






 IoTDB是一个为物联网设计的时序数据库,解决传统数据库在处理时序数据时的不足,提供开放系统架构、灵活数据模型、高效存储和低延迟查询。它支持大规模数据存储和实时查询,适用于高采样率和多测点的复杂场景,如大型发电机组和核电监控。IoTDB还具有丰富的生态系统和学习资源。
IoTDB是一个为物联网设计的时序数据库,解决传统数据库在处理时序数据时的不足,提供开放系统架构、灵活数据模型、高效存储和低延迟查询。它支持大规模数据存储和实时查询,适用于高采样率和多测点的复杂场景,如大型发电机组和核电监控。IoTDB还具有丰富的生态系统和学习资源。
1. 简介
IoTDB(Internet of Things Database)是为物联网时序数据设计的集成数据管理引擎。它的目标是高效地存储、管理和查询大规模的时间序列数据。
什么是时序数据?
时序数据是指时间序列数据,是按时间顺序记录的数据列。工业物联网中,机器设备、传感器实时产生了海量时序数据,是工业数据的主体(占80%以上)。 工业物联网时序数据管理是工业互联网应用落地的基础。
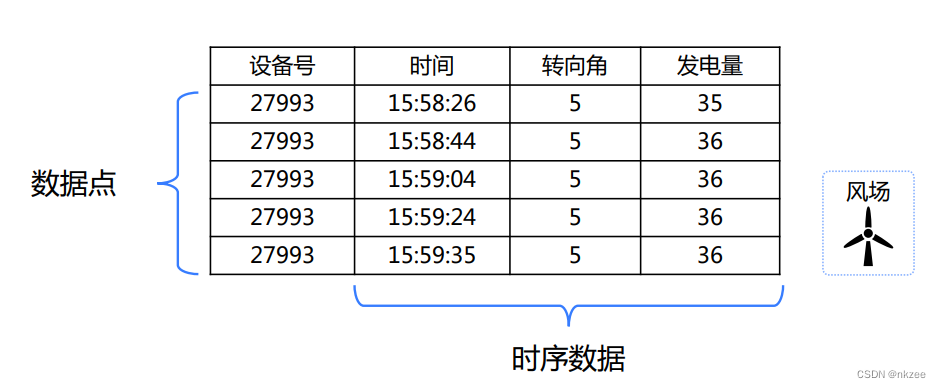
然而现有的数据库在处理时序数据时存在不足
关系数据库:无法存储海量数据
键值数据库:可管理海量数据,但是查询受限
基于关系数据库的时序数据库:写入吞吐速率和压缩比低,模型较固化,不利于系统升级
基于键值数据库的时序数据库:压缩机查询不友好,部署运维复杂
原生时序数据库:一些工业场景下性能下降
但是IoTDB可以有效地改善这些问题。
2. 特点与优势
- 灵活的数据模型:IoTDB支持灵活的数据模型,可以存储各种类型的时间序列数据,并提供灵活的数据查询接口
- 可扩展性:IoTDB具有良好的可扩展性,可以在集群环境中实现水平扩展,以应对大规模的数据存储需求。
- 高效存储引擎:IoTDB支持对齐和非对齐序列存储,允许数据乱序写入、覆盖、删除,每秒千万点吞吐,让写入更高效。

