







 本文深入解析了REINFORCE算法,一种基于策略梯度的强化学习方法。通过使用时序因果关系和引入Baseline来减少方差,提升算法的稳定性和效率。文章详细介绍了算法的工作原理,包括整体流程、奖励计算和梯度更新,并讨论了REINFORCE的局限性。
本文深入解析了REINFORCE算法,一种基于策略梯度的强化学习方法。通过使用时序因果关系和引入Baseline来减少方差,提升算法的稳定性和效率。文章详细介绍了算法的工作原理,包括整体流程、奖励计算和梯度更新,并讨论了REINFORCE的局限性。
在上篇文章强化学习——Policy Gradient 公式推导介绍了 Policy Gradient 的推导:
∇
θ
J
(
θ
)
≈
1
m
∑
i
=
1
m
R
(
τ
i
)
∑
t
=
0
T
−
1
∇
θ
l
o
g
π
θ
(
a
t
i
∣
s
t
i
)
\nabla_\theta J(\theta) \approx \frac{1}{m}\sum_{i=1}^mR(\tau_i)\;\sum_{t=0}^{T-1}\nabla_\theta\;log\;\pi_\theta(a_t^i|s_t^i)
∇θJ(θ)≈m1i=1∑mR(τi)t=0∑T−1∇θlogπθ(ati∣sti)
其中的 R ( τ i ) R(\tau_i) R(τi) 表示第 i 条轨迹所有的奖励之和。
对于这个式子,是基于 MC 采样的方法得来的。对于MC采样的轨迹是没有偏差的。但是因为是采样,所以每条轨迹获得的奖励非常不稳定,造成有比较高的方差。为了减少方差,这里有两个办法:1、使用时间因果关系(Use temporal causality)。2、引入 Baseline
一、减小方差
1、使用时序因果关系
Policy gradient estimator:
∇
θ
J
(
θ
)
≈
1
m
∑
i
=
1
m
(
∑
t
=
1
T
∇
θ
l
o
g
π
θ
(
a
t
i
∣
s
t
i
)
)
(
∑
t
=
1
T
r
(
s
t
i
,
a
t
i
)
)
\nabla_\theta J(\theta) \approx \frac{1}{m}\sum_{i=1}^m \left(\;\sum_{t=1}^{T}\nabla_\theta\;log\;\pi_\theta(a_t^i|s_t^i)\right)\left(\sum_{t=1}^Tr(s_t^i, a_t^i) \right)
∇θJ(θ)≈m1i=1∑m(t=1∑T∇θlogπθ(ati∣sti))(t=1∑Tr(sti,ati))
我们的目的是为了优化策略函数 π \pi π , π \pi π 有很多要优化的参数 θ \theta θ。那么在每一个点都计算 π \pi π 的 likelihood,而每个点能获得奖励是一个值,奖励的大小可以表示当前 likelihood的好坏,相当于对相应的 likelihood 进行了加权。我们希望优化过程中,策略尽可能进入到得到奖励多的区域中。
奖励值的大小可以作为判断当前策略好坏的依据。good action is made more likely, bad action is made less likely.
使用使用时序因果关系可以减少许多不必要的项
∇
θ
E
τ
[
R
]
=
E
τ
[
(
∑
t
=
0
T
−
1
r
t
)
(
∑
t
=
0
T
−
1
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
)
]
\nabla_\theta E_\tau[R] = E_\tau \left[\left(\sum_{t=0}^{T-1}r_t\right) \left( \sum_{t=0}^{T-1}\nabla_\theta\;log\;\pi_\theta(a_t|s_t)\right) \right]
∇θEτ[R]=Eτ[(t=0∑T−1rt)(t=0∑T−1∇θlogπθ(at∣st))]
对于一条轨迹中的某一点获得的奖励
r
t
′
r_{t'}
rt′ 可以表示为:
∇
θ
E
τ
[
r
t
′
]
=
E
τ
[
r
t
′
∑
t
=
0
t
′
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
]
\nabla_\theta E_\tau[r_{t'}] = E_\tau\left[r_{t'}\sum_{t=0}^{t'}\nabla_\theta\;log\;\pi_\theta(a_t|s_t)\right]
∇θEτ[rt′]=Eτ
rt′t=0∑t′∇θlogπθ(at∣st)
然后把一条轨迹上所有的点的导数加起来:
∇
θ
J
(
θ
)
=
∇
θ
E
τ
~
π
θ
[
R
]
=
E
τ
[
∑
t
′
=
0
T
−
1
r
t
′
∑
t
=
0
t
′
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
]
=
E
τ
[
∑
t
=
0
T
−
1
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
∑
t
′
=
t
T
−
1
r
t
′
]
=
E
τ
[
∑
t
=
0
T
−
1
G
t
⋅
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
]
