







文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、小tips(c/c++)
1.scanf与cin的使用
输入与输出的使用细节:cin的速度比scanf要慢不少(即便关了同步),1e5以上的数据使用cin读入可能就会导致TLE;输入建议使用scanf;
scanf(“%s”)可以过滤空格和回车
输出建议使用printf,因为好控制精度;
TLE:Time Limit Exceeded(超时);
cout输出小数(fixed:保存;setprecision:精度; right:右对齐)
#include <iomanip>
float n=0.243;
float k=0.244543;
cout<<setiosflags(ios::fixed)<<setiosflags(ios::right)<<setprecision(2)<<n<<" "<<k<<endl;
//输出右对齐且小数点保留后两位的浮点数。
最后:
//简单理解一下写法
//C语言中,EOF常被作为文件结束的标志,常被用来判断调用一个函数是否成功,EOF(end of file)值通常为-1;
//scanf("%d%d", &a, &b);
//如果a和b都被成功读入,那么scanf的返回值就是2;如果只有a被成功读入,返回值为1;
//如果a和b都未被成功读入,返回值为0;如果遇到错误或遇到end of file,返回值为EOF,且返回值为int型。
while(scanf("%d",&n) != EOF){
cout<<n<<endl;
}
//等价于
while(cin>>n){
cout<<n<<endl;
}
2.构造函数
结构体中可以加入与结构体同名无返回值的构造函数。
在创建结构体时会自动调用该构造函数;
#include <iostream>
using namespace std;
typedef struct node{
int a;
node(int A=0){
a=A;
}
}Node;
int main()
{
Node i1= node(); //无输入则输入默认参数 A=0;
Node i2= Node(3);
cout<<i1.a<<endl;
cout<<i2.a<<endl;
//i1.a 为 0
//i2.a 为 3
return 0;
}
二、常用C++/C标准库
1.引入库–C
常用库–#include <string.h>
memset:将a数组中的值清空/替换;
strlen:获取字符串的长度;
#include <stdio.h>
#include <string.h>
int main ()
{
char str[50];
int len;
strcpy(str, "This is");
memset(str,'x',7);
len = strlen(str);
printf("%s 的长度是 %d\n", str, len);
return(0);
}
/// 运行结果:xxxxxxx的长度是7
库–#include <time.h>
代码运行时间计算:单位(ms)
#include <time.h>
#include <stdio.h>
clock_t star,stop;
double duration;
int a[100];
int n=1;
int x=10;
void myfunction(int a[],int n,int x)
{
int k;
k=n+x;
a[k]=k;
}
int main()
{
star=clock();
for(int i=0;i<6666666;i++)
{
myfunction(a,n,x);
}
stop=clock();
duration=((double)(stop-star))/CLK_TCK/6666666; //为什么函数要运行6666666次
//因为如果函数运行时间很短那么stop=star(计数器值相同).
