







服务器ip、hostname等参数见博文[Hadoop]hadoop2.2安装(1)——安装准备
1、准备
三台机子都做如下准备:
1.1设置hostname(以namenode机子为例)
- 修改/etc/sysconfig/network
NETWORKING=yes
#HOSTNAME=centos6-FTP
HOSTNAME=sparkMaster
- 修改/etc/hosts文件,增加三台机子的ip和hostname的映射。注意,127.0.0.1不要对应hostname。
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.11.11.18 sparkMaster
10.11.11.2 sparkWorker01
10.11.11.4 sparkWorker02

1.2 关闭防火墙
service iptables stop //关闭防火墙
chkconfigiptables off //永久关闭防火墙
1.3安装ssh和rsync
yum install ssh
yum install rsync
1.4 设置ssh无密码登陆
(1)在三台机子上分别执行如下命令:
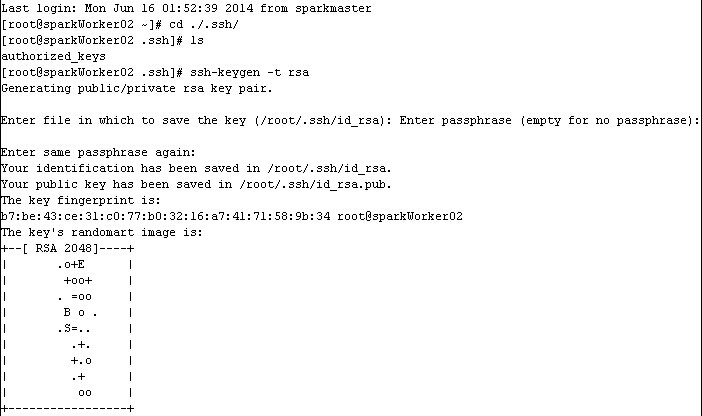
(2)在sparkMaster机子上执行如下命令,实现无密码登陆本机
cd ./.ssh
cp id_rsa.pub authorized_keys
(3)将另两台datanode节点的id_rsa.pub的内容添加到sparkMaster机子的authorized_keys文件里,使该文件拥有三台机子的ssh信息。

(4)将sparkMaster上的authorized_keys文件拷贝到sparkWorker01和sparkWorker02两台worker节点上。

这样就可以做到相互无密码登陆。
三台机子都作如下操作:
- 下载Hadoop2.2,hadoop-2.2.0.tar.gzhttp://mirror.cc.columbia.edu/pub/software/apache/hadoop/common/stable2/
- 解压hadoop-2.2.0.tar.gz:
将hadoop压缩文件上传到所有机器上,然后解压。注意:所有机器的hadoop路径必须一致,因为master会登录到slave上执行命令,master认为slave的hadoop路径与自己一样。
tar -xzf hadoop-2.2.0.tar.gz
1.6 设置环境变量(三台机子都一样)
vi /etc/profile
HADOOP_HOME=/opt/hadoop-2.2.0/
HADOOP_MAPRED_HOME=$HADOOP_HOME
HADOOP_COMMON_HOME=$HADOOP_HOME
HADOOP_HDFS_HOME=$HADOOP_HOME
YARN_HOME=$HADOOP_HOME
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
source /etc/profile
注:要加上最后两行,否则启动服务时,会报错:
Starting namenodes on [JavaHotSpot(TM) 64-Bit Server VM warning: You have loaded library/opt/hadoop-2.2.0/lib/native/libhadoop.so.1.0.0 which might have disabled stackguard. The VM will try to fix the stack guard now.
1.7 配置
- 编辑hadoop-2.2.0/etc/hadoop/hadoop-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME= /usr/java/jdk1.7.0_60
三台机子配置一样,将该配置远程拷贝到另两台机子上
scp hadoop-env.sh root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp hadoop-env.sh root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
- 编辑hadoop-2.2.0/etc/hadoop/yarn-env.sh
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME= /usr/java/jdk1.7.0_60
scp yarn-env.sh root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp yarn-env.sh root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
- 添加slave节点
vi hadoop-2.2.0/etc/hadoop/slaves
#localhost
sparkWorker01
sparkWorker02
scp slaves root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp slaves root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
- 编辑或者创建hadoop-2.2.0/etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
scp mapred -site.xml root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp mapred -site.xml root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
- 编辑hadoop-2.2.0/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/yarnDir/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/yarnDir/datanode</value>
</property>
</configuration>
scp hdfs-site.xml root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp hdfs-site.xml root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
- 编辑hadoop-2.2.0/etc/hadoop/core-site.xml,指定NameNode
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://sparkMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/yarnDir/tmp </value>
</property>
<property>
<name>hadoop.proxyuser.hduser.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hduser.groups</name>
<value>*</value>
</property>
</configuration>
scp core-site.xml root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp core-site.xml root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sparkMaster</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>sparkMaster:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sparkMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sparkMaster:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sparkMaster:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sparkMaster:8088</value>
</property>
</configuration>
scp yarn-site.xml root@10.11.11.2:/opt/hadoop-2.2.0/etc/hadoop/
scp yarn-site.xml root@10.11.11.4:/opt/hadoop-2.2.0/etc/hadoop/
1.8 启动
- 格式化namenode
在sparkMaster机子上执行下列命令:
hadoop-2.2.0/bin/hadoopnamenode –format
-启动服务
在sparkMaster机子上启动服务
hadoop-2.2.0/sbin/start-all.sh
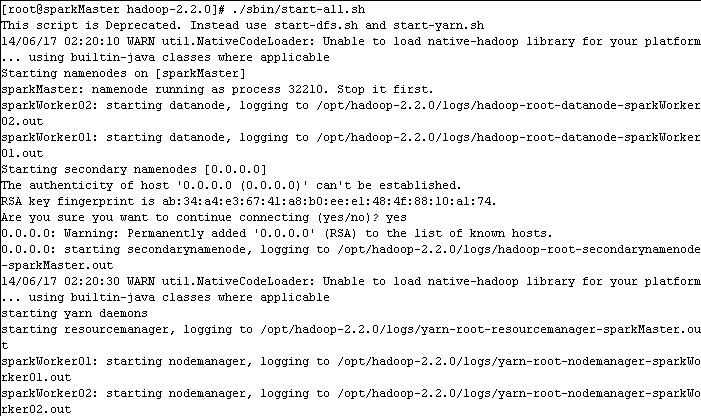
1.9 检测
- 查看运行的hadoop进程 jps
sparkMaster:

