







1.BeautifulSoup4库
和lxml一样,Beautiful Soup也是一个HTML/XML的解析器主要的功能也是解析和接收HTML/XML数据。
lxml只会局部遍历,而BeautifulSoup是基于HTML DOM(Document Object Model)的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup用来解析HTML比较简单,API非常人性化,支持CSS选择器,Python标准库中的HTML解析器,也支持lxml的XML解析器。
BeautifulSoup3目前已经停止开发,推荐现在的项目使用BeautifulSoup4。
2.安装和文档:
1.安装:pip install bs4
2.中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
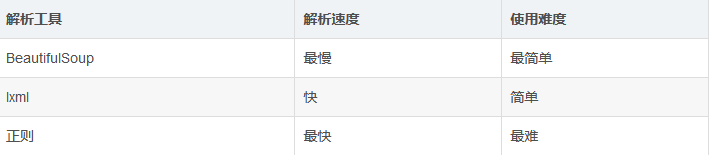
3.几大解析解析工具对比

4.简单使用
from bs4 import BeautifulSoup
html="""
"""
bs=BeautifulSoup(html,"lxml")
print(bs.prettify())
5.bs4库提取数据详解
from bs4 import BeautifulSoup
html="""
"""
# 1. 获取所有tr标签
# 2. 获取第2个tr标签
# 3. 获取所有class 等于 even 的tr标签
# 4. 将所有id等于test,class也等于test的a标签提取出来
# 5. 获取所有a标签的href属性
# 6. 获取所有的职位信息(文本)
soup=BeautifulSoup(html,"lxml")
# 1. 获取所有tr标签
trs=soup.find_all('tr')
for tr in trs:
print(tr)
print(type(tr))
# 2. 获取第2个tr标签
tr=soup.find_all('tr',limit=2)[1]
print(tr)
# 3. 获取所有class 等于 even 的tr标签
trs=soup.find_all('tr',class_='even')
#另一种:trs=soup.find_all('tr',attrs={'class':'even'})
for tr in trs:
print(tr)
# 4. 将所有id等于test,class也等于test的a标签提取出来
alist=soup.find_all('a',id='test',class_='test')
#alist=soup.find_all('a',attrs={'id':'test','class':'test'})
for tr in trs:
print(tr)
# 5. 获取所有a标签的href属性
alist=soup.find_all('a')
for a in alist:
# 1. 通过下表操作的方式
href=a['href']
print(href)
# 2. 通过attrs属性的方式
href=a.attrs['href']
print(href)
# 6. 获取所有的职位信息(文本)
trs=soup.find_all('tr')[1:]
movies=[]
for tr in trs:
movie={}
# tds=tr.find_all('td')
# title=tid[0].string
# category=tds[1].string
# nums=tds[2].string
# city = tds[3].string
# pubtime = tds[4].string
# movie['title']=title
# movie['category']=category
# movie['nums']=nums
# movie['city']=city
# movie['pubtime']=pubtime
# movies.append(movie)
#tr.strings可以提取所有非标签性的字符串提取出来
infos=list(tr.stripped_strings)
movie['title']=infos[0]
movie['category'] = infos[1]
movie['nums'] = infos[2]
movie['city'] = infos[3]
movie['pubtime'] = infos[4]
movies.append(movie)
for info in infos:
print(info)
for movie in movies:
print(movie)笔记:
find_all的使用:
在提取标签的时候,第一个参数是标签的名字。然后如果在提取标签的时候想要使用标签属性进行过滤,那么可以在这个方法中通过关键字参数的形式,将属性的名字以及对应的值传进去。或者使用"attrs"属性,将所有的属性以及对应的值放在一个字典中传给"attrs"属性。
有些时候,在提取标签时,不想提取那么多,那么可以使用"limit"参数,限制提取多少个
find_all和find的区别:
find:找到第一个满足标签的条件就返回,就是返回第一个元素
find_all:将所有满足条件的标签都返回(以列表的形式)
使用find和find_all的过滤条件:
1. 关键字参数:将属性的名字作为关键字参数的名字,以及属性的值作为关键字参数的值进行过滤。
2. attrs参数:讲属性条件放到一个字典中,传给attrs参数
获取标签的属性:
1.通过下标获取:通过标签的下标的方式。
href=a['href']2.通过attrs属性获取:
href=a.attrs['href']
strings和stripped——strings、string属性以及get_text方法
1.string:获取某个标签下的非标签字符串,返回来的十个字符串。
2.strings:获取某个标签下的子孙非标签字符串,返回来的是个生成器。
3.stripped_string:获取某个标签下的子孙非标签字符串,会去掉空白字符,返回来的是个生成器。
4.get_text:获取某个标签的子孙非标签字符串,不是以列表的形式返回,是以普通字符串返回。
6.select方法
css选择器
使用以上方法可以方便的找出元素。但有时候使用css选择器的方式可以更加的方便。使用css选择器的语法,应该使用select方法。以下列出几种常用的css选择器方法:
(1)通过标签名查找:
print(soup.select('a'))(2)通过类名查找:
通过类名,则应该在类的前面加一个.。比如要查找class=sister的标签。示例代码如下:
print(soup.select('.sister'))(3)通过id查找:
通过id查找,应该在id的名字前面加一个#号。示例代码如下:
print(soup.select("#link1"))(4)组合查找:
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开:
print(soup.select("p #link1"))直接子标签查找,则使用 > 分隔:
print(soup.select("head > title"))(5)通过属性查找:
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。示例代码如下:
print(soup.select('a[href="http://example.com/elsie"]'))(6)获取内容
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出,然后用 get_text() 方法来获取它的内容。
soup = BeautifulSoup(html, 'lxml')
print type(soup.select('title'))
print soup.select('title')[0].get_text()
for title in soup.select('title'):
print title.get_text()7.select和css选择器提取元素
from bs4 import BeautifulSoup
html="""
"""
# 1. 获取所有tr标签
# 2. 获取第2个tr标签
# 3. 获取所有class 等于 even 的tr标签
# 4. 将所有id等于test,class也等于test的a标签提取出来
# 5. 获取所有a标签的href属性
# 6. 获取所有的职位信息(文本)
soup=BeautifulSoup(html,"lxml")
# 1. 获取所有tr标签
soup.select('tr')
# 2. 获取第2个tr标签
soup.select('tr')[1]
# 3. 获取所有class 等于 even 的tr标签
soup.select('tr[class=="even"]')
# 4. 将所有id等于test,class也等于test的a标签提取出来
css选择器无法实现该需求
# 5. 获取所有a标签的href属性
alist=soup.select('a')
for a in alist:
href=a['href']
# 6. 获取所有的职位信息(文本)
trs=soup.select('tr')
for tr in trs:
infos=list(tr.stripped_strings)
print(infos)
8.4个常用的对象
BeautifulSoup 将复杂HTML文档转化为一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种
(1) Tag:BeautifulSoup中所有的标签都是Tag类型,并且BeautifulSoup的对象其实本质上也是一个Tag类型,所以其实一些方法比如find,find_all并不是BeautifulSoup的,而是Tag的。
(2) NavigatableString:继承自python中的str。用起来就和使用python中的str一样
(3) BeautifulSoup:继承自Tag,用来生成BeautifulSoup树的。对于一些查找方法,比如select,find这些其实还是Tag的。
(4) Comment:继承自NavigatableString
contents和children:
返回某个标签下的直接子元素,其中也包括字符串。他们两的区别是:contents返回来的是一个列表,children返回的是一个迭代器。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









