生成的 token 的 attention。在这种情况下,需要用到前面每一个 token 的 Key(K)和 Value(V)矩阵。
由于每一层的参数矩阵是固定的,因此在生成新的 token 时,只有刚生成的那个 token 的 K 和 V 需要重新计算,而输入 prompt 和之前生成的 token 的 K 和 V 矩阵实际上是与上一轮相同的。因此,我们可以将每一层的 K 和 V 矩阵缓存起来,在生成下一个 token 时不再需要重新计算,这就是所谓的 KV Cache。需要注意的是,Query(Q)矩阵每次都不同,因此没有缓存的价值。
在训练过程中,选择性保存正向传播的中间状态(activations)是一种用计算换内存的策略,而 KV Cache 则是一种用内存换计算的策略。
KV Cache 的存储需求
KV Cache 的存储需求取决于以下几个因素:
- 层数(L):模型的层数。
- token 数量(T):需要缓存的 token 数量。
- 批量大小(B):批量大小,即一次处理的样本数量。
- 嵌入维度(D):模型的嵌入维度。
- 数据类型大小(S)决定了数值的存储效率,如float16占2字节,float32占4字节,精确选择以优化存储和性能。
- 模型的最大序列长度决定了每层KV Cache的存储容量。在LLaMA 2 70B模型中,若批量大小为8,token数达极限4096,80层的KV Cache总容量将基于嵌入维度、token数和批量大小计算得出。这一精细设计确保了模型在处理大规模数据时的高效性和准确性。
KV Cache空间计算为2(K,V) × 80 × 8192 × 4096 × 8 × 2B,总计达80GB。若增大batch size,KV Cache占用空间将超过参数本身的140GB,需留意资源分配。
KV Cache 的计算节约
计算K、V矩阵在每层涉及大量操作,总计为4倍(K, V)矩阵乘法与加法运算,乘以嵌入维度平方,即4 * 8192²。考虑输入的token数、层数和batch size,总计算量高达640 Tflops。这意味着每存储1字节,我们实际上节省了高达16K次计算,显著提升了效率与性能。
内存带宽的影响
计算 K 和 V 矩阵的过程是一个典型的内存密集型过程,需要加载每一层的 K 和 V 参数矩阵。如果不做任何缓存,假设 prompt 长度很短而输出长度接近 token 的最大长度 4096,到了最后一个 token 时,单是重复计算前面每个 token 的 K 和 V 矩阵,就需要读取内存:
4096 * 80 * 2 * 8192 * 8192 = 40T 次,每次 2 个字节,要知道 H100 的内存带宽只有 3.35 TB/s,4090 更是只有 1 TB/s,这单是最后一个 token 就得耗掉一张卡几十秒的时间来做重复计算。这样,token 的输出就会越来越慢,整个输出时间是输出长度平方级别的,根本没法用。通过使用 KV Cache,可以显著减少重复计算,提高推理效率。
关于序列长度对KV cache的影响,可以参照我此前文章。
Phi3+vLLM的验证:SLM系列3
TensorRT-LLM融合PagedAttention与FlashAttention,高效处理大模型,显著提升性能与效率。
四、长文本推理带来的挑战
长文本推理带来的挑战:
- 更大的 KV 缓存带来更大的内存访问需求
- 无法为生成阶段构建大型批处理。
- 生成请求延迟会受到上下文阶段的干扰更长的系统提示,大量冗余计算。
所以长文本推理优化主要需要解决KV cache带来的问题。
优化方法1:Streaming-LLM
- 滑动窗口注意力:只缓存最近的键值状态。当初始标记被驱逐时,模型会崩溃。
- 流式LLM创新地在滑动窗口注意力中引入“汇”标记,通过位置移动而非文本变动实现高效处理。图示直观对比了不同层、头注意力矩阵及密集、窗口注意力,并突出流式LLM在处理长输入时的卓越性能,通过图表清晰展现其优势。
优化方法2:Multi-Block-Mode
- 分割键/值:将键和值分割成更小的块。
- 并行计算:并行计算查询与每个分割块的注意力。
- 通过并行计算,将键和值分割为多个块,分别处理查询与每块的注意力。随后,运用对数和指数精细调整各块贡献,归约整合所有分割块,精准计算最终输出。
优化方法3:Inflight Batching
旨在优化大型语言模型的键值缓存(KV-Cache)。主要内容包括:
- 批处理后,优化计算效率的关键在于移除输入填充。此举显著提升键值缓存的利用率,进而强化大型语言模型的性能表现。
优化方法4:Chunked Context
- 传统IFB调度器:
- 单个标记需要与非常大的上下文输入一起批处理,导致生成延迟较大。
- 激活内存成本高。
- 用户体验受损。
- 启用分块上下文:
- 注意力计算因KV缓存的重复内存访问而复杂化。启用分块上下文后,通过批处理多个上下文块,显著提升性能,同时降低延迟。
- 上下文分块增加了批处理上下文和生成阶段的可能性,从而提高了性能。
- 对于第一个标记存在多重固有问题,带来了额外的开销。
优化方法5:KV-Cache-Reuse
- 全新输入序列现已划分为多个高效处理块,包括block1、block2、block3、block4及block5,提升数据处理效率。
- 推理引擎:推理引擎使用KV缓存来加速推理过程。
- 优化KV缓存机制:当键未匹配时,新KV缓存即被插入缓冲池并设索引,显著提升推理效率,实现资源高效重用。
优化方法6:使用FP8量化模型
- GPT-175B模型的性能分析:
- 对比了不同硬件配置下的上下文阶段和生成阶段的时间消耗。
- 重点关注了FP8和BFP16在不同批量大小下的性能差异。
- FP8 GEMM的优势:
- FP8 FMHA在性能上比FP16(BFP16)FMHA快2倍。
- FP8 FMHA在性能上比FP16(BFP16)FMHA快2倍。
- 性能数据:
- 表格中列出了不同批量大小下,FP8和BFP16的FMHA性能对比。
- FP8在多种批量规模下性能超越BFP16,尤其在GEMM和FMHA上表现卓越,显著领先于大型模型的推理与训练,性能优势显著。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