sparkWorker01和sparkWorker02:

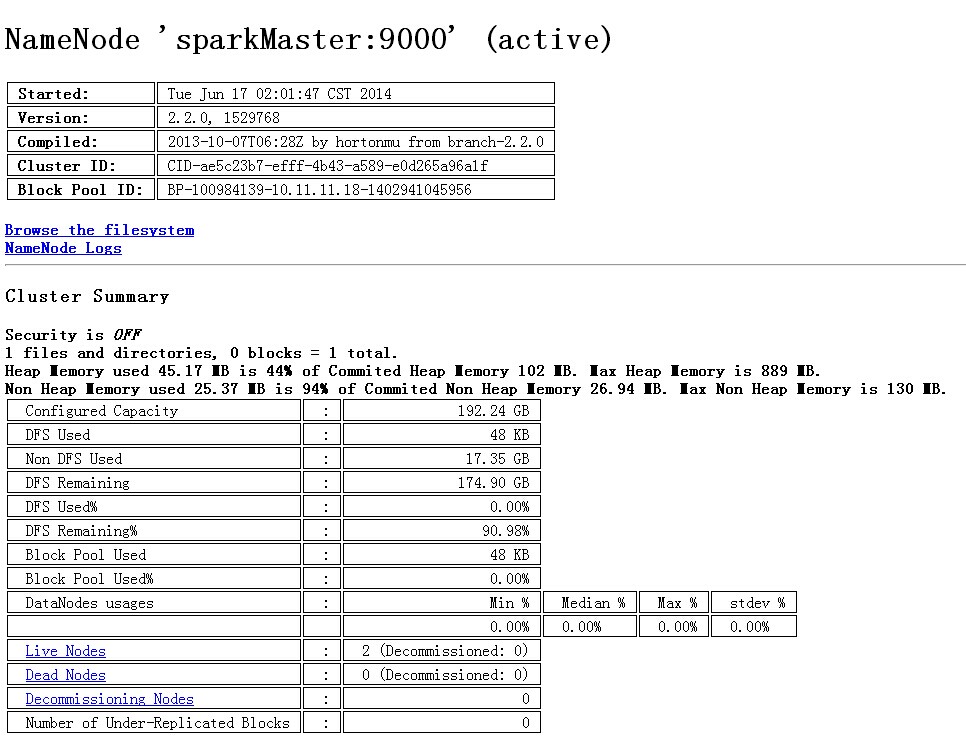
- 通过web页面查看hadoop资源管理
http://10.11.11.18:50070 namenode服务器端口(通过另一个地址http://192.168.150.106:50070也能访问)
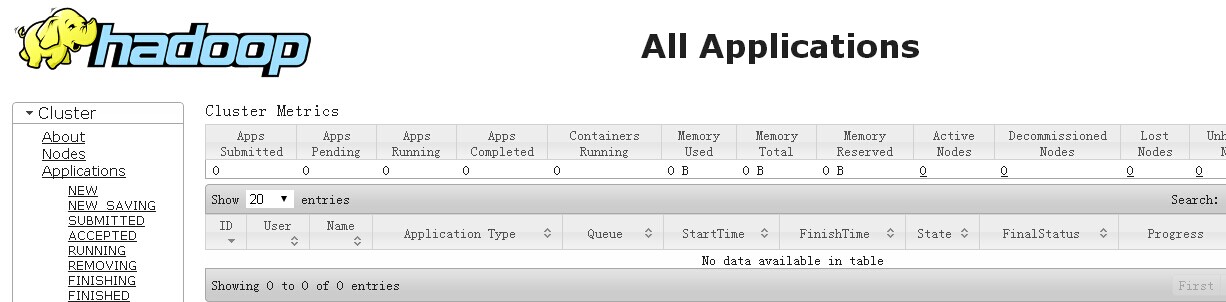
http://10.11.11.18:8088 nodemanager服务器端口(通过另一个地址http://192.168.150.106:8088也能访问)
- 运行wordcount单词计数案例测试
(1)准备测试文档
mkdir testHadoop
cd testHadoop
vi example01
This is word count example
using hadoop 2.2.0
using hadoop 2.2.0
(2)将该目录加入hadoop
./bin/hdfsdfs -copyFromLocal /opt/yarnDir/testHadoop /