//所以让函数多运行几次然后除以运行次数得一次的时间
printf("%.10f\n", duration);
}
//其实这个用的不多
2.引入库–C++
STL–标准模板库 (Standard Template Library)
1.vector(向量)
向量(vector)是一个能够存放任意类型的大小动态的数组。
向量名.end为得到数组的最后一个单元+1的指针
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> add;
/// vector<int>::iterator p; 指针定义方法
int main()
{
//在数组的最后添加一个数据
for(int i=0;i<100;i++)
{
add.push_back(i);
}
//在数组的最后删除一个数据
for(int i=0;i<10;i++)
{
add.pop_back();
}
add.erase(add.begin(),add.begin()+10);//删除10个add中的数据项 左闭右开
add.push_back(89); //弄一个重复元素
sort(add.begin(), add.end()); //排序
//sort()的数组的第一个元素的指针,end为指向待sort()的数组的最后一个元素的下一个位置的指针
add.erase(unique(add.begin(), add.end()),add.end()); //去除重复元素
//unique(add.begin(), add.end()) 将不重复元素排好//返回一个地址该地址为数组的最后一个不重复元素的后一位
//vector<int>::iterator unique(vector<int> &a) {
// int j = 0;
// for (int i = 0; i < a.size(); ++i) {
// if (!i || a[i] != a[i - 1])//如果是第一个元素或者该元素不等于前一个元素,
//即不重复元素,我们就把它存到数组前j个元素中
// a[j++] = a[i];//每存在一个不同元素,j++
// }
// return a.begin() + j;//返回的是前j个不重复元素的下标
