







代码分析
导入数据
datafile = 'data/ex8_movies.mat'
mat = scipy.io.loadmat( datafile )
Y = mat['Y']
R = mat['R']
nm, nu = Y.shape
# Y is 1682x943 containing ratings (1-5) of 1682 movies on 943 users
# 0意味着这部电影没有评分
# R is 1682x943 containing R(i,j) = 1 if user j gave a rating to movie i
下面是Y和R,为参数矩阵,为0的点意味着未评分,我们的协同过滤算法就是用来预测这些评分
array([[5, 4, 0, ..., 5, 0, 0],
[3, 0, 0, ..., 0, 0, 5],
[4, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
array([[1, 1, 0, ..., 1, 0, 0],
[1, 0, 0, ..., 0, 0, 1],
[1, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)
我们可视化一下这个评分矩阵
#打印第一部电影的平均分
print('Average rating for movie 1 (Toy Story): %0.2f' % np.mean([ Y[0][x] for x in range(Y.shape[1]) if R[0][x] ]))
# 可视化评分矩阵
fig = plt.figure(figsize=(6,6*(1682./943.)))
dummy = plt.imshow(Y)
dummy = plt.colorbar()#加上颜色条
dummy = plt.ylabel('Movies (%d)'%nm,fontsize=20)
dummy = plt.xlabel('Users (%d)'%nu,fontsize=20)
Average rating for movie 1 (Toy Story): 3.88

接下来,我们实现协同过滤算法
下面两个函数负责处理参数矩阵
函数flattenParams将X,Theta矩阵展开为向量后连在一起
def flattenParams(myX, myTheta):
return np.concatenate((myX.flatten(),myTheta.flatten()))
函数reshapeParams将展开后的向量还原成X,Theta矩阵
def reshapeParams(flattened_XandTheta, mynm, mynu, mynf):
assert flattened_XandTheta.shape[0] == int(nm*nf+nu*nf)
reX = flattened_XandTheta[:int(mynm*mynf)].reshape((mynm,mynf))
reTheta = flattened_XandTheta[int(mynm*mynf):].reshape((mynu,mynf))
return reX, reTheta
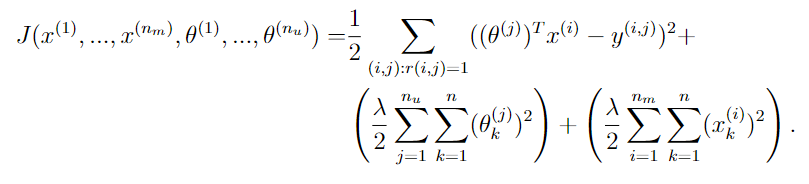
函数cofiCostFunc负责计算损失值
def cofiCostFunc(myparams, myY, myR, mynu, mynm, mynf, mylambda = 0.):
#向量还原为矩阵
myX, myTheta = reshapeParams(myparams, mynm, mynu, mynf)
#首先把θ和X点乘在一起,得到一个和Y(评分矩阵)形状相同的矩阵
term1 = myX.dot(myTheta.T)
#再将没有人评分过的电影记为0
term1 = np.multiply(term1,myR)
#计算损失函数
cost = 0.5 * np.sum( np.square(term1-myY) )
#添加正则化项
cost += (mylambda/2.) * np.sum(np.square(myTheta))
cost += (mylambda/2.) * np.sum(np.square(myX))
return cost
测试
#计算初始损失值
# "...run your cost function. You should expect to see an output of 22.22."
print('Cost with nu = 943, nm = 1682, nf = 10 is %0.2f.' % cofiCostFunc(flattenParams(X,Theta),Y,R,nu,nm,nf))
# "...with lambda = 1.5 you should expect to see an output of 31.34."
print('Cost with nu = 943, nm = 1682, nf = 10 (and lambda = 1.5) is %0.2f.' % cofiCostFunc(flattenParams(X,Theta),Y,R,nu,nm,nf,mylambda=1.5))
输出:
Cost with nu = 943, nm = 1682, nf = 10 is 27918.64.
Cost with nu = 943, nm = 1682, nf = 10 (and lambda = 1.5) is 34821.70.