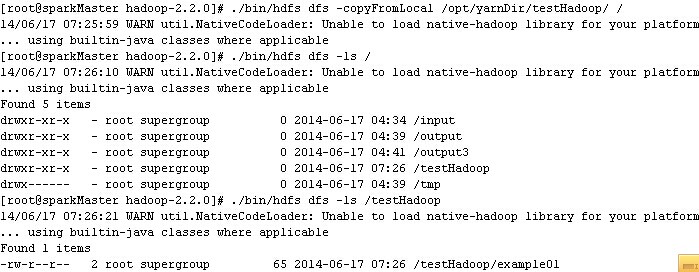
(3)运行wordcount案例
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jarwordcount /testHadoop /wordcount01
(部分信息)
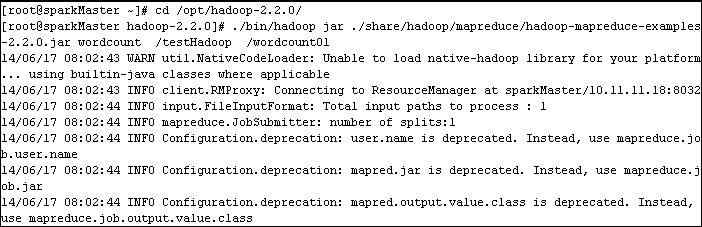
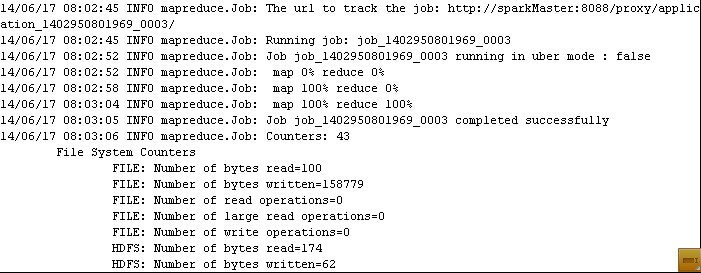
(4)检查输出
./bin/hadoop dfs -ls /wordcount01
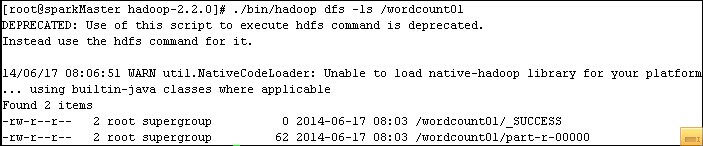
./bin/hadoop dfs -cat /wordcount01/part-r-00000 查看文件内容

如果重run,需要删除/output目录,否则会说目录已存在。
./bin/hdfs dfs -rm -r /wordcount01















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