\begin{aligned} \nabla_\theta J(\theta) = \nabla_\theta E_{\tau~\pi_\theta}[R] & = E_\tau \left[\sum_{t'=0}^{T-1}r_{t'} \sum_{t=0}^{t'}\nabla_\theta\;log\;\pi_\theta(a_t|s_t)\right] \\ & = E_\tau\left[\sum_{t=0}^{T-1}\nabla_\theta\;log\;\pi_\theta(a_t|s_t) \sum_{\color{red}t'=t}^{T-1}r_{t'} \right] \\ & = E_\tau \left[\sum_{t=0}^{T-1}G_t\cdot \nabla_\theta\;log\;\pi_\theta(a_t|s_t) \right] \end{aligned}
∇θJ(θ)=∇θEτ~πθ[R]=Eτ
t′=0∑T−1rt′t=0∑t′∇θlogπθ(at∣st)
=Eτ[t=0∑T−1∇θlogπθ(at∣st)t′=t∑T−1rt′]=Eτ[t=0∑T−1Gt⋅∇θlogπθ(at∣st)]
其中 G t = ∑ t ′ = t T − 1 r t ′ G_t = \sum_{t'=t}^{T-1}r_{t'} Gt=∑t′=tT−1rt′ 表示对于一条轨迹第 t 步往后获得的奖励之和。
如果上面式子难以理解,可以这样理解:我们都知道当前时刻不能影响过去所已经发生的事,这就是时间因果关系。同样,对于一条轨迹上,在时刻
t
′
t'
t′ 时的策略不能影响
t
′
t'
t′ 时刻之前所获得的奖励。所以只需要 对
t
′
t'
t′ 之后所有的奖励加起来即可,和
t
′
t'
t′ 时刻之前所获得的奖励是无关的。因此 Policy Gradient Estimator 可以表示为如下形式:
∇
θ
E
[
R
]
≈
1
m
∑
i
=
1
m
∑
t
=
0
T
−
1
G
t
⋅
∇
θ
l
o
g
π
θ
(
a
t
i
∣
s
t
i
)
\nabla_\theta E[R] \approx \frac{1}{m}\sum_{i=1}^m\sum_{t=0}^{T-1}G_t\cdot \nabla_\theta\;log\;\pi_\theta(a_t^i|s_t^i)
∇θE[R]≈m1i=1∑mt=0∑T−1Gt⋅∇θlogπθ(ati∣sti)
由上面的操作就得到了 Policy Gradient 中一个非常经典的算法 REINFORCE :
Williams (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning: introduces REINFORCE algorithm

2、加入 Baseline
对于一条采样出来的轨迹,它的的奖励
G
t
G_t
Gt 会有很高的方差,可以让
G
t
G_t
Gt 减去一个值(Baseline),这样就能减小方差,对于加入 Baseline 可以很容易的证明,会减小方差而不会改变整体的期望值,这样就会使得训练过程更加稳定。
∇
θ
E
τ
~
π
θ
[
R
]
=
E
τ
[
∑
t
=
0
T
−
1
(
G
t
−
b
(
s
t
)
)
⋅
∇
θ
l
o
g
π
θ
(
a
t
∣
s
t
)
]
\nabla_\theta E_{\tau~\pi_\theta}[R] = E_\tau \left[\sum_{t=0}^{T-1}{\color{red}(G_t-b(s_t))}\cdot \nabla_\theta\;log\;\pi_\theta(a_t|s_t) \right]
∇θEτ~πθ[R]=Eτ[t=0∑T−1(Gt−b(st))⋅∇θlogπθ(at∣st)]
一种办法是把奖励的期望
V
(
s
)
V(s)
V(s)作为Baseline,也就是让
G
t
G_t
Gt 减去它的平均值。
对于 Baseline 也可以用参数 来拟合,表示为
b
w
(
s
t
)
b_w(s_t)
bw(st) ,在优化过程中同时优化参数
w
w
w 和
θ
\theta
θ 。
二、REINFORCE 算法
实例代码使用CartPole-v1 离散环境,首先来看算法的整体流程。
1、整体流程
首先搭建好 policy 网络模型,初始化 参数 θ \theta θ ,然后用这个模型采样搜集数据,接着利用搜集到的数据来更新网络参数 θ \theta θ ,之后就有个一个新的策略网络,然后再用新的策略网络去和环境交互搜集新的数据,去更新策略网络,就这样重复下去,直到训练出一个良好的模型。注意每次搜集的数据只能使用一次,就要丢弃,因为每次更新 θ \theta θ 后策略网络就会改变,所以不能用旧的网络采集到的数据去更新新的网络参数。
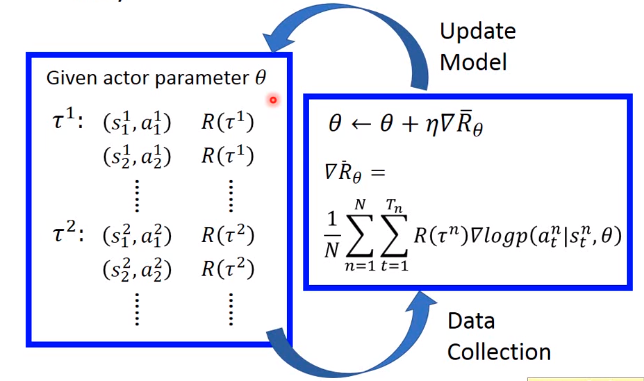
具体流程如下所示,在 与环境交互的过程中存储了每一步的相关数据,用以计算 G t G_t Gt 奖励。
for episode in range(TRAIN_EPISODES):
state = env.reset()
episode_reward = 0
for step in range(MAX_STEPS): # in one episode
if RENDER: env.render()
action = agent.get_action(state)
next_state, reward, done, _ = env.step(action)
agent.store_transition(state, action, reward)
state = next_state
episode_reward += reward
if done:break