下面编写梯度下降算法
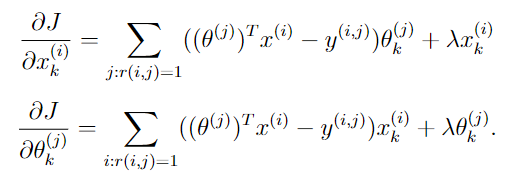
函数cofiGrad负责计算梯度,
def cofiGrad(myparams, myY, myR, mynu, mynm, mynf, mylambda = 0.):
#向量还原为矩阵
myX, myTheta = reshapeParams(myparams, mynm, mynu, mynf)
term1 = myX.dot(myTheta.T)
term1 = np.multiply(term1,myR)
term1 -= myY
#x的梯度
Xgrad = term1.dot(myTheta)
#θ的梯度
Thetagrad = term1.T.dot(myX)
# 正则化项
Xgrad += mylambda * myX
Thetagrad += mylambda * myTheta
return flattenParams(Xgrad, Thetagrad)
checkGradient是梯度检测函数,测试通过cofiGrad得到的梯度是否准确
def checkGradient(myparams, myY, myR, mynu, mynm, mynf, mylambda = 0.):
print('Numerical Gradient \t cofiGrad \t\t Difference')
myeps = 0.0001 # ε
nparams = len(myparams) #参数长度
epsvec = np.zeros(nparams)
#计算实际梯度
mygrads = cofiGrad(myparams,myY,myR,mynu,mynm,mynf,mylambda)
for i in range(10):
idx = np.random.randint(0,nparams)#随机一个特征
epsvec[idx] = myeps#创建这个特征的扰动向量
#计算扰动点的loss值,以计算导数
loss1 = cofiCostFunc(myparams-epsvec,myY,myR,mynu,mynm,mynf,mylambda)
loss2 = cofiCostFunc(myparams+epsvec,myY,myR,mynu,mynm,mynf,mylambda)
mygrad = (loss2 - loss1) / (2*myeps)
epsvec[idx] = 0#恢复
print('%0.15f \t %0.15f \t %0.15f' % (mygrad, mygrads[idx],mygrad - mygrads[idx]))
测试
print("Checking gradient with lambda = 0...")
checkGradient(flattenParams(X,Theta),Y,R,nu,nm,nf)
print("\nChecking gradient with lambda = 1.5...")
checkGradient(flattenParams(X,Theta),Y,R,nu,nm,nf,mylambda = 1.5)
输出
Checking gradient with lambda = 0...
Numerical Gradient cofiGrad Difference
1.051528470270569 1.051528481249694 -0.000000010979125
0.071457143349107 0.071457149090816 -0.000000005741709
-3.406713567528641 -3.406713587081239 0.000000019552598
-1.775068667484447 -1.775068664013151 -0.000000003471296
-5.987885288050165 -5.987885279779645 -0.000000008270520
-5.759588711953256 -5.759588718402049 0.000000006448793
-0.132317436509766 -0.132317424957221 -0.000000011552544
3.254412131354911 3.254412121371171 0.000000009983741
7.676124914723914 7.676124925811463 -0.000000011087549
-0.846849816298345 -0.846849794849549 -0.000000021448796
Checking gradient with lambda = 1.5...
