







Nagios搭建
1、Nagios安装-服务端(192.168.1.102)
安装epel扩展源:
yum install -y epel-release
安装nagios相关包:
yum install -y httpd nagios nagios-plugins nagios-plugins-all nrpe nagios-plugins-nrpe
设置nagios后台用户和密码:
htpasswd -c /etc/nagios/passwd nagiosadmin
vim /etc/nagios/nagios.cfg
nagios -v /etc/nagios.cfg
service httpd start
service nagios start
浏览器访问http://ip/nagios
2.Nagios安装-客户端(192.168.1.12)
在客户端机器上安装:
安装epel扩展源:
yum install -y epel-release
安装nagios相关包:
yum install -y nagios-plugins nagios-plugins-all nrpe nagios-plugins-nrpe
vim /etc/nagios/nrpe.cfg 找到"allowed_hosts=127.0.0.1"改为"allowed_hosts=192.168.1.102",后面的ip为服务端ip;找到"dont_blame_nrpe=0"改为"dont_blame_nrpe=1"
启动客户端/etc/init.d/nrpe start
3.监控中心(192.168.1.102)添加被监控主机(192.168.0.12)
cd /etc/nagios/conf.d/
vim 192.168.1.12.cfg 加入:
define host{
use linux-server
host_name 192.168.1.12
address 192.168.1.12
}
define service{
use generic-service ; Name of service template to use
host_name 192.168.1.12
service_description check_ping
check_command check_ping!100.0,20%!200.0,60%
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.1.12
service_description check_SSH
check_command check_ssh
max_check_attempts 5 ;当nagios检测问题时,一共尝试检测5次都有问题才会告警。
normal_check_interval 1 ;重新检测时间间隔,单位是分钟,默认是3
钟
notification_interval 60 ;在服务出现异常后,故障一直没有解决,nagios再次对使用者发出通知的时间。单位是分钟,如果所有事件只需要通知一次,可以设置为0;
}
define service{
use generic-service
host_name 192.168.1.12
service_description check_http
check_command check_http
max_check_attempts 5
normal_check_interval 1
}
重启nagios服务,刷新nagios页面:
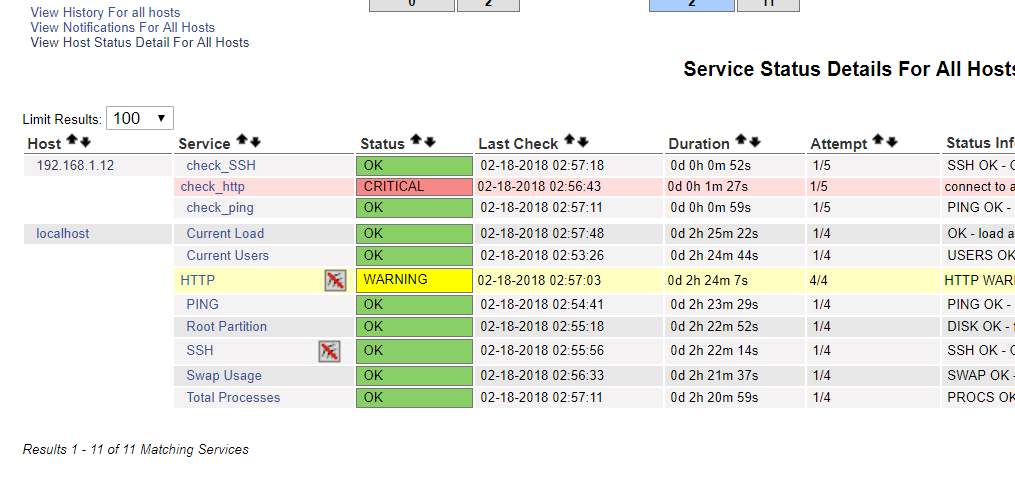
以上服务不依赖于客户端的nrpe服务,但当需要检测客户端上的某个具体服务的情况时,就需要借助于nrpe。
4、继续添加服务
服务端vim /etc/nagios/objects/commands.cfg
增加:
define command{
command_name check_nrpe
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}
继续编辑vim /etc/nagios/conf.d/192.168.1.12.cfg
增加如下内容:
define service{
use generic-service
host_name 192.168.1.12
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.1.12
service_description check_disk_hda1
check_command check_nrpe!check_hda1
max_check_attempts 5
normal_check_interval 1
}
define service{
use generic-service
host_name 192.168.1.12
service_description check_disk_hda2
check_command check_nrpe!check_hda2
max_check_attempts 5
normal_check_interval 1
}
说明:check_nrpe!check_load:这里的check_nrpe就是在commands.cfg刚刚定义的,check_load是远程主机上一个检测脚本
在远程主机上vim /etc/nagios/nrpe.cfg搜索check_load,这行就是在服务端上要执行的脚本了,我们可以手动执行这个脚本把check_hda1更改一下:/dev/hda1更改为/dev/sda1
再加上一行command[check_hda2]=/usr/lib/nagios/plugins/check_disk -w 20% -c 10% -p /dev/sda2
客户端重启一下:service nrpe restart
服务端重启一下:service nagios restart
(5)配置报警