//}
//打印数组
for (int i=0;i<add.size();i++)
{
cout<<add[i]<<" ";
}
// 另一种打印方式 (利用指针)
cout<<endl;
for (vector<int>:: iterator p=add.begin();p!=add.end();p++)
{
cout<<*p<<" ";
}
return 0;
}
其他:

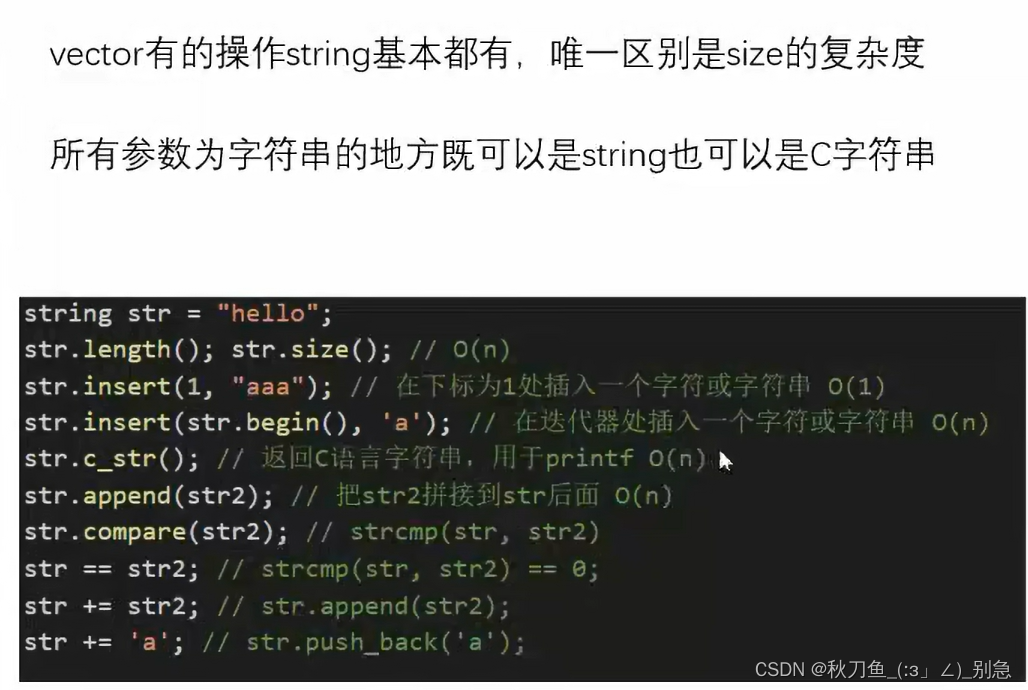
2.string
3.algorithm
sort:sort()函数可以自定义排序准则,以便满足不同的排序情况。使用sort()我们不仅仅可以从大到小排或者从小到大排,还可以按照一定的准则进行排序。比如说我们按照每个数的个位进行从大到小排序,我们就可以根据自己的需求来写一个函数作为排序的准则传入到sort()中
//从小到大
int a[6]={1,2,3,4,5,0};
sort(a,a+6);
for(int i=0;i<6;i++)
cout<<a[i]<<endl;
cout<<endl;
//从大到小
sort(a,a+6,greater<int>());
for(int i=0;i<6;i++)
cout<<a[i]<<endl;
// 按照每个数的个位进行从大到小排序
bool cmp(int x,int y){
return x % 10 > y % 10;
}
sort(num,num+10,cmp);
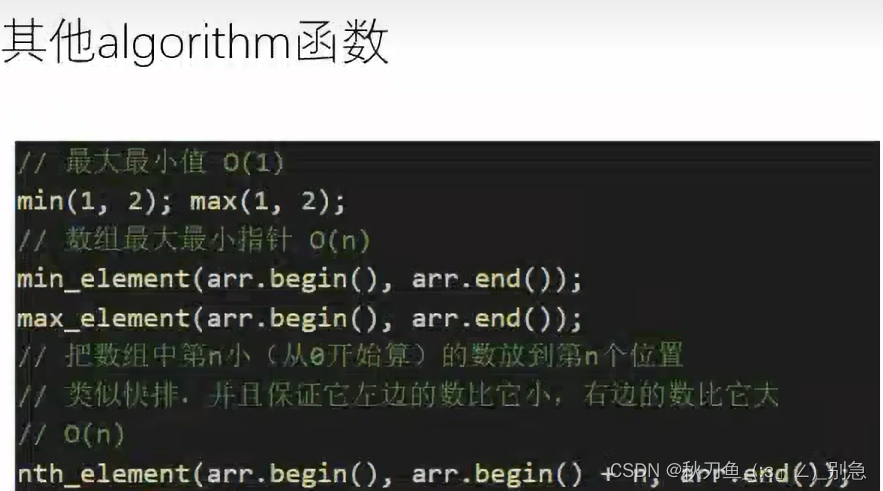
nth_element:将arr.begin()+n位置的数固定,数左边放比他小的数,右边放比他大的;
PS:注意指针的加减
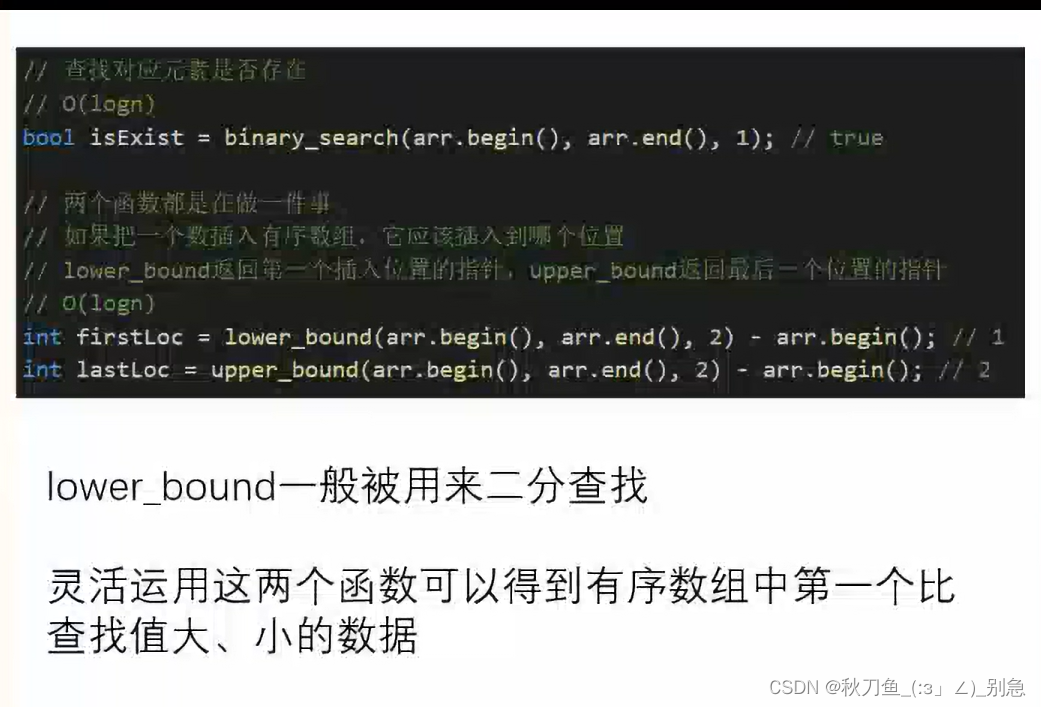
PS:注意指针的加减(firstLoc lastLoc)
lower_bound:往低位插入数值;
upper_bound:往高位插入数值;
















 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











