







这篇博客被推迟了五天,并不是没有时间去学习,而是最近学习的东西都比较简单,没有什么特别有意义的东西,所以一直没写。但是听了领导一些话,突然觉得,既然决定了,就没有理由去退缩,就算再简单的东西,也要去做,因为坚持比做好更难。好了,下面直接步入主题,详解本次的内容。
1.HashCode
hashCode中文叫散列码,这个方法是定义在Object中的,是个native方法,关于其是不是默认返回对象物理地址可看该博文,这里我不多解释,主要说下hashCode在HashMap的用处和推荐的重写规则。
- 在HashMap的意义
相信大家都知道HashMap为什么查找的速度为什么那么快吧(O(1)),就是用到了散列技术,散列的存在就是为了速度。key的hashCode值和hashMap
的容量共同决定了链表所在数组(hashmap底层就是数组+链表实现的
)的位置,但是当hashCode冲突严重时,就是导致链表的线性访问很浪费时间,所以在重写hashCode时需要遵循一些原则。 - 重写的推荐规则
1.一致性:对象在未发生改变的情况下,hashCode值应该保持一致。
2.当两个对象equals为真的时候,hashCode值必须一致。
3.在Effective Java Programming Language Guide一书中的基本指导
3.1 给int变量result赋予某个非0的值
3.2为对象每个有意义的域f计算出一个int散列码k
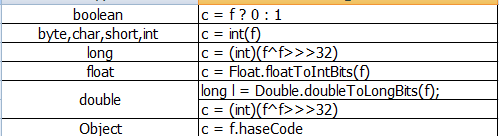
3.3合并计算得到的散列码:result = 37 * result + c;
3.4返回result
public class OverrideHashCode {
String name;
long lid;
int id;
public OverrideHashCode(String name, long lid, int id) {
super();
this.name = name;
this.lid = lid;
this.id = id;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
result = prime * result + (int) (lid ^ (lid >>> 32));
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
public static void main(String[] args) {
for(int i = 0;i < 10 ;i++) {
OverrideHashCode overrideHashCode = new OverrideHashCode("a", i >> 10, i);
System.out.println(overrideHashCode.hashCode());
System.out.println(overrideHashCode.hashCode());
}
}
}
2.equals
重写equals需要遵循五个原则:
1.自反性:对任意非空x,x.equals(x)一定返回true
2.对称性:对任意x和y,如果x.equals(y)为true,则y.equals(x)也为true
3.传递性:对于x,y,z,如果有x.equals(y)为true,y.equasl(z)为true,则x.equals(y)则必须业务true。
4.一致性:对任意x和y,如果x和y的等价比较信息没有改变,无论进行多少次x.equals(y)的结果应该保持一致,要么一直未true,要么一直为false
5.非空性:对于任何非空x.equals(null)时一定返回false。
3.总结
hashcode和equals多用于集合,尤其在使用set时,由于是不能重复的集合,所以必须正确的覆盖hashCode和equals,否则就会出现错误














 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