agent.learn()
2、计算奖励
def _discount_and_norm_rewards(self):
# discount episode rewards
discounted_reward_buffer = np.zeros_like(self.reward_buffer)
running_add = 0
for t in reversed(range(0, len(self.reward_buffer))):
running_add = running_add * self.gamma + self.reward_buffer[t]
discounted_reward_buffer[t] = running_add
# normalize episode rewards
discounted_reward_buffer -= np.mean(discounted_reward_buffer)
discounted_reward_buffer /= np.std(discounted_reward_buffer)
return discounted_reward_buffer
函数分为两部分,一部分计算G值,一部分把G值进行归一化处理。这里计算的discounted_reward_buffer是每一步动作直到episode结束能获的奖励,也就是公式中的
G
t
G_t
Gt 。注意这里是从最后一个状态逆序 往前算,然后把每一步的奖励添加到列表中。然后对计算得到的奖励列表数据进行归一化,训练效果会更好。
3、梯度更新
利用每次搜集到的数据更新网络参数 θ \theta θ ,那么网络参数是如何更新的呢?
可以把它看做监督学习分类的过程,如下图所示,对于环境输入到 策略网络,最终网络输出为三个动作:左、右、开火。右边是 label。loss 函数就是输出动作与label之间的交叉熵,最小化的目标就是其交叉熵,然后跟新网络参数,增加哪个动作出现的概率或者减少哪个动作出现的概率。
H
=
−
∑
i
=
1
3
y
^
i
l
o
g
y
i
M
a
x
i
m
i
z
e
:
l
o
g
y
i
=
l
o
g
P
(
"
l
e
f
t
"
∣
s
)
H = - \sum_{i=1}^{3}\hat{y}_i log\;y_i \\ Maximize: log\;y_i = logP("left"|s) \\
H=−i=1∑3y^ilogyiMaximize:logyi=logP("left"∣s)
θ ← θ + η ∇ l o g P ( " l e f t " ∣ s ) \theta \leftarrow \theta + \eta\nabla logP("left"|s) θ←θ+η∇logP("left"∣s)
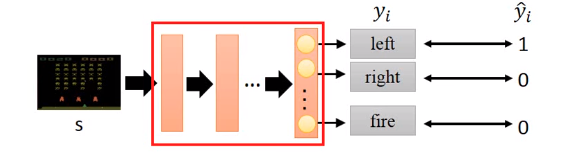
搜集到的每一步数据 state, action ,可以把 state 看做训练的数据,把 action 看做 label。然后最小化其交叉熵,如下代码 所示。在 REINFORCE 算法中,算出的交叉熵还要乘上
G
t
G_t
Gt 也就是 代码中的 discounted_reward ,也就是说 参数的更新根据
G
t
G_t
Gt 来调整的, 如果
G
t
G_t
Gt 比较高,那么就会大幅度增加相应动作出现概率,如果某一个动作得到的
G
t
G_t
Gt 是负数,那么就会相应的减少动作出现概率,这就是带权重的梯度下降。对于这个过程,tensorlayer 内置了一个函数 cross_entropy_reward_loss ,可以直接实现上述过程,见代码注释部分。
def learn(self):
discounted_reward = self._discount_and_norm_rewards()
with tf.GradientTape() as tape:
_logits = self.model(np.vstack(self.state_buffer))
neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=_logits, labels=np.array(self.action_buffer))
loss = tf.reduce_mean(neg_log_prob * discounted_reward)
# loss = tl.rein.cross_entropy_reward_loss(
# logits=_logits, actions=np.array(self.action_buffer), rewards=discounted_reward)
grad = tape.gradient(loss, self.model.trainable_weights)
self.optimizer.apply_gradients(zip(grad, self.model.trainable_weights))
对于这部分的理解可以直接看李宏毅老师的视频 ,讲解很清楚。关于 REINFORCE 的完整代码:REINFORCE 算法 ,希望能随手 给个 star,谢谢看官大人了。。。
三、REINFORCE 的不足
策略梯度为解决强化学习问题打开了一扇窗,但是上面的蒙特卡罗策略梯度reinforce算法却并不完美。由于使用MC采样获取数据,需要等到每一个episode结束才能做算法迭代,那么既然 MC 效率比较慢,那能不能用 TD 呢?当然是可以的,就是下篇要介绍的 Actor-Critic 算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









