







Meta character Description
| Character | Meaning |
|---|---|
| . | Period matches any single character except a line break. |
| [ ] | Character class. Matches any character contained between the square brackets. |
| [^] | Negated character class. Matches any character that is not contained between the square brackets |
| * | Matches 0 or more repetitions of the preceding symbol. |
| + | Matches 1 or more repetitions of the preceding symbol. |
| ? | Makes the preceding symbol optional. |
| {n,m} | Braces. Matches at least “n” but not more than “m” repetitions of the preceding symbol. |
| (xyz) | Captured group. Matches the characters xyz in that exact order.If you do not want to capture this group, use (?:xyz) |
| l | Alternation. Matches either the characters before or the characters after the symbol. |
| \ | Escapes the next character. This allows you to match reserved characters [ ] ( ) { } . * + ? ^ $ \ |
| ^ | Matches the beginning of the input. |
| $ | Matches the end of the input. |
| \d \D | \d matches a single digit 0-9, \D anything but a digit |
| \w \W | \w matches alphanumerical letters (0-9, a-z and _), \W anything but alphanumerical letters |
| \s \S | \s matches a space (such as \ ,\t, \n); \S matches anything but a space. |
| \n | Matches a linebreak |
Import regex packge
import re
text = '''
In the short term, the impact of the COVID-19 disease on China’s economic growth will be very obvious.
Since the outbreak, many domestic and foreign institutions have made their estimations (see Figure 1).
Most of them believe that the GDP growth rate in the first quarter may be about 4%, a decline by about 2 percentage points.
The growth rates in the next three quarters will gradually pick up depending on when the outbreak ends,
and the annual GDP growth will show a "V-shaped" pattern.
In light of the prevailing analyses and estimations of domestic and foreign institutions,
we believe that if the outbreak could be largely over in late March or early April,
the growth rates in the four quarters of this year may reach 4.5%...%, 5.0%, 5.8%, and 5.7% respectively.
The annual growth rate may be 5.2-5.3%.
'''
’’’ ‘’’: put string literal inside the triple quote sign. Let’s see what the text actually looks like in python codetext)
text

The simple match
term = 'COVID-19'
a = re.findall(term, text) # findall method return a list of all possible matches
a[0]

findall method return a list of all possible matches.
This search is not constrained by languages:
term = '中国'
b= re.search(term, "中国GDP增幅受到COVID-19影响,增量下降。中国的") # search method will go over all lines of text and report the first occurence
b, b.group()
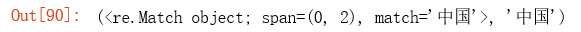
Search method will go over all lines of text and report the first occurence.
term = '美国'
b= re.match(term, "中国GDP增幅受到COVID-19影响,增量下降。中国的...") # match method will go over the first lines of text and report the first occurence
b # b.group() will return error since b is a None object
Match method will go over the first lines of text and report the first occurence.
c = re.sub('中国', '美国',"中国GDP增幅受到COVID-19影响,增量下降。中国的...") # sub can be used to substitute terms
c
Substitute terms
About the use of Backslash:
d = re.findall('\.\nI', text)
d
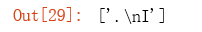
a = re.findall('\\', 'd\9reter')
print(a[0])
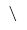
The full stop
The full stop . is the simplest example of a meta character. The meta character . matches any single character. It will not match return or newline characters. For example, the regular expression .ar means: any character, followed by the letter a, followed by the letter r.
term = 'th.'
b = re.findall(term, 'In the short term, the impact of the COVID-19 disease on China’s economic growth will be large')
b
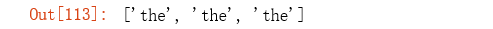
The Repetitions, Character Sets, and Captured Groups
re.findall(r'.*', 'In the short term, the impact of the COVID-19 disease on China’s economic growth will be very obvious.')

