









1. xml解析
1.1 DOM解析
xml解析器解析xml文档时,会把xml文件的各个部门内容封装成对象,并通过对象来操作xml文档,这种方式就称为DOM解析。
1.1.1 读取xml文件
参考以下students.xml文件:
<?xml version="1.0" encoding="utf-8"?>
<students>
<student id="001">
<name>xpeng_V</name>
<gender>M</gender>
<age>100</age>
</student>
<student id="002">
<name>xiaohong</name>
<gender>F</gender>
<age>22</age>
</student>
</students>
我们可以将上述xml文件想象成如下的DOM树型结构
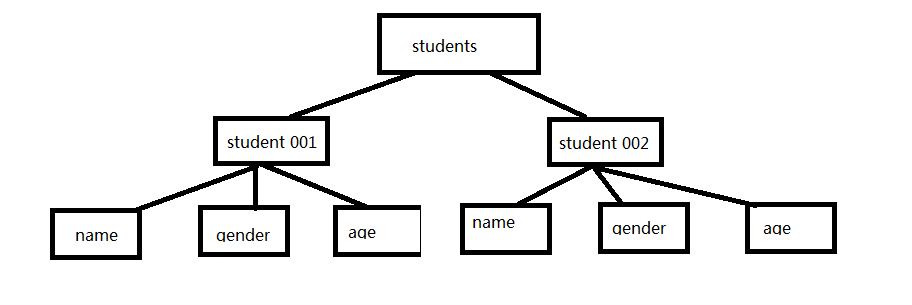
- 将上述树形结构称为Document树,树只有一个根标签(students)
- 树上的分支,即节点为Node对象
- 标签节点封装为Element对象
- 属性节点封装为Attribute对象
- 文本内容封装为Text对象
使用DOM解析xml文件,我们可以得到一个Document对象,通过Document对象就可以了得到xml文档里的分支,标签,属性和文本信息。
1.1.1.1 获取标签
新建工程并导入dom4j-1.6.1.jar,编写以下代码解析xml文件得到所有的标签:
public class Demo2 {
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("./src/students.xml"));
//得到根标签
Element root = document.getRootElement();
getChildNodes(root);
}
//获取传入标签的所有子节点
private static void getChildNodes(Element e){
System.out.println(e.getName());
//得到子节点
Iterator<Node> it = e.nodeIterator();
while(it.hasNext()){
Node node = it.next();
//判断是否为标签节点
if(node instanceof Element){
Element e1 = (Element)node;
//递归
getChildNodes(e1);
}
}
}
}控制台输出如下:
students
student
name
gender
age
student
name
gender
age
1.1.1.2 获取属性值
- 首先得到标签对象,然后使用attributeValue(“属性名”)得到属性的值
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("./src/students.xml"));
//获取标签对象
Element e = document.getRootElement().element("student");
//得到标签的属性
String id = e.attributeValue("id");
System.out.println(id);
}- 通过e.attribute(“属性名”)得到属性对象,然后再得到属性的值
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("./src/students.xml"));
//获取标签对象
Element e = document.getRootElement().element("student");
//得到属性对象
Attribute attr = e.attribute("id");
System.out.println(attr.getName() + attr.getValue());
}- *当不知道标签里的属性的名字和属性的个数时
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("./src/students.xml"));
//获取标签对象
Element e = document.getRootElement().element("student");
//返回List
List<Attribute> list = e.attributes();
for (Attribute attr : list) {
System.out.println(attr.getName() + attr.getValue());
}
//返回Iterator
Iterator<Attribute> it = e.attributeIterator();
while(it.hasNext()){
Attribute attr = it.next();
System.out.println(attr.getName() + attr.getValue());
}
}1.1.1.3 获取文本
获取指定子标签中的文本
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("./src/students.xml"));
//获取指定子标签中的文本
String str = document.getRootElement().element("student").elementText("name");
System.out.println(str);
}注意:空格和换行也是xml文件中的文本,我们可以使用以下代码得到根标签里的文本
String content = document.getRootElement().getText();我们能够发现下面两段xml具有不一样的含义
<name>
AA
</name><name>AA</name>1.1.2 修改和新建
以下代码作用是将students.xml文件拷贝到E盘根目录。
1. 使用xml解析器SAXReader将文件解析为Document 对象
2. 创建输出流
3. 使用XMLWriter 从计算机内存中读取Document 对象
4. 使用write方法将内存中的对象写到硬盘中
5. 关闭流
/**
*
* @author xpeng_V
*
*/
public class UpdateXml {
public static void main(String[] args) throws Exception {
//读取xml文件
Document doc = new SAXReader().read(new File("./src/students.xml"));
//创建输出对象
FileOutputStream out = new FileOutputStream("E:/students.xml");
//写出对象
//OutputFormat format = OutputFormat.createCompactFormat();
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK");
XMLWriter xmlWriter = new XMLWriter(out, format);
xmlWriter.write(doc);
//关闭流
out.close();
}
}XMLWriter 类:
XMLWriter 的构造方法:
//OutputFormat format = OutputFormat.createCompactFormat();
//OutputFormat format = OutputFormat.createPrettyPrint();
XMLWriter xmlWriter = new XMLWriter(OutputStream out, OutputFormat format)其中createCompactFormat会去掉xml文件出声明之外的空格和换行,createPrettyPrint会显示空格和换行。注意这两种方式生成的xml文档是不同的。因为第一种方式有空格和换行所以会占据较大的空间,所以在适当的时候选择对应的格式。
format.setEncoding(“utf-9”) 同时设置了xml文件声明的编码和文件保存的编码。















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