- 低延迟查询:IoTDB通过预聚合和时序索引支持快速数据过滤、高效聚合查询、降采样查询等典型时序数据查询种类,让查询更快速。
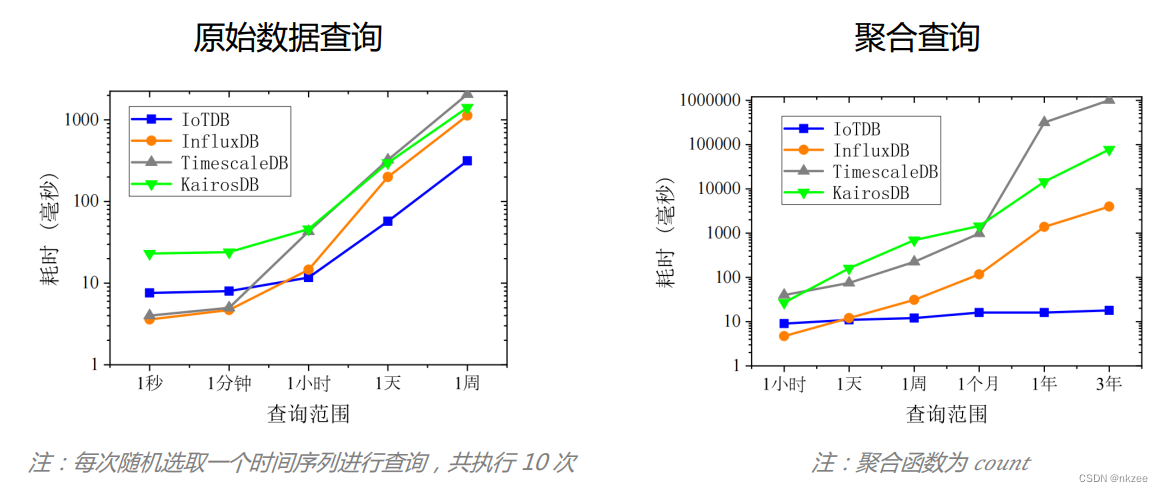
- 高性能:IoTDB采用了多种性能优化技术,包括多级索引、压缩算法和数据层次化存储结构,以提供高效的数据写入和查询性能。TsFile便是IoTDB针对时间序列优化的紧致列式存储文件格式, 并支持有损、无损等多种高效编码及专有压缩算法,无损压缩达 10 倍,有损压缩达 100 倍。
下面将对IoTDB的数据模型以及数据操作进行简单的展开说明
数据模型
IoTDB利用其发明的元数据自动识别技术,实现了专属树形时序数据模型,其中的数据被组织成一系列的时间序列。每个时间序列由以下属性定义:
- 时间戳:表示数据点的时间。
- 设备:标识产生数据的设备。
- 测量标签:表示数据的类型或者名称。
- 数值:实际的数据值。
树型时序模型与物联网场景实际设备结构一一映射,可达到多级身背直观管理、从属链路清晰,轻松锁定需要的数据。
数据操作
IoTDB提供了多种数据操作接口,包括:
- 写入数据:可以使用SQL语句或API将数据写入IoTDB。可以一次写入多个时间序列的数据点。
- 查询数据:可以使用SQL查询语句或API对时间序列数据进行灵活的查询,支持范围查询、聚合操作和过滤条件等功能。
- 删除数据:可以根据条件删除时间序列数据。
- 更新数据:可以更新已存在的时间序列数据点的数值。
3. 部署
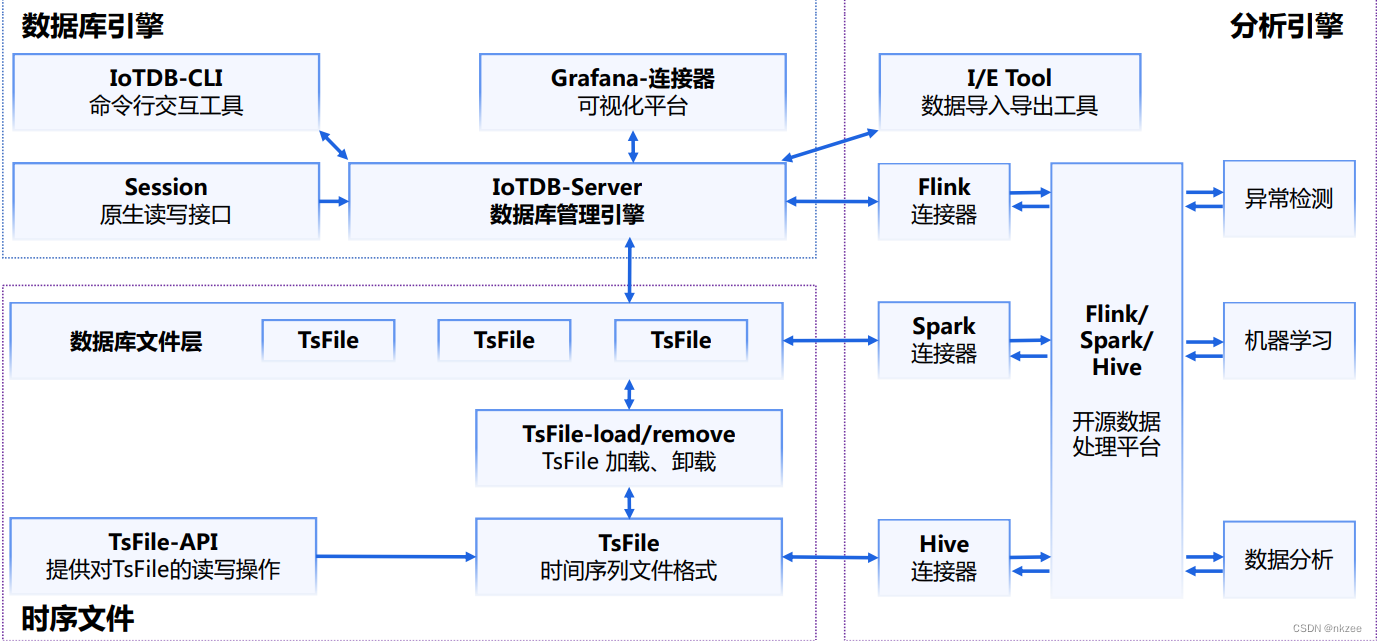
IoTDB 可以在单机或集群、边缘环境中进行部署,并且拥有丰富的生态,可以与PLC4X、Pulsar、Flink、Spark、Grafana、Zeppelin等大数据系统集成,覆盖时序数据的采集、处理、存储、分析、可视化等全生命周期。 同时IoTDB还方便迁移,其兼容多种 TSDB 接口,包括InfluxDB、Prometheus、KairosDB。在这些基础上通过结合其他技术,如流式处理、实时分析和可视化工具,可以构建强大的物联网数据处理和分析平台。
4. 优势场景
那么IoTDB在实际应用场景中会有哪些优势显现呢?
复杂写入负载:设备测点数海量
如大型发电机组,可达数万时间序列

