







1、基础环境准备
1.1、yum安装rz、sz命令(上传下载)
yum -y install lrzsz
1.2、集群分发脚本xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in h102 h103 h104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
1.3、集群日志生成脚本lg.sh
#!/bin/bash
for i in h102 h103; do
echo "========== $i =========="
ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-01-22.jar >/dev/null 2>&1 &"
done
1.4、多个服务器同步执行shell命令脚本
#! /bin/bash
for i in h102 h103 h104
do
echo --------- $i ----------
ssh $i "$*"
done
1.5、ssh无密登录配置
h102上生成公钥和私钥,在用户家目录.ssh路径下,执行
ssh-keygen -t rsa
将h102公钥拷贝到要免密登录的目标机器上
ssh-copy-id h102
ssh-copy-id h103
ssh-copy-id h104
h103和h104重复同样的操作
1.6、jdk准备
卸载现有的jdk
sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
将jdk安装包上传到服务器/opt/software/目录下,使用tar -zxvf解压
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
创建环境变量配置文件
vim /etc/profile.d/my_env.sh
添加如下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
让环境变量生效
source /etc/profile.d/my_env.sh
测试jdk是否安装成功
java -version
分发jdk
xsync /opt/module/jdk1.8.0_212/
分发环境变量配置文件
xsync /etc/profile.d/my_env.sh
在每台服务器上分别执行
source /etc/profile.d/my_env.sh
1.7、环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,/.bashrc,/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
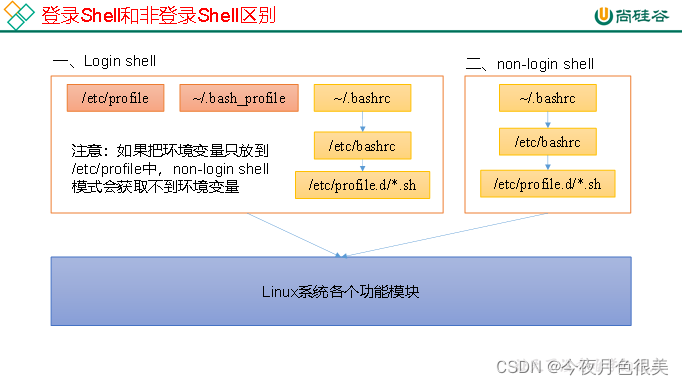
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,/.bash_profile,/.bashrc。non-login shell启动时会加载~/.bashrc。
而在加载/.bashrc(实际是/.bashrc中加载的/etc/bashrc)或/etc/profile时,都会执行如下代码片段,
for i in /etc/profile.d/*.sh; do
if [ -r "$i" ]; then
if [ "$PS1" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。
2、hadoop
2.1、hadoop安装配置
上传hadoop安装包到/opt/software/目录下,并解压到/opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
在/etc/profile.d/my_env.sh中添加hadoop环境变量
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
分发hadoop到所有服务器
xsync hadoop-3.1.3/
分发环境变量到所有服务器
xsync /etc/profile.d/my_env.sh
在所有服务器使环境变量生效
source /etc/profile.d/my_env.sh
2.2、配置集群
集群规划
| 服务器h102 | 服务器h103 | 服务器h104 | |
|---|---|---|---|
| HDFS | NameNodeDataNode | DataNode | DataNodeSecondaryNameNode |
| Yarn | NodeManager | Resourcemanager、NodeManager | NodeManager |
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://h102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.atguigu.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.atguigu.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.atguigu.users</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>h102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>h104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
配置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置workers
h102
h103
h104
注意:workers文件内容后面会读取作为主机名使用,所以不可以有空行和空格,否则会报错。
2.3、配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。
在mapred-site.xml文件里面增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>h102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>h102:19888</value>
</property>
2.4、配置日志的聚集
在yarn-site.xml文件里面增加如下配置:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://h102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
重新分发hadoop
xsync /opt/module/hadoop-3.1.3/
2.5、启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[root@h102 hadoop-3.1.3]$ bin/hdfs namenode -format
(2)启动HDFS
[root@h102 hadoop-3.1.3]$ sbin/start-dfs.sh
root用户启动报错:
Starting namenodes on [h102]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [h104]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
网上查询了一下,大概就是我们用root用户操作,没有在环境变量中定义变量。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
再次运行sbin/start-dfs.sh,启动成功。
(3)在配置了ResourceManager的节点(h103)启动YARN
[root@h103 hadoop-3.1.3]$ sbin/start-yarn.sh
(4)Web端查看HDFS的Web页面:http://h102:9870/
如果连接不上,检查本机hosts文件是否配置,阿里云安全组规则中是否添加了9870端口。
2.6、hadoop集群启停脚本
在/root/bin目录下创建脚本hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh h102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh h103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh h102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh h102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh h103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh h102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
2.7、支持LZO压缩配置
将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/,然后同步hadoop-lzo-0.4.20.jar到h103、h104
core-site.xml增加配置支持LZO压缩:
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
准备测试数据:
hadoop fs -mkdir /input
hadoop fs -put README.txt /input
测试压缩:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
2.8、LZO文件创建索引
创建索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
再次执行WordCount程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat /input /output2
发现输出的切片数变成了2
2022-04-05 18:28:46,353 INFO client.RMProxy: Connecting to ResourceManager at h103/172.22.32.218:8032
2022-04-05 18:28:46,898 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1649154366974_0002
2022-04-05 18:28:47,011 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-05 18:28:47,127 INFO input.FileInputFormat: Total input files to process : 2
2022-04-05 18:28:47,155 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-05 18:28:47,220 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-05 18:28:47,267 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-05 18:28:47,274 INFO mapreduce.JobSubmitter: number of splits:2
2022-04-05 18:28:47,417 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-05 18:28:47,838 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1649154366974_0002
2022-04-05 18:28:47,839 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-05 18:28:48,003 INFO conf.Configuration: resource-types.xml not found
2022-04-05 18:28:48,004 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-05 18:28:48,060 INFO impl.YarnClientImpl: Submitted application application_1649154366974_0002
2022-04-05 18:28:48,106 INFO mapreduce.Job: The url to track the job: http://h103:8088/proxy/application_1649154366974_0002/
2022-04-05 18:28:48,107 INFO mapreduce.Job: Running job: job_1649154366974_0002
2022-04-05 18:28:59,328 INFO mapreduce.Job: Job job_1649154366974_0002 running in uber mode : false
2022-04-05 18:28:59,329 INFO mapreduce.Job: map 0% reduce 0%
2022-04-05 18:29:17,147 INFO mapreduce.Job: map 33% reduce 0%
2022-04-05 18:29:23,402 INFO mapreduce.Job: map 54% reduce 0%
2022-04-05 18:29:27,730 INFO mapreduce.Job: map 72% reduce 0%
2022-04-05 18:29:28,736 INFO mapreduce.Job: map 81% reduce 0%
2022-04-05 18:29:34,883 INFO mapreduce.Job: map 83% reduce 0%
2022-04-05 18:29:36,899 INFO mapreduce.Job: map 100% reduce 0%
2022-04-05 18:29:41,932 INFO mapreduce.Job: map 100% reduce 100%
2022-04-05 18:29:42,948 INFO mapreduce.Job: Job job_1649154366974_0002 completed successfully
2022-04-05 18:29:43,054 INFO mapreduce.Job: Counters: 53














 2947
2947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