Numerical Gradient cofiGrad Difference
0.736217552912422 0.736217503337186 0.000000049575235
0.177900474227499 0.177900478806763 -0.000000004579264
-2.740940544754267 -2.740940549416010 0.000000004661743
0.860549989738502 0.860549941121643 0.000000048616858
-1.492238661739975 -1.492238675155789 0.000000013415814
-0.652206981612835 -0.652206976658480 -0.000000004954355
0.329852628055960 0.329852637691616 -0.000000009635656
-0.154744629980996 -0.154744634761564 0.000000004780568
1.012410539260600 1.012410532326714 0.000000006933886
-2.433089466649108 -2.433089424103238 -0.000000042545869
可见我们的梯度下降算法执行正确
好了,完成协同过滤算法之后,我们可以开始着手编写推荐系统算法了
数据预处理
我打算添加一个我自己的评分列向量,用以预测我的电影推荐
#将电影装入列表movies
movies = []
#注意,有的电影名称含有法语等特殊字符,需要使用ISO-8859-1编码
with open('data/movie_ids.txt',encoding='ISO-8859-1') as f:
for line in f:
movies.append(' '.join(line.strip('\n').split(' ')[1:]))
#创建一个自己的评分向量
my_ratings = np.zeros((1682,1))
my_ratings[0] = 4
my_ratings[97] = 2
my_ratings[6] = 3
my_ratings[11] = 5
my_ratings[53] = 4
my_ratings[63] = 5
my_ratings[65] = 3
my_ratings[68] = 5
my_ratings[182] = 4
my_ratings[225] = 5
my_ratings[354] = 5
#添加了一列个人评分
myR_row = my_ratings > 0
Y = np.hstack((Y,my_ratings))
R = np.hstack((R,myR_row))
nm, nu = Y.shape
函数normalizeRatings是均值归一化函数,如果一个用户对所有的电影都未评分,那么原始状态是:协同过滤算法对于这个用户的电影评分预测也全是0。但是当对数据使用均值归一化之后,协同过滤算法对这个用户的电影评分预测就会为平均分
def normalizeRatings(myY, myR):
#所有电影各自的平均分
Ymean = np.sum(myY,axis=1)/np.sum(myR,axis=1)
Ymean = Ymean.reshape((Ymean.shape[0],1))
return myY-Ymean, Ymean
进行模型训练,得到预测后的参数
#得到了Ynorm(均值归一化后的评分矩阵),Ymean{(1682,1)均值向量}
Ynorm, Ymean = normalizeRatings(Y,R)
#随机创建参数矩阵
X = np.random.rand(nm,nf)
Theta = np.random.rand(nu,nf)
myflat = flattenParams(X, Theta)
#正则化参数
mylambda = 10.
# 训练模型
result = scipy.optimize.fmin_cg(cofiCostFunc, x0=myflat, fprime=cofiGrad, \
args=(Y,R,nu,nm,nf,mylambda), \
maxiter=50,disp=True,full_output=True)
输出:
Current function value: 73170.301029
Iterations: 50
Function evaluations: 72
Gradient evaluations: 72
进行电影推荐
#将参数向量转化为参数矩阵
resX, resTheta = reshapeParams(result[0], nm, nu, nf)
#得到我的预测评分
my_predictions = prediction_matrix[:,-1] + Ymean.flatten()
#根据我的预测评分进行排序,得到从小到大的indice
pred_idxs_sorted = np.argsort(my_predictions)
pred_idxs_sorted[:] = pred_idxs_sorted[::-1]
print("Top recommendations for you:")
for i in range(10):
print('Predicting rating %0.1f for movie %s.' % (my_predictions[pred_idxs_sorted[i]],movies[pred_idxs_sorted[i]]))
print("\nOriginal ratings provided:")
for i in range(len(my_ratings)):
if my_ratings[i] > 0:
print('Rated %d for movie %s.' % (my_ratings[i],movies[i]))
输出:
Top recommendations for you:
Predicting rating 8.5 for movie Star Wars (1977).
Predicting rating 8.3 for movie Titanic (1997).
Predicting rating 8.2 for movie Shawshank Redemption, The (1994).
Predicting rating 8.2 for movie Raiders of the Lost Ark (1981).
Predicting rating 8.1 for movie Schindler's List (1993).
Predicting rating 8.0 for movie Empire Strikes Back, The (1980).
Predicting rating 8.0 for movie Close Shave, A (1995).
Predicting rating 8.0 for movie Wrong Trousers, The (1993).
Predicting rating 8.0 for movie Casablanca (1942).
Predicting rating 8.0 for movie Good Will Hunting (1997).
Original ratings provided:
Rated 4 for movie Toy Story (1995).
Rated 3 for movie Twelve Monkeys (1995).
Rated 5 for movie Usual Suspects, The (1995).
Rated 4 for movie Outbreak (1995).
Rated 5 for movie Shawshank Redemption, The (1994).
Rated 3 for movie While You Were Sleeping (1995).