普通的关系型数据库无法进行便捷存储,达到存储上限。如MySQL InnoDB 为1017列,至多存储1017时间序列,无法满足要求。
但IoTDB可容纳的时间序列数量无上限,满足拥有超多测点的高端装备的管理需求。
复杂写入负载:采样频率高
如核电监控,数据采集频率可达 25000Hz

普通的关系型数据库易达到1000万行的单表存储上限。水平分表分库等方案造成额外工作量且运维复杂。
而IoTDB可以容纳PB级别数据。且数据写入、数据查询速率不随数据量增长而下降,维持稳定高速水平。
复杂写入负载:各数据独立采集
如汽车传感器
网络延迟等生产环境问题造成不同设备数据采集时钟不同步,难以对齐分析。且数据缺失,影响可视化/化/分析。
而IoTDB支持时间序列数据按时间对齐、空值填充.
5. 学习资源
IoTDB作为一个开源项目,也提供了完整的学习教程
- 官方文档:可以从IoTDB官方网站获取详细的文档和教程,了解IoTDB的安装、配置和使用方法。http://iotdb.apache.org/
- 代码:如果想要进一步了解IoTDB的代码构成,可以前往代码仓库https://github.com/apache/iotdb/tree/master
- 社区支持:可以参加IoTDB的官方论坛或社区,与其他用户交流经验和解决问题。

















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









