






从GAN的发展开始到GAN的基本理论再到GAN生成的评价方法最后到介绍流行的GAN方法。
一、GAN的基本介绍
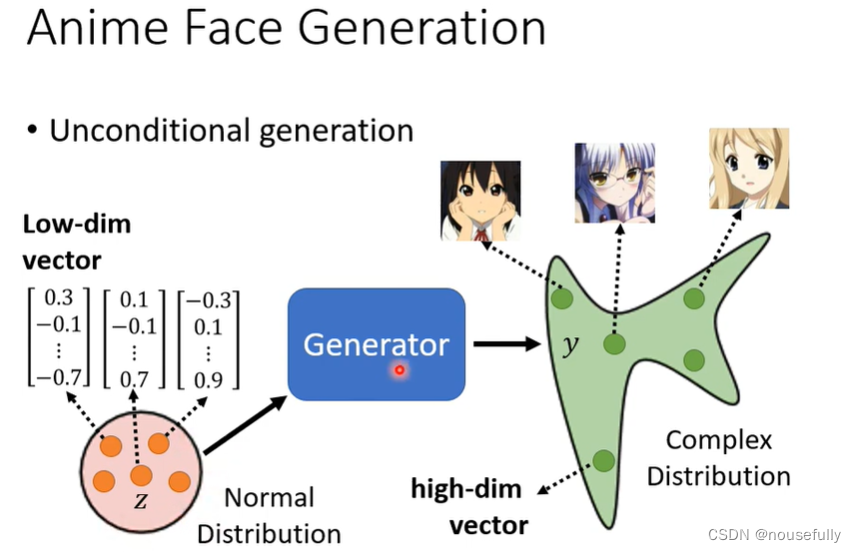
GAN的全名是Generative Adversarial Network生成对抗网络,其主要的目的是为了让训练机器让机器能够自主生成相对应类型的图片
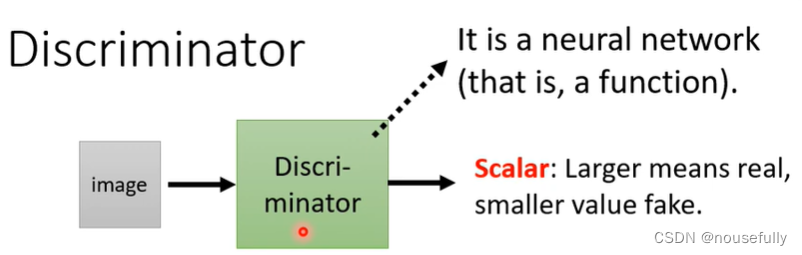
其中生成器generator就是GAN中进行生成相对应类似分布的网络,而鉴别器Discriminator就是判别生成器生成是否为真假的网络,鉴别器通过将输入的图像转换成一个判别值来判断真假,值越大,图像越真实,目前的GAN已经发展了许多的种类,有各式各样的GAN网络。
二、GAN的基本思想
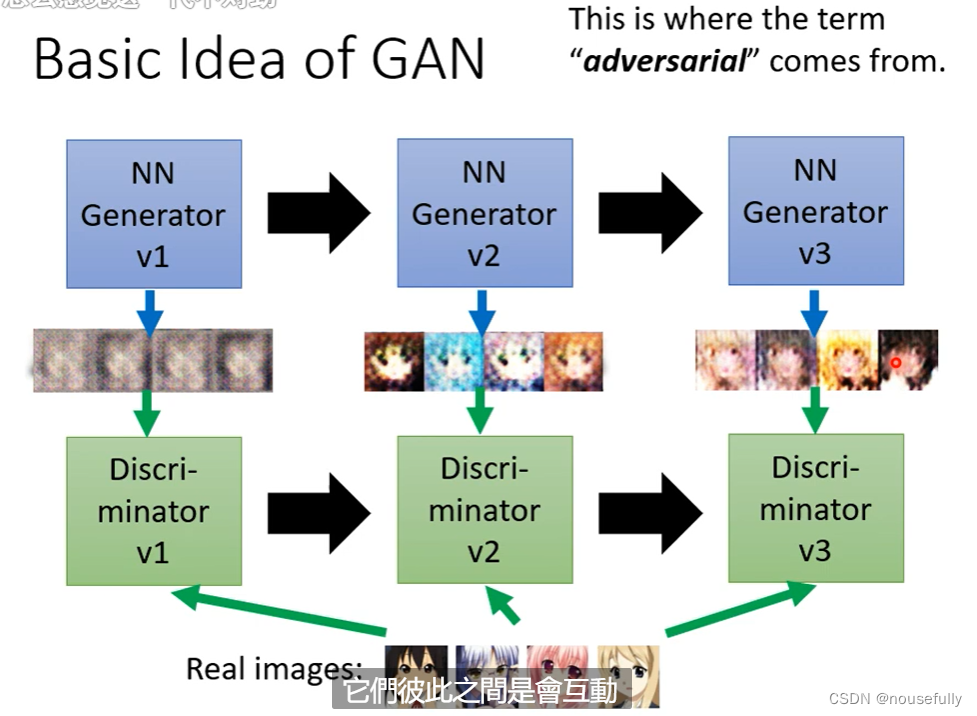
GAN的基本思想就是两个神经网络分别是generator和discriminator
其中生成器每次生成图像然后鉴别器会去判定判别生成器生成的图像 ,两者不断地生成判别相互对抗相互提升,到最后生成器生成的图像质量不断提升,判别器判别的能力也不断提升,这就是生成对抗式网络的基本思想,互相制约互相提高
