







建表:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常
EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
LIKE 允许用户复制现有的表结构,但是不复制数据
EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
LIKE 允许用户复制现有的表结构,但是不复制数据
COMMENT可以为表与字段增加描述
ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
STORED AS
SEQUENCEFILE
| TEXTFILE
| RCFILE
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
1.创建内部表
mysql表TBLS表的TBL_TYPE为MANAGED_TABLE表示为内部表。
create table student(id bigint,name string) row format delimited fields terminated by '\t';
OK
Time taken: 0.079 seconds
hive> show tables;
OK
people
student
Time taken: 0.063 seconds, Fetched: 2 row(s)
hive>
2.将数据load到hdfs中
hive> load data local inpath '/hadoop/student.txt' into table student;
1 zhangsan
2 lisi
3 wangwu
2 lisi
3 wangwu
做数据的时候分隔符用Tab键进行分割,用空格不可以。
查看hdfs上的数据通过浏览器
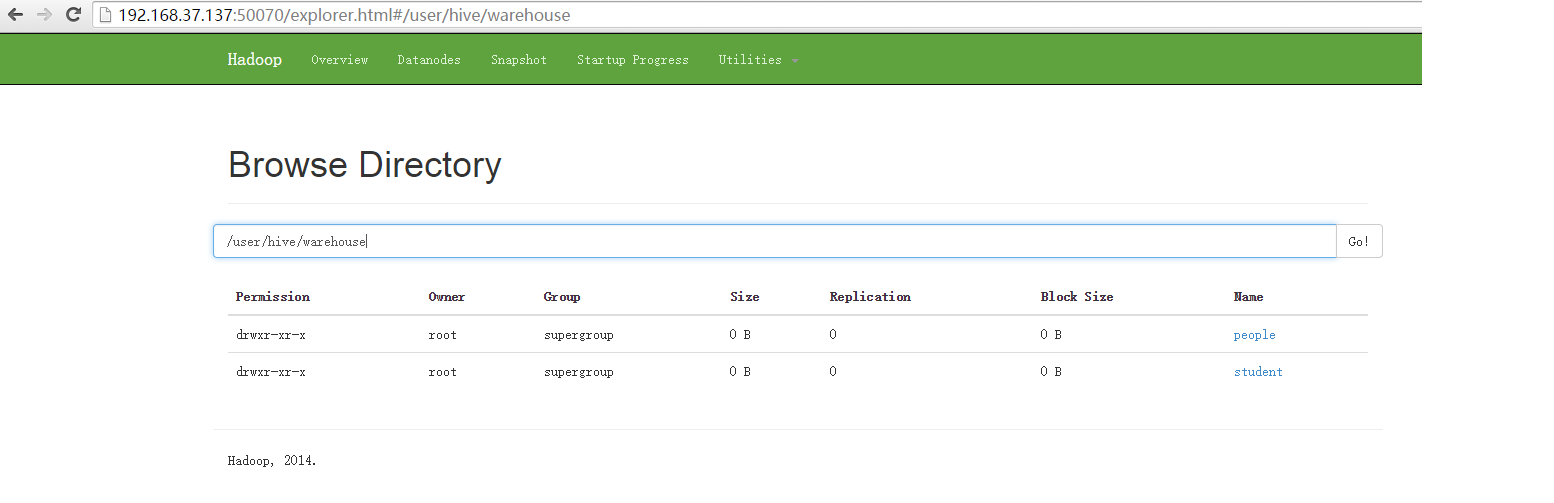
3.查询加载的数据
hive> select * from student;
OK
1 zhangsan
2 lisi
OK
1 zhangsan
2 lisi
3 wangwu
这个语句不会转换为mapreduc
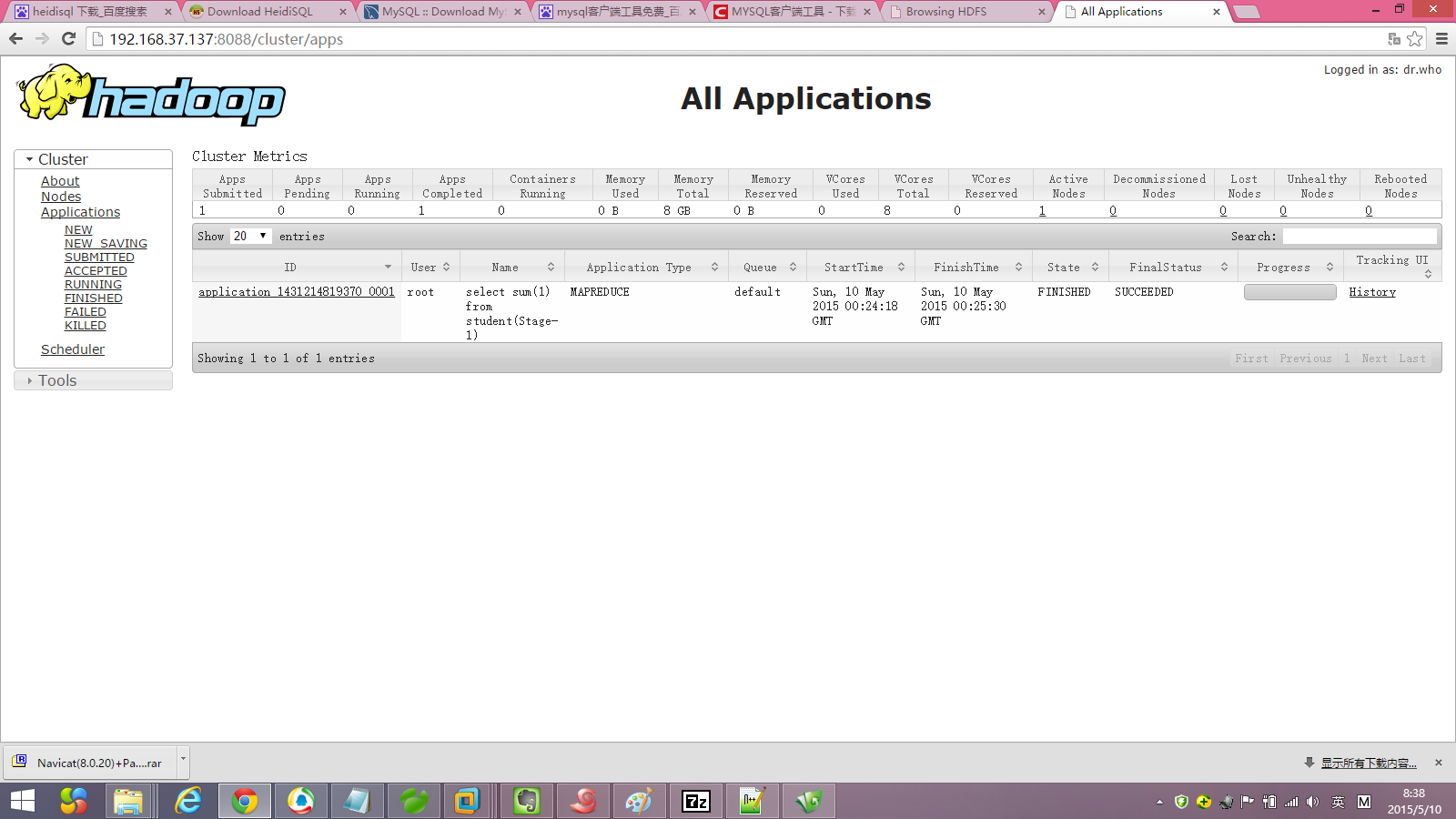
4.调用sum函数会转换为mapreducer.
hive> select sum(1) from student;
Query ID = root_20150509172424_64006457-afe3-489e-bcf3-df40a9f39882
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1431214819370_0001, Tracking URL = http://hadoop12:8088/proxy/application_1431214819370_0001/
Kill Command = /hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1431214819370_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2015-05-09 17:24:35,339 Stage-1 map = 0%, reduce = 0%
2015-05-09 17:25:08,401 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.76 sec
2015-05-09 17:25:28,906 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.49 sec
MapReduce Total cumulative CPU time: 2 seconds 490 msec
Ended Job = job_1431214819370_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.49 sec HDFS Read: 358 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 490 msec
OK
6
Time taken: 76.429 seconds, Fetched: 1 row(s)
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1431214819370_0001, Tracking URL = http://hadoop12:8088/proxy/application_1431214819370_0001/
Kill Command = /hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1431214819370_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2015-05-09 17:24:35,339 Stage-1 map = 0%, reduce = 0%
2015-05-09 17:25:08,401 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.76 sec
2015-05-09 17:25:28,906 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 2.49 sec
MapReduce Total cumulative CPU time: 2 seconds 490 msec
Ended Job = job_1431214819370_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 2.49 sec HDFS Read: 358 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 490 msec
OK
6
Time taken: 76.429 seconds, Fetched: 1 row(s)















 2049
2049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









