







目录
前言
knn vs. svm
之前是knn实现分类,其基本原理是定义一个distance metric,用这个metric衡量test instance到所有train set 中的instance的距离,结果就是loss objective。
这儿的svm实质上是一样的。只不过,svm做了两个小的改变。一是,svm通过train set,学习到了属于每个class的template(具体方法后面说),因此在predict的时候,test instance不再需要与所有的train data比较,只要与一个template比较,这个template就是后面要说到的W ,W是一个weight matrix,它的每一行就相当于一个template。行数等于定义的class 数量。二是svm通过Wx这样的矩阵点乘代替了knn的L1或L2 distance。
svm & linear classifier
svm属于linear classifier。linear classifier:,其中的W叫做weights,b叫做bias vector或者叫parameters interchangeably。
linear classifier可以理解为将一系列的data映射到classes上。以图像分类为例,图像的像素个数理解为维数,那么每个图片在就是在这个高维空间里的一个点。但高维是不能可视化的,为了理解,用二维草图做一个类比,用来理解线性分类器的作用。
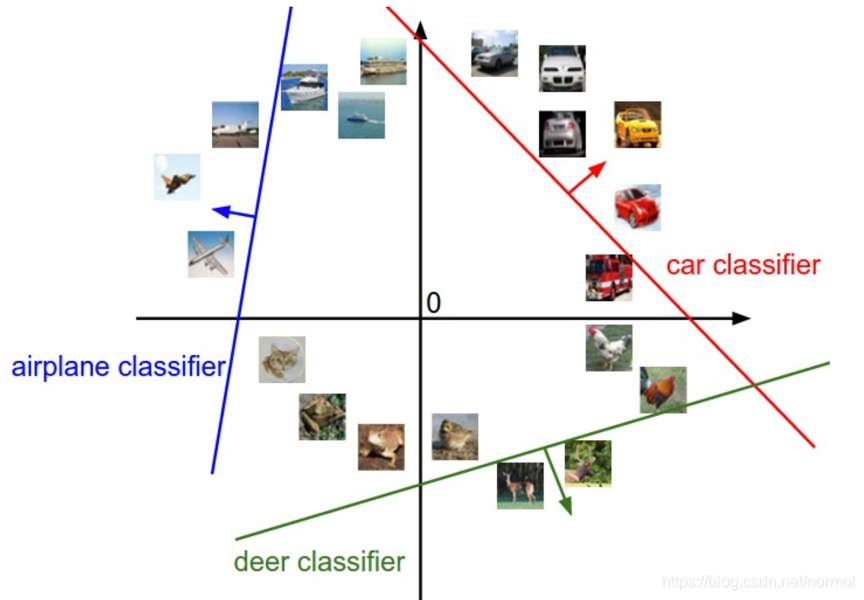
如上图所示,若图片恰好落在线上,证明其score等于0,离线越远,score的绝对值也就越大,箭头方向指向score的正增长方向。
bias trick
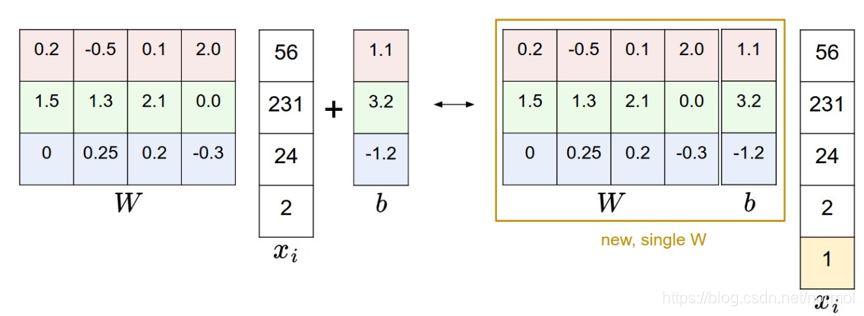
其中要解释下b,即bias。由线性公式或者图片可以知道,若没有b,那么所有的线都将经过原点,对于高维来说,就是只要W取全零,那么score一定得0,这显然是不对的,因此为了能使其偏移,就得加上b。在程序实现时,全都是矩阵操作,为了能统一,我们会对data进行预处理,即append 一个1,这样就可以以一个矩阵乘法实现Wx+b的操作,如下图所示。
loss function
wx+b的结果就是我们的outcome了,光有outcome显然没有用,在knn中,我们通过选取k 个outcome最高的nearest neighbors来vote出结果,这儿我们需要定义一个loss function,来衡量wx+b的结果与我们真正想要的结果相差多少。或者说这个结果损失了多少信息。
解释一下公式的含义,首先上述的x都是append 1之后的结果,因此不需要+b。
j代表第j个class,i代表第i个样品。计算的例子可以看这篇文章svm 损失函数以及其梯度推导,这儿在直观上理解一下,不考虑delta的话,就是对于一个样品而言,其预测出来的结果是一个score vector,每个元算的含义是这个样品在每个j-th class的得分。那么如果这个样品的真正分类是“car”,且这个分类器给出的这个样品在car上的得分是10,如果其余类别的得分低于10,根据max函数(常被叫做 hinge loss),损失为0,但如果在“cat”上的得分为12,自然就不对了,于是max会得量化差距为多少。delta在这儿的作用就是边界,我们预设定的参数,希望正确分类的分数与其他的分数相差多少,如下图所示

其实这个delta的取值对结果并没有影响,一般而言取1,原因在下面的regularization会说。
regularization
之所以需要这一步,是因为上面的loss function是有问题的。
比如,我们有一个分类器正确的进行了所有的分类,那么我们的L为0,但是,对W乘以任何常数,结果仍不会改变。
这样会有问题,例如W衡量出的关于某个样品cat种类得分为30,真正类别的得分为15,他们的差值为15,但若W变为2W,那么差值就变成了30.
于是我们提出了regularization function 。注意,这个不是关于输入data的函数,而是关于weights的。加上它的之后,不仅修复了之前提到的bug,还使得我们的模型更加general,例如,对于输入数据x=[1,1,1,1], w1=[0.25,0.25,0.25,0.25], w2=[1,0,0,0],虽然两个乘积结果一样,但w1的regularization loss要小于w2。根据公示可以知道,其更倾向于选择weight更小,更分散的。对应于实际,就是说不会在某一个像素上有很大的weight,而是比重更加均匀。这也避免的overfitting。
最后我们的loss function变成了:
setting Delta and lambda
上一个小节提到,delta的选取并不重要,就是因为有lambda缩放regualarization loss,这两个参数实质上做了相同的tradeoff。
若我们选择很大的margin,也就是delta很大,但我们的lambda则可以选的很小,因此上面说,delta的取值并不重要。
optimization
有了上述的评定标准,我们就可以选择w了,选择w的过程就是使loss function最小的过程。
具体是通过梯度实现的,这儿不再详述,可参考svm 损失函数以及其梯度推导
代码主体
导入数据及预处理
# Run some setup code for this notebook.
"""
进行一些设置
"""
import random
import numpy as np
from cs231n.data_utils import load_CIFAR10
import matplotlib.pyplot as plt
from __future__ import print_function
# This is a bit of magic to make matplotlib figures appear inline in the
# notebook rather than in a new window.
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# Some more magic so that the notebook will reload external python modules;
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
# Load the raw CIFAR-10 data.
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
# Cleaning up variables to prevent loading data multiple times (which may cause memory issue)
try:
del X_train, y_train
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# As a sanity check, we print out the size of the training and test data.
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(id 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5505
5505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