三、GAN的算法流程
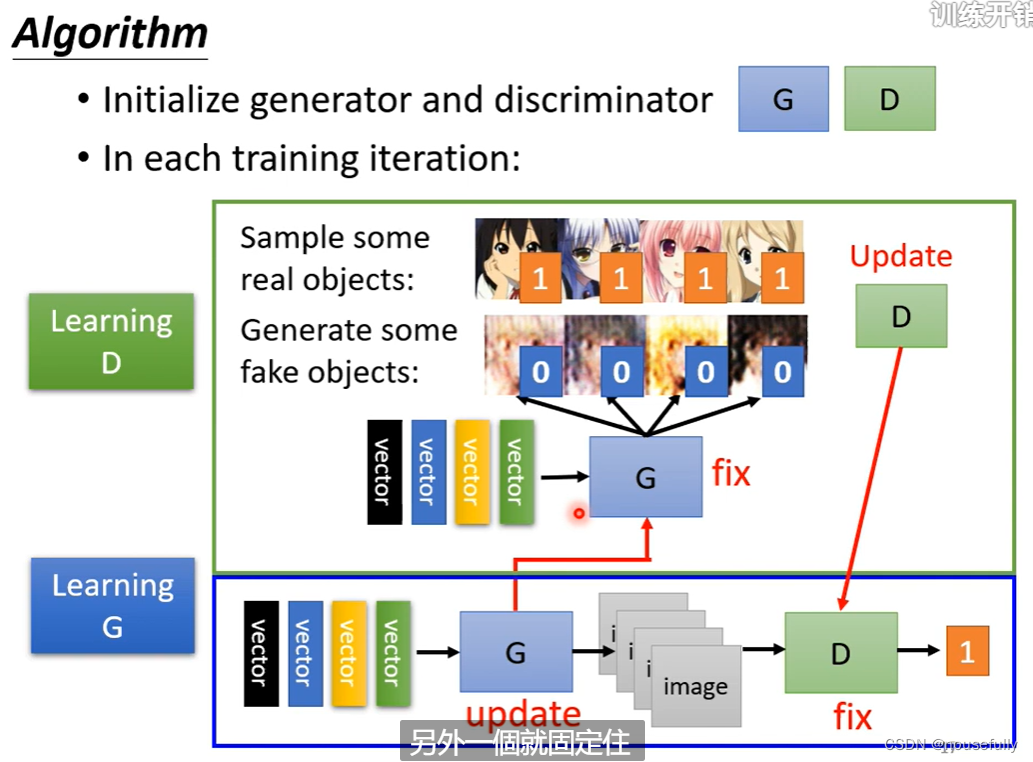
Step 1:初始化生成器和判别器的参数
Step 2:固定住生成器更新判别器,判别器给生成器的生成图像打低分给真实标签图像打高分
Step 3:固定住判别器更新生成器,生成器通过输入的随机采样的vector生成图像尝试骗过判别器使其让它打高分。
四、GAN的理论部分
1、GAN生成器的生成目标
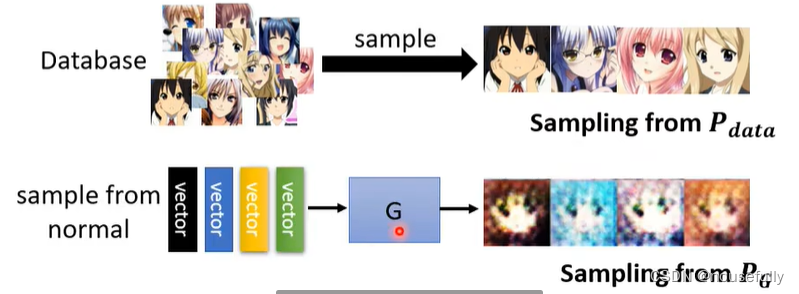
GAN中生成器的目标是:将输入的正态分布数据经过生成网络变成类似真实标签分布的数据,而为了让分布尽可能相似就必须最小化两个数据分布之间的距离
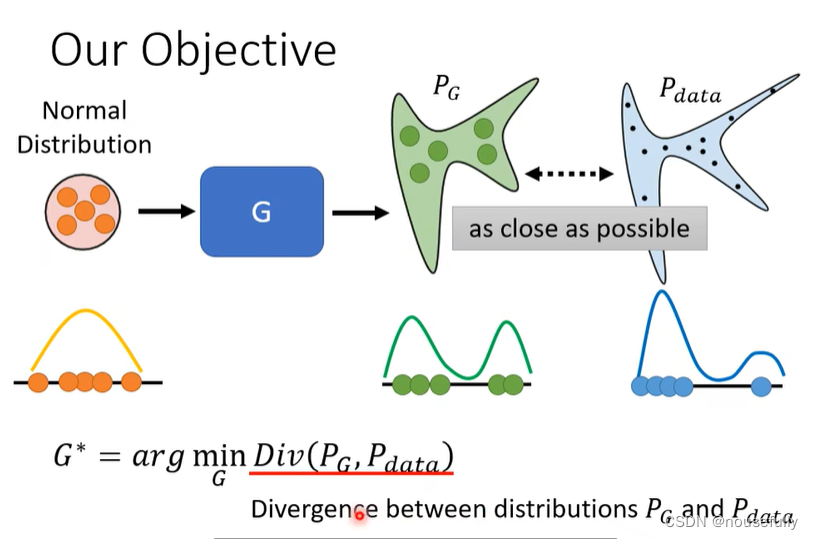
2、GAN中鉴别器的目标
既然生成器的目标是最小化生成数据和真实数据之间的距离那么鉴别器就是最大化两者的距离,针对如何计算生成数据和真实数据之间的距离,引入了JS散度的概念来计算,事实上也可以看成是交叉熵乘一个负号,如图所示:
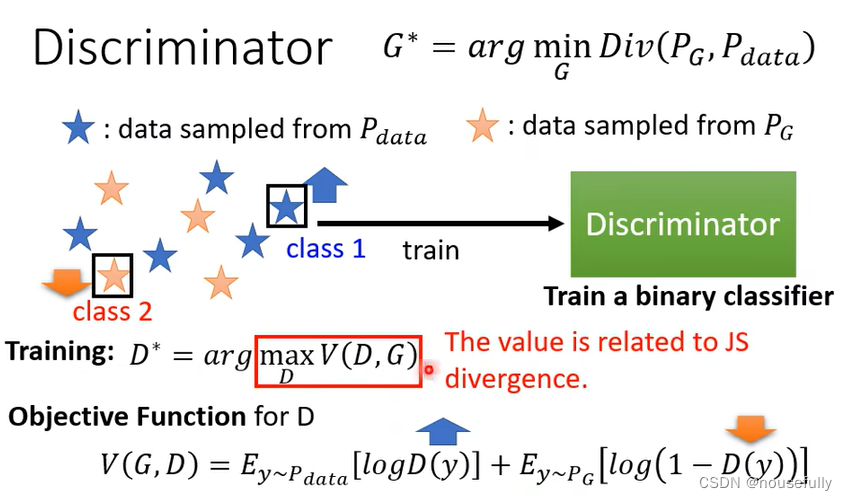 之前在计算网络输出和真实数据时往往都是一一对应的标签并且直接计算两者的L1或L2距离即可方便判断两个的差距,而在GAN中生成数据和真实数据往往不是一一对应,这就是JS