re.findall(r'o.?', 'In the short term, the impact of the COVID-19 disease on China’s economic growth will be very obvious.')
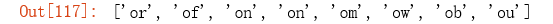
re.findall('on', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
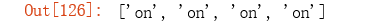
# match every word start with o
re.findall('\so.+\s', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
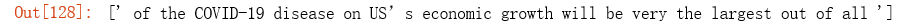
The above approach failed because + match is greedy, as it will try to find the longest match. In this case, our match needs to be lazy instead of greedy, so that it will stop as soon as it finds a possible match.
re.findall('\so.+?\s', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
It missed the first ‘on’ in ‘on the contrary’. This is because \s matches spaces only, not beginning or the end of the line. So instead of \s, we use \b to match word boundaries.
re.findall('\\bo.+?\\b', 'on the contrary, the impact \a of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
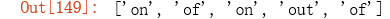
‘Why ‘\b’ instead of ‘\b’, because in Python string literals ‘\b’ corresponds to some special characters (’\x08’). So when you write ‘\bo.+?\b’, what the findall function get as an argument is ‘\x08 something here \x08’. Now you need to use ‘’ to escape the first ‘’ so that ‘\b’ actually means ‘\b’, instead of a special backspace character.’(转义字符)
An easier way: writing matched termed in raw strings
# adding a r before '' to convert a string literal into a raw string
re.findall(r'\bo.+?\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
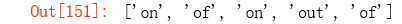
More about '?'
# ? can also mean match zero or one times
re.findall(r'\bo.?\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest out of all countries.')
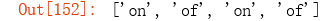
re.findall(r'\bone?\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
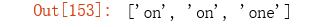
Other anchors include the beginning (^) and the end ($) of a string
re.findall(r'^on', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')

re.findall(r'\w*\.$', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
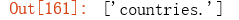
[], {} and ()
re.findall(r'[0-9]+', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
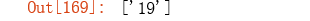
^ sign inside [] is not an anchor. Use [^] for the negated set.
re.findall(r'[^0-9]+', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
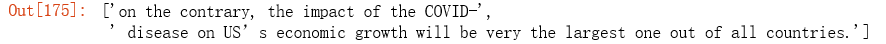
What if we only want to match ‘on’ or ‘of’:
# use () to capture groups
re.findall(r'\bo(n|f)\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
In the above example, we made the right match, but the () not only matches, but also captured the matched part into groups. So if we just want to match, not to capture. use (?: )
re.findall(r'\bo(?:n|f)\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
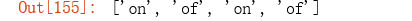
re.findall(r'\bo(?:n|f)|out\b', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
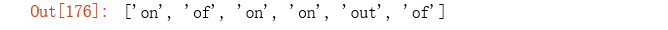
Carefully read the two following codes to see the difference and similarity.
re.findall(r'(on).*?(on)', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
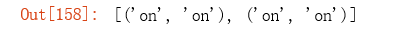
re.findall(r'(?:on).*?(?:on)', 'on the contrary, the impact of the COVID-19 disease on US’s economic growth will be very the largest one out of all countries.')
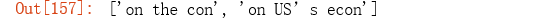
Put it all together
text

term1 = '\d%'
re.findall(term1, text) # not right
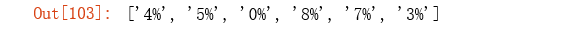
term2 = '[0-9.]%' # notice that . in the [] matches literal ., not full stop
re.findall(term2, text) # getting better, still not right
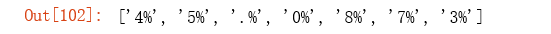
term3 = '[0-9.]+?%'# +? is lazy search, means it will stop at the first match, if just +, it will stop at the longest greedy match.
re.findall(term3, text)
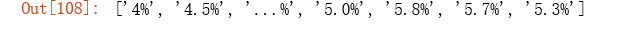
# get rid of the % sign, and not match ...%
term4 = r'([0-9][0-9.]*?)%'
re.findall(term4, text)
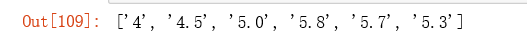
# or if you wish to use lookarounds, which matched a pattern that has to succeeded or preceded another given pattern (the send pattern is not captured).
# here we want to use the positive lookahead , which asserts that the first part of the expression must be followed by the lookahead expression.
term5 = r'[0-9][0-9.]*?(?=%)'
re.findall(term5, text)
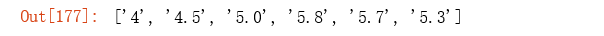
# if you want to find numbers that are not followed by the dollar sign, use negative look ahead
term6 = r'[0-9][0-9.]*(?!%|[0-9.])'
re.findall(term6, text)
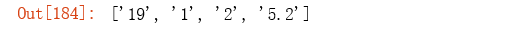
# you can also use positive/negative lookbehind to match a pattern that has to be preceded by another
term7 = r'(?<=\$)([0-9.]*)\.'
re.findall(term7, "this watermelon is $3.4. 3 times cheaper than that one.")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