vim /etc/nagios/objects/contacts.cfg //增加:
define contact{
contact_name 123
use generic-contact
alias expample
email expample@qq.com //可以写多个,用空格隔开即可
}
define contact{
contact_name 456
use generic-contact
alias expample2
email expample2@qq.com
}
define contactgruop{
contactgroup_name common
alias common
members 123,456 //将联系人加入组,方便以组为单位进行控制
}
定义完成后,在需要告警的服务里面加上contactgroup,举例:
define service{
use generic-service
host_name 192.168.1.12
service_description check_load
check_command check_nrpe!check_load
max_check_attempts 5
normal_check_interval 1
contact_groups common
notifications_enabled 1 //是否开启提醒功能,一般这个选项会在主配置文件(nagios.cfg)中定义,效果相同
notification_period 24x7 //发送提醒的时间段。非常重要的主机服务一般定义为7×24,一般的主机服务定义为上班时间,如果不在定义的时间段内,无论发生什么问题,都不会发送提醒
notification_options:w,u,c,r //定义在service的特定状态进行发送,w为warning,u为unknown,c为critical,r为recover,类似还有host也对应d,u,r ,d表示down,u表示UNREACHABLE,r为OK,需要加入到host的定义配置里面。
}
除了支持邮件,还可以调用短信和微信接口。
6、配置图形显示pnp4nagios
(1)安装
yum install pnp4nagios rrdtool
(2)配置主配置文件
vim /etc/nagios/nagios.cfg //修改如下配置
process_performance_data=1
host_perdata_command=process-host-perfdata
service_perfdata_command=process-service-perfdate
enables_environment_macros=1
(3)修改commands.cfg
vim /etc/nagios/objects/commands.cfg //注释掉原有对process-host-perfdata和process-service-perfdata,重新定义:
define command {
command_name process-service-perfdata
command_line /usr/bin/perl /usr/libexec/pnp4nagios/process_perfdata.pl
}
define command {
command_name process-host-perfdata
command_line /usr/bin/perl /usr/libexec/pnp4nagios/process_perfdata.pl -d HOSTPERFDATA
}
(4)修改配置文件templates.cfg
vim /etc/nagios/objects/templates.cfg
define host {
name hosts-pnp
register 0
action_url /pnp4nagios/index.php/graph?host=$HOSTNNAMEE$&SRV=_HOST_
process_perf_data 1
}
define service {
name srv-pnp
register 0
action_url /pnp4nagios/index.php/graph?host=$HOSTNAME$&srv=$SERVICEDESC$
process_perf_data 1
}
(5)修改host和service配置
vim /etc/nagios/conf.d/192.168.1.12.cfg
把 "define host {
use linux-server"
改为:
define host {
use linux-server,hosts-pnp
}
修改对应的service,比如
把
define service {
use generic-service
host_name 192.168.1.12
service_description check_disk_hda1
check_command check_nrpe!check_hda1
max_check_attempts 5
normal_check_interval 1
}
改为:
define service {
use generic-service,srv-pnp
host_name 192.168.1.12
service_description check_disk_hda1
check_command check_nrpe!check_hda1
max_check_attempts 5
normal_check_interval 1
}
(6)重启和启动各个服务:
service nagios restart
service httpd restart
service npcd start
(7)访问测试
两种访问方法:
ip/nagios/
ip/pnp4nagios/

















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