divergence的巧妙之处,不需要知道生成数据和真实数据的具体形式,只需要通过鉴别器输出值和JS即可,当然不仅仅只有JS函数可以用还可以用其他很多的函数:
之前在计算网络输出和真实数据时往往都是一一对应的标签并且直接计算两者的L1或L2距离即可方便判断两个的差距,而在GAN中生成数据和真实数据往往不是一一对应,这就是JS divergence的巧妙之处,不需要知道生成数据和真实数据的具体形式,只需要通过鉴别器输出值和JS即可,当然不仅仅只有JS函数可以用还可以用其他很多的函数:


3、使用JS作为距离的缺点
使用JS divergence的很大缺点就是:如果生成数据和真实数据采样不够多,两者之间没有任何重叠部分没有交集,那么JS计算出来的距离将恒等于log2,这将会直接导致generator无法提高 ,两者如果没有重叠即假设让divergence处于最大时即判别器最理想的时候,那么这时候计算出来的就是log2
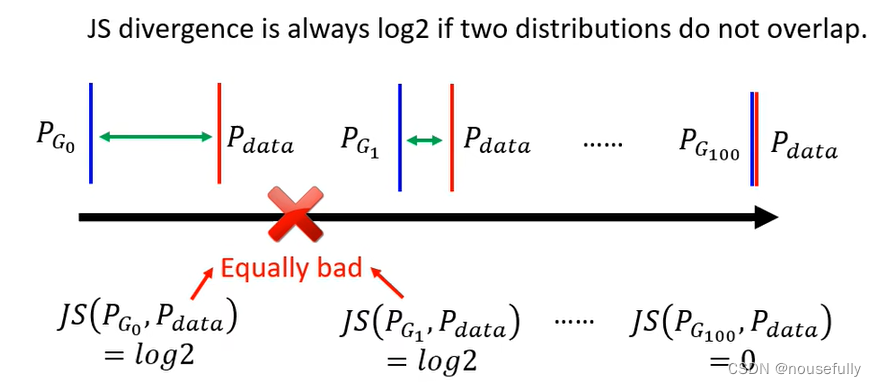
4、WGAN和推土机距离
推土机距离也称作Wasserstein distance,它最直观的好处就是当生成数据和真实数据无任何交集的时候它不会像JS一样处于恒等值的情况,如图所示,这就使得generator可以一直往好的方向去发展而不是直接停止