Rated 5 for movie Forrest Gump (1994).
Rated 2 for movie Silence of the Lambs, The (1991).
Rated 4 for movie Alien (1979).
Rated 5 for movie Die Hard 2 (1990).
Rated 5 for movie Sphere (1998).
数据集
ex8_movies.mat
ex8_movieParams.mat
以上两个数据可以上kaggle查,这里偷个懒
movie_ids.txt
1 Toy Story (1995)
2 GoldenEye (1995)
3 Four Rooms (1995)
4 Get Shorty (1995)
5 Copycat (1995)
6 Shanghai Triad (Yao a yao yao dao waipo qiao) (1995)
7 Twelve Monkeys (1995)
8 Babe (1995)
9 Dead Man Walking (1995)
10 Richard III (1995)
11 Seven (Se7en) (1995)
12 Usual Suspects, The (1995)
13 Mighty Aphrodite (1995)
14 Postino, Il (1994)
15 Mr. Holland's Opus (1995)
16 French Twist (Gazon maudit) (1995)
17 From Dusk Till Dawn (1996)
18 White Balloon, The (1995)
19 Antonia's Line (1995)
20 Angels and Insects (1995)
21 Muppet Treasure Island (1996)
22 Braveheart (1995)
23 Taxi Driver (1976)
24 Rumble in the Bronx (1995)
25 Birdcage, The (1996)
26 Brothers McMullen, The (1995)
27 Bad Boys (1995)
28 Apollo 13 (1995)
29 Batman Forever (1995)
30 Belle de jour (1967)
31 Crimson Tide (1995)
32 Crumb (1994)
33 Desperado (1995)
34 Doom Generation, The (1995)
35 Free Willy 2: The Adventure Home (1995)
36 Mad Love (1995)
37 Nadja (1994)
38 Net, The (1995)
39 Strange Days (1995)
40 To Wong Foo, Thanks for Everything! Julie Newmar (1995)
41 Billy Madison (1995)
42 Clerks (1994)
43 Disclosure (1994)
44 Dolores Claiborne (1994)
45 Eat Drink Man Woman (1994)
46 Exotica (1994)
47 Ed Wood (1994)
48 Hoop Dreams (1994)
49 I.Q. (1994)
50 Star Wars (1977)
51 Legends of the Fall (1994)
52 Madness of King George, The (1994)
53 Natural Born Killers (1994)
54 Outbreak (1995)
55 Professional, The (1994)
56 Pulp Fiction (1994)
57 Priest (1994)
58 Quiz Show (1994)
59 Three Colors: Red (1994)
60 Three Colors: Blue (1993)
61 Three Colors: White (1994)
62 Stargate (1994)
63 Santa Clause, The (1994)
64 Shawshank Redemption, The (1994)
65 What's Eating Gilbert Grape (1993)
66 While You Were Sleeping (1995)
67 Ace Ventura: Pet Detective (1994)
68 Crow, The (1994)
69 Forrest Gump (1994)
70 Four Weddings and a Funeral (1994)
71 Lion King, The (1994)
72 Mask, The (1994)
73 Maverick (1994)
74 Faster Pussycat! Kill! Kill! (1965)
75 Brother Minister: The Assassination of Malcolm X (1994)
76 Carlito's Way (1993)
77 Firm, The (1993)
78 Free Willy (1993)
79 Fugitive, The (1993)
80 Hot Shots! Part Deux (1993)
81 Hudsucker Proxy, The (1994)
82 Jurassic Park (1993)
83 Much Ado About Nothing (1993)
84 Robert A. Heinlein's The Puppet Masters (1994)
85 Ref, The (1994)
86 Remains of the Day, The (1993)
87 Searching for Bobby Fischer (1993)
88 Sleepless in Seattle (1993)
89 Blade Runner (1982)
90 So I Married an Axe Murderer (1993)
91 Nightmare Before Christmas, The (1993)
92 True Romance (1993)
93 Welcome to the Dollhouse (1995)
94 Home Alone (1990)
95 Aladdin (1992)
96 Terminator 2: Judgment Day (1991)
97 Dances with Wolves ( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 133
133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