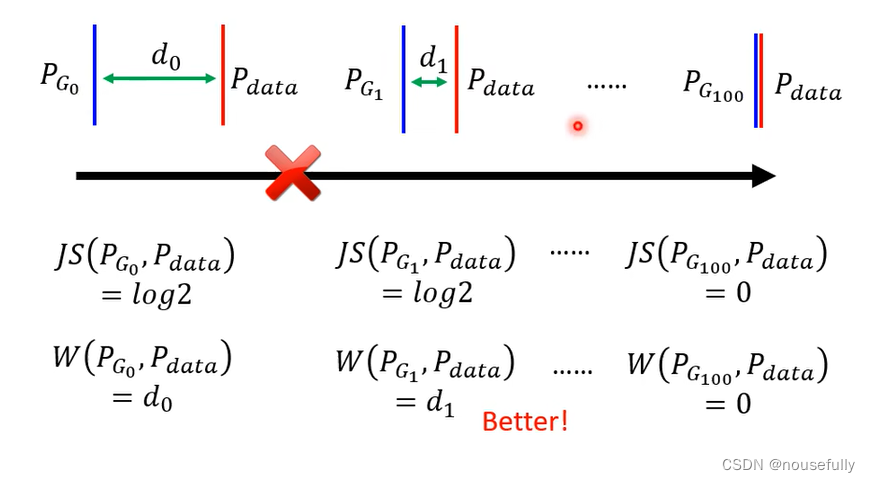
WGAN中使用的就是推土机距离代替了JS距离,如图所示即为WGAN中新的距离公式:

其中对于判别器,WGAN作出了限制即必须满足1-lipschitz的条件,该条件的目的是为了让生成数据和真实数据之间不会相差太大使得推算出来的推土机距离不会过大否则无任何意义,而WGAN中让判别器满足1-lipschitz的条件的方法其实相对较为简单如下图所示:

当然现在也有很多其他1-lipschitz的方法比如谱归一化Spectral Normalization就是很好的例子,其有效的让梯度在各个地方都小于1防止梯度消失。
5、条件GAN
条件GAN简单来说就是额外输入一段向量规定生成的图像需要包含什么特征,这就是条件GAN,其中额外输入的向量就是一段文字即将一段文字转换成vector输入generator和discriminator中 。

除此之外,还有输入影像生成影像,条件GAN还可以应用到语音中,即输入是一段语音让GAN根据语音生成想象到的画面图像
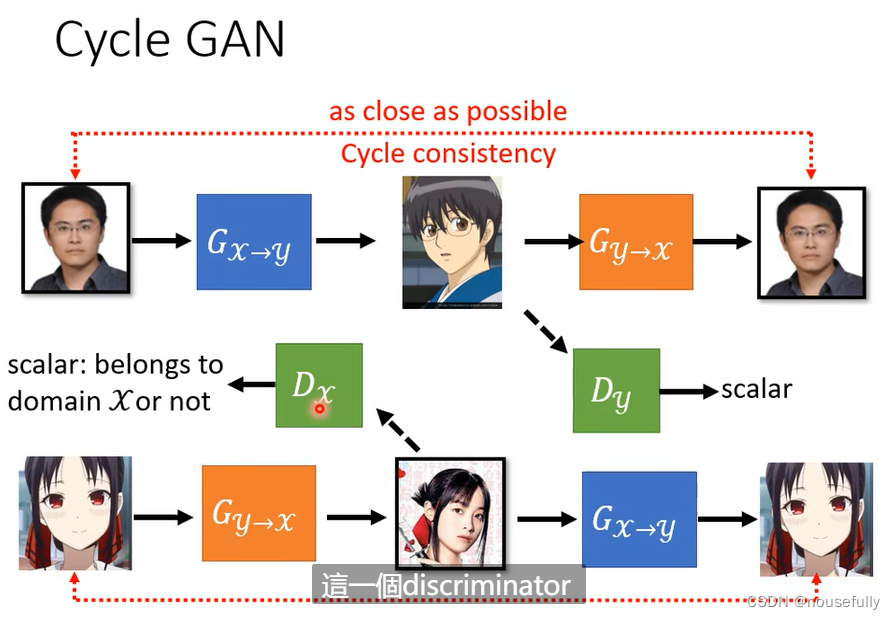
五、CycleGAN
CycleGAN是典型风格转化生成的GAN
其主题思想是:训练四个网络并形成一个Cycle输入一幅图像生成另一个风格图像再让生成图像生成回原来的图像风格,这样的一个形式就是CycleGAN的主要思想,事实上它在训练四个网络包括两个生成器和两个判别器
六、GAN的评价方法
GAN生成的图像如何进行评价,这里使用到让其他网络来识别生成图像来得到正确分类的分布这样的一个间接判别方法,典型的方法就是Inception Score (IS),通过判断分类的正确性来评价
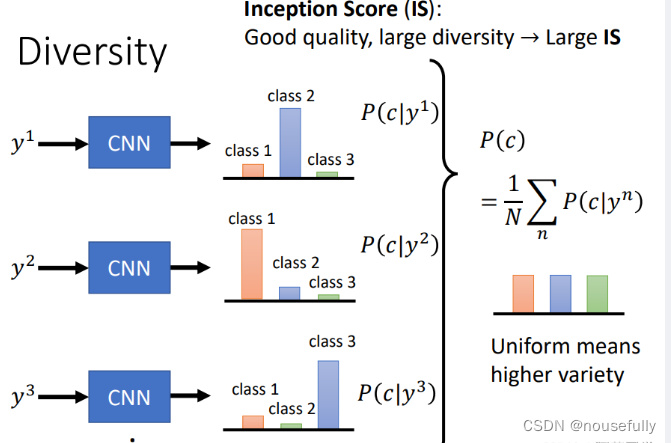
IS方法有很大的问题就是,它可以判断生成图像的正确类型但无法保证生成图像的多样性或者质量,比如生成图像如果都是同一个人的图像这样的正确性自然高,或者虽然多样性有但是在生成图像细节上没有得到保证,因此这都是潜在的问题,这就有了(FID)Fréchet Inception Distance,其主要的思想是通过最后输出分类的倒二层的特征来进行判别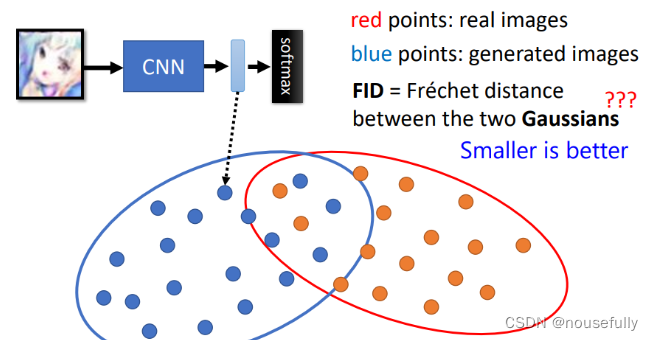















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









